Apache Flink Meetup: Sanjar Akhmedov - Joining Infinity – Windowless Stream Processing with Flink
2 likes•646 views

The document discusses a system for real-time stream processing using Flink to join data streams of scientific accounts and publications, highlighting challenges like fault tolerance and accurate joining of data from distributed sources. It outlines a prototype implementation that facilitates the integration of user accounts with their respective publications while addressing issues related to change data capture and data synchronization. The document emphasizes the importance of maintaining up-to-date and accurate join results in a scalable infrastructure supporting millions of publications.










![Hypothetical SQL
Publication
Authorship
1*
CREATE TABLE publications (
id SERIAL PRIMARY KEY,
author_ids INTEGER[]
);
Account
Claim
1 *
Author
CREATE TABLE accounts (
id SERIAL PRIMARY KEY,
claimed_author_ids INTEGER[]
);
CREATE MATERIALIZED VIEW account_publications
REFRESH FAST ON COMMIT
AS
SELECT
accounts.id AS account_id,
publications.id AS publication_id
FROM accounts
JOIN publications
ON ANY (accounts.claimed_author_ids) = ANY (publications.author_ids);](https://image.slidesharecdn.com/flink-meetup-windowless-join-170217162257/85/Apache-Flink-Meetup-Sanjar-Akhmedov-Joining-Infinity-Windowless-Stream-Processing-with-Flink-11-320.jpg)

























































Apache Flink Meetup: Sanjar Akhmedov - Joining Infinity – Windowless Stream Processing with Flink
- 1. Joining Infinity — Windowless Stream Processing with Flink Sanjar Akhmedov, Software Engineer, ResearchGate
- 2. It started when two researchers discovered first- hand that collaborating with a friend or colleague on the other side of the world was no easy task. There are many variations of passages of Lorem Ipsum ResearchGate is a social network for scientists.
- 3. Connect the world of science. Make research open to all.
- 4. Structured system There are many variations of passages of Lorem Ipsum We have, and are continuing to change how scientific knowledge is shared and discovered.
- 8. Diverse data sources Proxy Frontend Services memcache MongoDB Solr PostgreSQL Infinispan HBaseMongoDB Solr
- 9. Big data pipeline Change data capture Import Hadoop cluster Export
- 10. Data Model Account Publication Claim 1 * Author Authorship 1*
- 11. Hypothetical SQL Publication Authorship 1* CREATE TABLE publications ( id SERIAL PRIMARY KEY, author_ids INTEGER[] ); Account Claim 1 * Author CREATE TABLE accounts ( id SERIAL PRIMARY KEY, claimed_author_ids INTEGER[] ); CREATE MATERIALIZED VIEW account_publications REFRESH FAST ON COMMIT AS SELECT accounts.id AS account_id, publications.id AS publication_id FROM accounts JOIN publications ON ANY (accounts.claimed_author_ids) = ANY (publications.author_ids);
- 12. • Data sources are distributed across different DBs • Dataset doesn’t fit in memory on a single machine • Join process must be fault tolerant • Deploy changes fast • Up-to-date join result in near real-time • Join result must be accurate Challenges
- 13. Change data capture (CDC) User Microservice DB Request Write Cache Sync Solr/ES Sync HBase/HDFS Sync
- 14. Change data capture (CDC) User Microservice DB Request Write Log K2 1 K1 4 Extract
- 15. Change data capture (CDC) User Microservice DB Request Write Log K2 1 K1 4 K1 Ø Extract
- 16. Change data capture (CDC) User Microservice DB Request Write Log K2 1 K1 4 K1 Ø KN 42 … Extract
- 17. Change data capture (CDC) User Microservice DB Cache Request Write Log K2 1 K1 4 K1 Ø KN 42 … Extract Sync
- 18. Change data capture (CDC) User Microservice DB Cache Request Write Log K2 1 K1 4 K1 Ø KN 42 … Extract Sync HBase/HDFSSolr/ES
- 19. Join two CDC streams into one NoSQL1 SQL Kafka Kafka Flink Streaming Join Kafka NoSQL2
- 20. Flink job topology Accounts Stream Join(CoFlatMap) Account Publications Publications Stream … Author 2 Author 1 Author N
- 21. DataStream<Account> accounts = kafkaTopic("accounts"); DataStream<Publication> publications = kafkaTopic("publications"); DataStream<AccountPublication> result = accounts.connect(publications) .keyBy("claimedAuthorId", "publicationAuthorId") .flatMap(new RichCoFlatMapFunction<Account, Publication, AccountPublication>() { transient ValueState<String> authorAccount; transient ValueState<String> authorPublication; public void open(Configuration parameters) throws Exception { authorAccount = getRuntimeContext().getState(new ValueStateDescriptor<>("authorAccount", String.class, null)); authorPublication = getRuntimeContext().getState(new ValueStateDescriptor<>("authorPublication", String.class, null)); } public void flatMap1(Account account, Collector<AccountPublication> out) throws Exception { authorAccount.update(account.id); if (authorPublication.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } public void flatMap2(Publication publication, Collector<AccountPublication> out) throws Exception { authorPublication.update(publication.id); if (authorAccount.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } }); Prototype implementation
