Apache Hudi: The Path Forward
0 likes•783 views

Apache Hudi is a serverless transactional layer designed for data lakes that supports both streaming and batch pipelines, enabling efficient data processing. It features components for table metadata management, indexing, and concurrency control, while ensuring scalability on Hadoop-compatible storage systems. The platform has an active community contributing to ongoing improvements and new features such as indexing, schema evolution, and integration with various data processing engines.































Apache Hudi: The Path Forward
- 1. Apache Hudi: The Path Forward Vinoth Chandar, Raymond Xu PMC, Apache Hudi
- 2. Agenda 1) Hudi Intro 2) Table Metadata 3) Caching 4) Community
- 5. Hudi - the Pioneer Serverless, transactional layer over lakes. Multi-engine, Decoupled storage from engine/compute Introduced notions of Copy-On-Write and Merge-on-Read Change capture on lakes Ideas now heavily borrowed outside.
- 6. The Hudi Stack Lakes on cheap, scalable Hadoop compatible storage Built on open file and data formats Transactional Database Kernel - Table Format for file layouts, schema, … - Indexing for faster updates/deletes - Built-in “daemons” aka table services - MVCC, OCC Concurrency Control SQL and Programming APIs Platform services and operational tools Universally queryable from popular engines
- 7. It’s a platform! Both streaming + batch style pipelines - State store for incremental merging intermediate results - Change events like Apache Kafka topics For data lake workloads - Optimized, self-managing data plane - Large scale data processing - Lakehouse? With tightly-integrated components - Loose coupling => too many to integrate - Reduce build out time for data lakes http://hudi.apache.org/blog/2021/07/21/streaming-data-lake-platform
- 8. Table Format Avro Schema, Evolution rules File groups, reduce merge overhead Timeline => event log, WAL Internal metadata table Ongoing - Schema-on-read i.e drop,renames (RFC-33) - Infinite retention
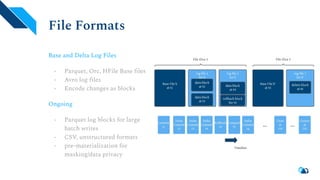
- 9. File Formats Base and Delta Log Files - Parquet, Orc, HFile Base files - Avro log files - Encode changes as blocks Ongoing - Parquet log blocks for large batch writes - CSV, unstructured formats - pre-materialization for masking/data privacy
- 10. Indexes Pluggable, Consistent with txns For upserts, deletes - HBase, External index -> pluggable - Simple, Bloom/Local vs Global Ongoing - RFC-27 Range indexes - Bucketed Index - DynamoDB index - Metadata index - Record level indexing
- 11. Concurrency Control Hudi did not need multi-writer support - Treat writers and services differently - MVCC, non-blocking - Table services satisfy most needs Hudi now does Optimistic Concurrency Control - File level, timeline consistent - Still MVCC for table services Future/Ongoing - Multi-table transactions - MVCC, fully lock free transactions
- 12. Writers Incremental & Batch write operations - File sizing, Layout control upon write - Sorting, compression, Index maintenance - Spill handling, Multi-threaded write pipeline Record level merges APIs - Unique keys, composite, - key generators, virtual or physical - partial merges, event-time processing Record level metadata - Arrival and event time, watermarks - Encode source CDC operation
- 13. Readers Hive, Impala, Presto, Spark, Trino, Redshift Use engine’s native readers First class support for incremental queries Flexibility - snapshot vs read-optimized Future - Flexible change stream data models. - Snowflake/BigQuery external tables
- 14. Table Services Self managing database runtime Table services know each other - E.g avoid duplicate schedules - E.g skip compacting files being clustered Cleaning (committed/uncommitted), archival, clustering, compaction, .. Services can be run continuously or scheduled
- 15. Platform Services DeltaStreamer/FlinkStreamer ingest/ETL utility Deliver Commit notifications Kafka Connect Sink Data Quality checkers Snapshot, Restore, Export, Import
- 16. Table Metadata Current choices, Ongoing work, Future plans
- 17. What qualifies as table metadata? Schema - Columns names/types, keys, partitioning, evolution/versions - Typically small, < 1MB per version. Files/Objects - Length, paths, URIs - 2M objects => 10s of MBs Stats - Min, Max, Nulls etc, Per col Per file - 2M objects => 100+ of MBs Redo Logs - Changes to metadata => writes, rollbacks, table optimizations. - Committing (200kb) every minute for a year => ~100 GB Indexes? - Remember Stats != Index, They can be much bigger.
