Apache Spark - Basics of RDD & RDD Operations | Big Data Hadoop Spark Tutorial | CloudxLab
1 like545 views

The document provides an overview of various operations and transformations associated with Resilient Distributed Datasets (RDDs) in Apache Spark, including sampling, mapping functions, sorting, and set operations. It covers common transformations, actions like fold and aggregate, and methods to count occurrences and retrieve top elements. Additionally, it discusses differences between actions like foreach and transformations like map.

![Basics of RDD
More Transformations
sample(withReplacement, fraction, [seed])
Sample an RDD, with or without replacement.](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-2-320.jpg)
![Basics of RDD
val seq = sc.parallelize(1 to 100, 5)
seq.sample(false, 0.1).collect();
[8, 19, 34, 37, 43, 51, 70, 83]
More Transformations
sample(withReplacement, fraction, [seed])
Sample an RDD, with or without replacement.](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-3-320.jpg)
![Basics of RDD
More Transformations
sample(withReplacement, fraction, [seed])
Sample an RDD, with or without replacement.
val seq = sc.parallelize(1 to 100, 5)
seq.sample(false, 0.1).collect();
[8, 19, 34, 37, 43, 51, 70, 83]
seq.sample(true, 0.1).collect();
[14, 26, 40, 47, 55, 67, 69, 69]
Please note that the result will be different on every run.](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-4-320.jpg)


![Basics of RDD
val rdd = sc.parallelize(1 to 50, 3)
def f(l:Iterator[Int]):Iterator[Int] = {
var sum = 0
while(l.hasNext){
sum = sum + l.next
}
return List(sum).iterator
}
Common Transformations (continued..)
mapPartitions(f, preservesPartitioning=False)
Return a new RDD by applying a function to each partition of this RDD.](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-7-320.jpg)
![Basics of RDD
val rdd = sc.parallelize(1 to 50, 3)
def f(l:Iterator[Int]):Iterator[Int] = {
var sum = 0
while(l.hasNext){
sum = sum + l.next
}
return List(sum).iterator
}
rdd.mapPartitions(f).collect()
Array(136, 425, 714)
17, 17, 16
Common Transformations (continued..)
mapPartitions(f, preservesPartitioning=False)
Return a new RDD by applying a function to each partition of this RDD.](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-8-320.jpg)





![Basics of RDD
⋙ var tmp = List(('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5))
⋙ var rdd = sc.parallelize(tmp)
⋙ rdd.sortBy(x => x._1).collect()
[('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
Common Transformations (continued..)
sortBy(keyfunc, ascending=True, numPartitions=None)
Sorts this RDD by the given keyfunc](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-14-320.jpg)
![Basics of RDD
⋙ var tmp = List(('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5))
⋙ var rdd = sc.parallelize(tmp)
⋙ rdd.sortBy(x => x._2).collect()
[('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
Common Transformations (continued..)
sortBy(keyfunc, ascending=True, numPartitions=None)
Sorts this RDD by the given keyfunc](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-15-320.jpg)


























![Basics of RDD
sc.parallelize(List(10, 1, 2, 9, 3, 4, 5, 6, 7)).takeOrdered(6)
var l = List((10, "SG"), (1, "AS"), (2, "AB"), (9, "AA"), (3, "SS"), (4, "RG"), (5, "AU"), (6, "DD"), (7, "ZZ"))
var r = sc.parallelize(l)
r.takeOrdered(6)(Ordering[Int].reverse.on(x => x._1))
(10,SG), (9,AA), (7,ZZ), (6,DD), (5,AU), (4,RG)
r.takeOrdered(6)(Ordering[String].reverse.on(x => x._2))
(7,ZZ), (3,SS), (10,SG), (4,RG), (6,DD), (5,AU)
r.takeOrdered(6)(Ordering[String].on(x => x._2))
(9,AA), (2,AB), (1,AS), (5,AU), (6,DD), (4,RG)
Get the N elements from an RDD ordered in ascending order or as specified by
the optional key function.
More Actions: takeOrdered()](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-43-320.jpg)



![Basics of RDD
def partitionSum(itr: Iterator[Int]) =
println("The sum of the parition is " + itr.sum.toString)
Applies a function to each partition of this RDD.
More Actions: foreachPartition(f)](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-47-320.jpg)
![Basics of RDD
Applies a function to each partition of this RDD.
More Actions: foreachPartition(f)
def partitionSum(itr: Iterator[Int]) =
println("The sum of the parition is " + itr.sum.toString)
sc.parallelize(1 to 40, 4).foreachPartition(partitionSum)
The sum of the parition is 155
The sum of the parition is 55
The sum of the parition is 355
The sum of the parition is 255](https://image.slidesharecdn.com/s3-180514105412/85/Apache-Spark-Basics-of-RDD-RDD-Operations-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-48-320.jpg)