- 22. DataStream<Account> accounts = kafkaTopic("accounts"); DataStream<Publication> publications = kafkaTopic("publications"); DataStream<AccountPublication> result = accounts.connect(publications) .keyBy("claimedAuthorId", "publicationAuthorId") .flatMap(new RichCoFlatMapFunction<Account, Publication, AccountPublication>() { transient ValueState<String> authorAccount; transient ValueState<String> authorPublication; public void open(Configuration parameters) throws Exception { authorAccount = getRuntimeContext().getState(new ValueStateDescriptor<>("authorAccount", String.class, null)); authorPublication = getRuntimeContext().getState(new ValueStateDescriptor<>("authorPublication", String.class, null)); } public void flatMap1(Account account, Collector<AccountPublication> out) throws Exception { authorAccount.update(account.id); if (authorPublication.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } public void flatMap2(Publication publication, Collector<AccountPublication> out) throws Exception { authorPublication.update(publication.id); if (authorAccount.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } }); Prototype implementation
- 23. DataStream<Account> accounts = kafkaTopic("accounts"); DataStream<Publication> publications = kafkaTopic("publications"); DataStream<AccountPublication> result = accounts.connect(publications) .keyBy("claimedAuthorId", "publicationAuthorId") .flatMap(new RichCoFlatMapFunction<Account, Publication, AccountPublication>() { transient ValueState<String> authorAccount; transient ValueState<String> authorPublication; public void open(Configuration parameters) throws Exception { authorAccount = getRuntimeContext().getState(new ValueStateDescriptor<>("authorAccount", String.class, null)); authorPublication = getRuntimeContext().getState(new ValueStateDescriptor<>("authorPublication", String.class, null)); } public void flatMap1(Account account, Collector<AccountPublication> out) throws Exception { authorAccount.update(account.id); if (authorPublication.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } public void flatMap2(Publication publication, Collector<AccountPublication> out) throws Exception { authorPublication.update(publication.id); if (authorAccount.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } }); Prototype implementation
- 24. DataStream<Account> accounts = kafkaTopic("accounts"); DataStream<Publication> publications = kafkaTopic("publications"); DataStream<AccountPublication> result = accounts.connect(publications) .keyBy("claimedAuthorId", "publicationAuthorId") .flatMap(new RichCoFlatMapFunction<Account, Publication, AccountPublication>() { transient ValueState<String> authorAccount; transient ValueState<String> authorPublication; public void open(Configuration parameters) throws Exception { authorAccount = getRuntimeContext().getState(new ValueStateDescriptor<>("authorAccount", String.class, null)); authorPublication = getRuntimeContext().getState(new ValueStateDescriptor<>("authorPublication", String.class, null)); } public void flatMap1(Account account, Collector<AccountPublication> out) throws Exception { authorAccount.update(account.id); if (authorPublication.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } public void flatMap2(Publication publication, Collector<AccountPublication> out) throws Exception { authorPublication.update(publication.id); if (authorAccount.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } }); Prototype implementation
- 25. DataStream<Account> accounts = kafkaTopic("accounts"); DataStream<Publication> publications = kafkaTopic("publications"); DataStream<AccountPublication> result = accounts.connect(publications) .keyBy("claimedAuthorId", "publicationAuthorId") .flatMap(new RichCoFlatMapFunction<Account, Publication, AccountPublication>() { transient ValueState<String> authorAccount; transient ValueState<String> authorPublication; public void open(Configuration parameters) throws Exception { authorAccount = getRuntimeContext().getState(new ValueStateDescriptor<>("authorAccount", String.class, null)); authorPublication = getRuntimeContext().getState(new ValueStateDescriptor<>("authorPublication", String.class, null)); } public void flatMap1(Account account, Collector<AccountPublication> out) throws Exception { authorAccount.update(account.id); if (authorPublication.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } public void flatMap2(Publication publication, Collector<AccountPublication> out) throws Exception { authorPublication.update(publication.id); if (authorAccount.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } }); Prototype implementation