- 18. How’s this stored in Hudi, today? Schema - Stored within the redo log, consistent with table changes. - Synced out to different meta-stores, post commit Files/Objects - Obtained from an internal metadata table partition `files` - Or just by listing storage - sometimes it’s faster! Redo Logs - As an event log in the timeline folder “.hoodie” - Archived out, once transactions/table operations complete/expire. Stats - We don’t. Yet. Fetch from file footers. - Again sometimes faster if parallelized, even on cloud storage.
- 19. RFC-27 (Ongoing): Flat Files are not cool Scaling file stats for high scale writing - 65536 files (1TB data, stored as 16MB small files) - 100 columns, 6.5M stat entries - O(total_cols_tracked_in_table) - Slow, 10s of seconds. Range reads to the rescue! - O(num_cols_in_query) performace - Interval trees with smart skipping
- 20. The Hudi Timeline server Metadata need efficient serving, caching - Not just efficient storage Responsibilities - Cache file listings across executors - Amortize access to metadata table - Performant uncommitted file cleanup Incremental sync - Streaming/continuous writes - Lazy refreshing of timeline S3 Baseline: listing p90 - 1sec (10k files), - 10 sec (100K files) Timeline Server: 1-10 ms! File-backed metadata: ~1 second!
- 21. Extending the Timeline Server New APIs - Serve also stats, redo log information. - Locking APIs Let’s make a cluster! - Shard servers by table/db - Pluggable backing storage - Local DB w/ recovery/checkpointing - Remote DB with newSQL/transactional storage
- 22. Cache Basic Idea, Design Considerations
- 23. Basic Idea Problems - Frequent commits => small objects / blocks => I/O costly - File System / Block level caching not very effective base file b @ t1 base file b’ @ t2 log file 1 for b log file 2 for b log file 1 for b’ log file 2 for b’ Time Hudi FileGroup log file 3 for b’ Hudi FileGroup fits caching - Smallest unit to compact - Size properly to fit cache store - Cache compacted data for real-time views => save computation
- 24. Design Considerations Refresh-Ahead - Works with Change-Data-Capture scenario - Micro-compact FileGroup and save in cache Cache base file b log file 1 for b log file 2 for b compacted Change-Data-Capture Refresh-Ahead Read-Through - Driven by usage, on-demand computation - LRU or LFU Query I/O Read-Through
- 25. Design Considerations FileGroup consistent hashing - Each FileGroup has a unique ID - Work with distributed cache servers Cache Node A FileGroup Query I/O Cache Node B FileGroup FileGroup Coordinator (Timeline server?) Query I/O Lake Storage Cache (e.g. Alluxio) Transactionality - Only committed files can be cached - Rollback include cache invalidation Pluggable Caching Layer - Define APIs for pluggable caching implementations
- 26. Community Adoption, Operating the Apache way, Ongoing work
- 27. How we roll? Friendly and diverse community - Open and Collaborative - 20+ PMCs/Committers from 10+ organizations Developers - Propose new RFCs (design docs) - Dev list discussions, JIRA for issue tracking. Users - Weekly community on-call rotations - Issue triage, bug filing process on Github 1200+ Slack 200+ Contributors 1000+ GH Engagers ~10-20 PRs/week 20+ Committers 10+ PMCs
- 28. Major Ongoing Works RFC-26: Z-order indexing, Hilbert curves (PR #3330) RFC-27: Data skipping/Range indexing (PR #3475) RFC-29: Hashed Indexing (PR #3173) RFC-32: Kafka Connect Sink for Hudi (Pre-release; available in 0.10.0) RFC-33: Full-schema evolution support (PR #3668) RFC-35: BigQuery integration
- 29. Major Ongoing Works RFC-20: Error tables (PR #3312) RFC-08: Record level indexing (PR #3508) RFC-15: Synchronous, Multi table Metadata writes (PR #3590) Hudi + Dbt (dbt-labs/dbt-spark/pull/210) PrestoDB/Trino Connectors (Early design)
- 30. Hudi is broadly adopted outside More at : http://hudi.apache.org/powered-by
- 31. Engage With Our Community User Docs : https://hudi.apache.org Technical Wiki : https://cwiki.apache.org/confluence/display/HUDI Github : https://github.com/apache/hudi/ Twitter : https://twitter.com/apachehudi Mailing list(s) : [email protected] (send an empty email to subscribe) [email protected] (actual mailing list) Slack : https://join.slack.com/t/apache-hudi/signup