Apache spark
3 likes524 views

Apache Spark is an open-source parallel processing framework for large-scale data analytics, significantly outperforming MapReduce in speed for certain applications. It supports both in-memory and disk-based processing, and offers a range of high-level libraries for tasks such as machine learning (MLlib), streaming (Spark Streaming), and graph processing (GraphX). Spark SQL facilitates querying structured data through SQL and integrates various Spark components seamlessly.



















Apache spark
- 1. Guide : Mrs. Juhi Singh Submitted by: Hitesh DuaCSE 4thYear05510402711
- 4. Sustained exponential growth, as one of the most active Apache projects
- 6. ●Open Source ●Alternative to Map Reduce for certain applications ●A low latency cluster computing system for very large data sets ●Higher level library for stream processing, through Spark Streaming. ●May be 100 times faster than Map Reduce for –Iterative algorithms –Interactive data mining
- 8. •Started as a research project at theUC Berkeley AMPLabin 2009, and was open sourced in early 2010. •After being released, Spark grew a developer community on GitHuband entered Apache in 2013 as its permanent home. •Codebase size Spark : 20,000 LOC Hadoop 1.0 : 90,000 LOC
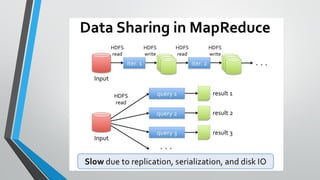
- 10. •MapReduce greatly simplified big data analysis. •But as soon as it got popular, users wanted more: »More complex, multi‐stage applications (e.g. iterative graph algorithms and machine learning) »More interactive ad-hoc queries. •Both multi‐stage and interactive apps require fasterdata sharing across parallel jobs.
- 13. •Resilient Distributed Datasets (RDDs) are basic building block. Distributed collections of objects that can be cached in memory across cluster nodes. Automatically rebuilt on failure. •RDD operations Transformations: Creates new dataset from existing one. e.g. Map. Actions: Return a value to a driver program after running computation on the dataset. e.g. Reduce. Spark : Programming Model
- 15. SparkStackExtensionSparkpowersastackofhigh-leveltoolsincluding •SparkSQL •SparkStreaming. •MLlibformachinelearning •GraphX Youcancombinetheseframeworksseamlesslyinthesameapplication.
- 17. GraphXisalibraryaddedinSpark0.9thatprovidesanAPIformanipulatinggraphs(e.g.,asocialnetwork’sfriendgraph)andperforminggraph-parallelcomputations. •Allowsustocreateadirectedgraphwitharbitrarypropertiesattachedtoeachvertexandedge. •GraphXalsoprovidessetofoperatorsformanipulatinggraphs •libraryofcommongraphalgorithms(e.g.,PageRankandtrianglecounting).
- 18. MLlibprovidesmultipletypesofmachinelearningalgorithms,includingbinaryclassification,regression,clusteringandcollaborativefiltering. •Supportsfunctionalitysuchasmodelevaluationanddataimport. •Designedtoscaleoutacrossacluster. •MLlibcontainshigh-qualityalgorithmsthatleverageiteration,andcanyieldbetterresultsthantheone-passapproximationssometimesusedonMapReduce.
- 19. Spark SQL provides support for interacting with Spark via SQL as well as the Apache Hive variant of SQL, called the Hive Query Language (HiveQL). •Spark SQL represents database tables as Spark RDDs and translates SQL queries into Spark operations. •Spark SQL lets you query structured data as a distributed dataset (RDD) in Spark. •Spark SQL includes a server mode with industry standard JDBC and ODBC connectivity.