




Apache Kafka with AWS s3 storage
- 1. www.bisptrainings.com Kafka Connectivity with AWS S3 Storage Sno Date Modification Author Verified By 1 2019/08/06 Initial Document Nishtha Sumit Goyal
- 2. www.bisptrainings.com Table of Contents Introduction.......................................................................................................................................... 3 Objective............................................................................................................................................ 3 Solutions:........................................................................................................................................... 3 Step1 Get Kafka .................................................................................................................................... 3 Step 2: Create a S3 bucket:................................................................................................................... 5 Step 3: Connect with S3 bucket............................................................................................................ 5 Step 4: Go into docker bash ................................................................................................................. 6 Step 5: Creating Kafka topic ................................................................................................................. 6 Step 6: Start Kafka console producer ................................................................................................... 6 Step 7: Start Kafka Console Consumer ................................................................................................. 7 Step 8: Type in something in the producer console............................................................................. 7
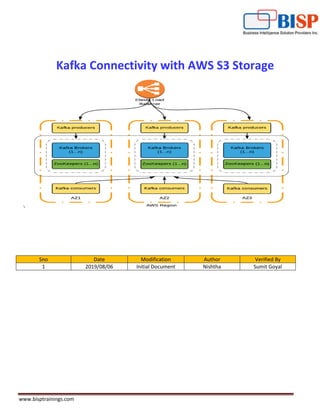
- 3. www.bisptrainings.com Introduction Kafka is a distributed streaming platform that is used publish and subscribe to streams of records. Kafka gets used for fault tolerant storage. Kafka replicates topic log partitions to multiple servers. Kafka is designed to allow your apps to process records as they occur. Kafka is fast, uses IO efficiently by batching, compressing records. Kafka gets used for decoupling data streams. Kafka is used to stream data into data lakes, applications and real-time stream analytic systems. An Amazon S3 bucket is a public cloud storage resource available in Amazon Web Services' (AWS) Simple Storage Service (S3), an object storage offering. Amazon S3 buckets, which are similar to file folders, store objects, which consist of data and its descriptive metadata. Objective The main objective of this project is that we input some text in Kafka producer console and it will automatically appear in our s3 bucket as a JSON file Solutions: Note: In this document we explain step by step Implementation between kafka and s3 storage (To store message). Step1 Get Kafka Run the following command docker run -p 2181:2181 -p 3030:3030 -p 8081-8083:8081-8083 -p 9581-9585:9581-9585 -p 9092:9092 -e AWS_ACCESS_KEY_ID=your_aws_access_key_without_quotes -e AWS_SECRET_ACCESS_KEY=your_aws_secret_key_without_quotes -e ADV_HOST=127.0.0.1 landoop/fast-data-dev:latest-
- 4. www.bisptrainings.com In addition to that, you should see it loads quite a lot of services including Zookeeeper, broker, schema registry, rest proxy, connect. That is where we are opening various ports. After about two minutes you should be able to go to http://127.0.0.1:3030 to see the Kafka connect UI.
- 5. www.bisptrainings.com Step 2: Create a S3 bucket: The next step is to connect to the S3 bucket since we will be uploading our files to s3 bucket. Login to your aws account and create your bucket. Step 3: Connect with S3 bucket From the User interface, click enter at Kafka connect UI . Once you are there, click New connector. After you click new connector, you will see a lot of connector that you can connect to. Since we want to connect to S3, click the Amazon S3 icon. And you can see that you are presented with some settings with lots of errors. In order to get rid of the error, we need to change the following settings. From the following list, you need to change your s3.region as your bucket may not be in Sydney and your s3.bucket.name to the bucket you have created. name=S3SinkConnector connector.class=io.confluent.connect.s3.S3SinkConnector s3.region=ap-southeast-2 format.class=io.confluent.connect.s3.format.json.JsonFormat topics.dir=topics flush.size=1 topics=name of your topic tasks.max=1 value.converter=org.apache.kafka.connect.storage.StringConverter storage.class=io.confluent.connect.s3.storage.S3Storage key.converter=org.apache.kafka.connect.storage.StringConverter s3.bucket.name=your s3 bucket name
- 6. www.bisptrainings.com Once you fill up all the details and click create, you should see it similar to what I have. Step 4: Go into docker bash In order to open the bash inside the docker, we will need the docker id. To get the id, we can do a docker ps docker ps This will give you a list of docker container that is running. If you notice from the image, I have only one container running with the ID ‘66bf4d3ffa46 ’. To open the bash inside there, we can now type in the following command. docker exec -it 66bf4d3ffa46 /bin/bash This will get the us in the bash and we can now create our topic, producer and consumer root@fast-data-dev / $ Step 5: Creating Kafka topic The Kafka cluster stores streams of records in categories called topics. So if we don’t have a topic, we can’t stream our records, or for our case type a message and send it through. Step 6: Start Kafka console producer To create messages, we will need to start our Kafka producer console. To create Kafka console producer, we will use the following command. Once you press enter, you should see a > appear on the screen expecting you to type something.
- 7. www.bisptrainings.com Step 7: Start Kafka Console Consumer To check if the message that you are typing is actually going through, lets open a consumer console. To do that, we will open a new terminal window and go in the same docker container by doing the following Step 8: Type in something in the producer console If we now type anything in the kafka-console-producer, it will appear in the console consumer and create a json file in S3. Download it the file and you will see what you typed!