- 26. DataStream<Account> accounts = kafkaTopic("accounts"); DataStream<Publication> publications = kafkaTopic("publications"); DataStream<AccountPublication> result = accounts.connect(publications) .keyBy("claimedAuthorId", "publicationAuthorId") .flatMap(new RichCoFlatMapFunction<Account, Publication, AccountPublication>() { transient ValueState<String> authorAccount; transient ValueState<String> authorPublication; public void open(Configuration parameters) throws Exception { authorAccount = getRuntimeContext().getState(new ValueStateDescriptor<>("authorAccount", String.class, null)); authorPublication = getRuntimeContext().getState(new ValueStateDescriptor<>("authorPublication", String.class, null)); } public void flatMap1(Account account, Collector<AccountPublication> out) throws Exception { authorAccount.update(account.id); if (authorPublication.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } public void flatMap2(Publication publication, Collector<AccountPublication> out) throws Exception { authorPublication.update(publication.id); if (authorAccount.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } }); Prototype implementation
- 27. DataStream<Account> accounts = kafkaTopic("accounts"); DataStream<Publication> publications = kafkaTopic("publications"); DataStream<AccountPublication> result = accounts.connect(publications) .keyBy("claimedAuthorId", "publicationAuthorId") .flatMap(new RichCoFlatMapFunction<Account, Publication, AccountPublication>() { transient ValueState<String> authorAccount; transient ValueState<String> authorPublication; public void open(Configuration parameters) throws Exception { authorAccount = getRuntimeContext().getState(new ValueStateDescriptor<>("authorAccount", String.class, null)); authorPublication = getRuntimeContext().getState(new ValueStateDescriptor<>("authorPublication", String.class, null)); } public void flatMap1(Account account, Collector<AccountPublication> out) throws Exception { authorAccount.update(account.id); if (authorPublication.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } public void flatMap2(Publication publication, Collector<AccountPublication> out) throws Exception { authorPublication.update(publication.id); if (authorAccount.value() != null) { out.collect(new AccountPublication(authorAccount.value(), authorPublication.value())); } } }); Prototype implementation
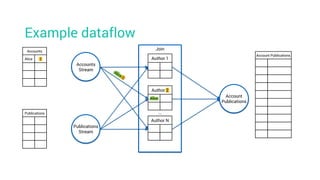
- 28. Example dataflow Account Publications Accounts Alice 2 Publications Accounts Stream Join Account Publications Publications Stream Author 1 Author 2 Author N …
- 29. Example dataflow Account Publications Accounts Alice 2 Publications Accounts Stream Join Account Publications Publications Stream Author 1 Author 2 Author N …
- 30. Example dataflow Account Publications Accounts Alice 2 Publications Accounts Stream Join Account Publications Publications Stream Author 1 Author 2 Alice Author N …
- 31. Example dataflow Account Publications Accounts Alice 2 Bob 1 Publications Accounts Stream Join Account Publications Publications Stream Author 1 Author 2 Alice Author N …
- 32. Example dataflow Account Publications Accounts Alice 2 Bob 1 Publications Accounts Stream Join Account Publications Publications Stream Author 1 Author 2 Alice Author N … (Bob, 1)
- 33. Example dataflow Account Publications Accounts Alice 2 Bob 1 Publications Accounts Stream Join Account Publications Publications Stream Author 1 Bob Author 2 Alice Author N … (Bob, 1)
- 34. Example dataflow Account Publications Accounts Alice 2 Bob 1 Publications Paper1 1 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Author 2 Alice Author N …
- 35. Example dataflow Account Publications Accounts Alice 2 Bob 1 Publications Paper1 1 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Author 2 Alice Author N …
- 36. Example dataflow Account Publications Accounts Alice 2 Bob 1 Publications Paper1 1 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 37. Example dataflow Account Publications Accounts Alice 2 Bob 1 Publications Paper1 1 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 38. Example dataflow Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 39. • ✔ Data sources are distributed across different DBs • ✔ Dataset doesn’t fit in memory on a single machine • ✔ Join process must be fault tolerant • ✔ Deploy changes fast • ✔ Up-to-date join result in near real-time • ? Join result must be accurate Challenges
- 40. Paper1 gets deleted Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 Ø Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 41. Paper1 gets deleted Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 Ø Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 42. Paper1 gets deleted Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 Ø Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N … ?
- 43. Paper1 gets deleted Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 Ø Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N … Need previous value
- 44. Paper1 gets deleted Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 Ø Accounts Stream Join Account Publications Diff with Previous State Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 45. Paper1 gets deleted Account Publications K1 (Bob, Paper1) K1 Ø Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 Ø Accounts Stream Join Account Publications Diff with Previous State Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 46. Paper1 gets deleted Account Publications K1 (Bob, Paper1) K1 Ø Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 Ø Accounts Stream Join Account Publications Diff with Previous State Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N … Need K1 here, e.g. K1 = 𝒇(Bob, Paper1)
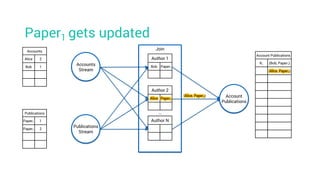
- 47. Paper1 gets updated Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 2 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 48. Paper1 gets updated Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 2 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Author N …
- 49. Paper1 gets updated Account Publications K1 (Bob, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 2 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Paper1 Author N …
- 50. Paper1 gets updated Account Publications K1 (Bob, Paper1) (Alice, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 2 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Paper1 Author N … (Alice, Paper1)
- 51. Paper1 gets updated Account Publications K1 (Bob, Paper1) ?? (Alice, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 2 Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Paper1 Author N …
- 52. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) Accounts Alice 2 Bob 1 Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Paper1 Author N …
- 53. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) Accounts Alice 2 Bob 1 Bob Ø Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Paper1 Author N …
- 54. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) Accounts Alice 2 Bob 1 Bob Ø Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Bob Paper1 Author 2 Alice Paper1 Author N …
- 55. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) K1 Ø Accounts Alice 2 Bob 1 Bob Ø Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Ø Paper1 Author 2 Alice Paper1 Author N …
- 56. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) K1 Ø Accounts Alice 2 Bob 1 Bob Ø Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Ø Paper1 Author 2 Alice Paper1 Author N …
- 57. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) K1 Ø Accounts Alice 2 Bob 1 Bob Ø Alice 1 Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Ø Paper1 Author 2 Alice Paper1 Author N …
- 58. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) K1 Ø Accounts Alice 2 Bob 1 Bob Ø Alice 1 Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Ø Paper1 Author 2 Alice Paper1 Author N … 2. (Alice, 1)
- 59. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) K1 Ø Accounts Alice 2 Bob 1 Bob Ø Alice 1 Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Alice Paper1 Author 2 Ø Paper1 Author N … 2. (Alice, 1)
- 60. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) K1 Ø Accounts Alice 2 Bob 1 Bob Ø Alice 1 Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Alice Paper1 Author 2 Ø Paper1 Author N … 2. (Alice, 1) (Alice, Paper1)
- 61. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) K1 Ø K2 (Alice, Paper1) K2 Ø Accounts Alice 2 Bob 1 Bob Ø Alice 1 Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Alice Paper1 Author 2 Ø Paper1 Author N … 2. (Alice, 1) (Alice, Paper1)
- 62. Alice claims Paper1 via different author Account Publications K1 (Bob, Paper1) K2 (Alice, Paper1) K1 Ø K3 (Alice, Paper1) K2 Ø Accounts Alice 2 Bob 1 Bob Ø Alice 1 Publications Paper1 1 Paper1 (1, 2) Accounts Stream Join Account Publications Publications Stream Author 1 Alice Paper1 Author 2 Ø Paper1 Author N … 2. (Alice, 1) (Alice, Paper1) Pick correct natural IDs e.g. K3 = 𝒇(Alice, Author1, Paper1)
- 63. • Keep previous element state to update previous join result • Stream elements are not domain entities but commands such as delete or upsert • Joined stream must have natural IDs to propagate deletes and updates How to solve deletes and updates
- 65. Generic join graph Operate on commands Account Publications Accounts Stream Publications Stream Diff Alice Bob … Diff Paper1 PaperN … Join Author1 AuthorM …
- 66. Memory requirements Account Publications Accounts Stream Publications Stream Diff Alice Bob … Diff Paper1 PaperN … Join Author1 AuthorM … Full copy of Accounts stream Full copy of Publications stream Full copy of Accounts stream on left side Full copy of Publications stream on right side
- 68. • In addition to handling Kafka traffic we need to reshuffle all data twice over the network • We need to keep two full copies of each joined stream in memory Resource considerations
- 69. Questions We are hiring - www.researchgate.net/careers