Apache Spark - Basics of RDD & RDD Operations | Big Data Hadoop Spark Tutorial | CloudxLab
- 1. Basics of RDD - More Operations
- 2. Basics of RDD More Transformations sample(withReplacement, fraction, [seed]) Sample an RDD, with or without replacement.
- 3. Basics of RDD val seq = sc.parallelize(1 to 100, 5) seq.sample(false, 0.1).collect(); [8, 19, 34, 37, 43, 51, 70, 83] More Transformations sample(withReplacement, fraction, [seed]) Sample an RDD, with or without replacement.
- 4. Basics of RDD More Transformations sample(withReplacement, fraction, [seed]) Sample an RDD, with or without replacement. val seq = sc.parallelize(1 to 100, 5) seq.sample(false, 0.1).collect(); [8, 19, 34, 37, 43, 51, 70, 83] seq.sample(true, 0.1).collect(); [14, 26, 40, 47, 55, 67, 69, 69] Please note that the result will be different on every run.
- 5. Basics of RDD Common Transformations (continued..) mapPartitions(f, preservesPartitioning=False) Return a new RDD by applying a function to each partition of this RDD.
- 6. Basics of RDD val rdd = sc.parallelize(1 to 50, 3) Common Transformations (continued..) mapPartitions(f, preservesPartitioning=False) Return a new RDD by applying a function to each partition of this RDD.
- 7. Basics of RDD val rdd = sc.parallelize(1 to 50, 3) def f(l:Iterator[Int]):Iterator[Int] = { var sum = 0 while(l.hasNext){ sum = sum + l.next } return List(sum).iterator } Common Transformations (continued..) mapPartitions(f, preservesPartitioning=False) Return a new RDD by applying a function to each partition of this RDD.
- 8. Basics of RDD val rdd = sc.parallelize(1 to 50, 3) def f(l:Iterator[Int]):Iterator[Int] = { var sum = 0 while(l.hasNext){ sum = sum + l.next } return List(sum).iterator } rdd.mapPartitions(f).collect() Array(136, 425, 714) 17, 17, 16 Common Transformations (continued..) mapPartitions(f, preservesPartitioning=False) Return a new RDD by applying a function to each partition of this RDD.
- 9. Basics of RDD Common Transformations (continued..) sortBy(func, ascending=True, numPartitions=None) Sorts this RDD by the given func
- 10. Basics of RDD func: A function used to compute the sort key for each element. Common Transformations (continued..) sortBy(func, ascending=True, numPartitions=None) Sorts this RDD by the given func
- 11. Basics of RDD Common Transformations (continued..) sortBy(func, ascending=True, numPartitions=None) Sorts this RDD by the given func func: A function used to compute the sort key for each element. ascending: A flag to indicate whether the sorting is ascending or descending.
- 12. Basics of RDD Common Transformations (continued..) sortBy(func, ascending=True, numPartitions=None) Sorts this RDD by the given func func: A function used to compute the sort key for each element. ascending: A flag to indicate whether the sorting is ascending or descending. numPartitions: Number of partitions to create.
- 13. Basics of RDD ⋙ var tmp = List(('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)) ⋙ var rdd = sc.parallelize(tmp) Common Transformations (continued..) sortBy(keyfunc, ascending=True, numPartitions=None) Sorts this RDD by the given keyfunc
- 14. Basics of RDD ⋙ var tmp = List(('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)) ⋙ var rdd = sc.parallelize(tmp) ⋙ rdd.sortBy(x => x._1).collect() [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)] Common Transformations (continued..) sortBy(keyfunc, ascending=True, numPartitions=None) Sorts this RDD by the given keyfunc
- 15. Basics of RDD ⋙ var tmp = List(('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)) ⋙ var rdd = sc.parallelize(tmp) ⋙ rdd.sortBy(x => x._2).collect() [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)] Common Transformations (continued..) sortBy(keyfunc, ascending=True, numPartitions=None) Sorts this RDD by the given keyfunc
- 16. Basics of RDD Common Transformations (continued..) sortBy(keyfunc, ascending=True, numPartitions=None) Sorts this RDD by the given keyfunc var rdd = sc.parallelize(Array(10, 2, 3,21, 4, 5)) var sortedrdd = rdd.sortBy(x => x) sortedrdd.collect()
- 17. Basics of RDD Common Transformations (continued..) Pseudo set operations Though RDD is not really a set but still the set operations try to provide you utility set functions
- 18. Basics of RDD distinct() + Give the set property to your rdd + Expensive as shuffling is required Set operations (Pseudo)
- 19. Basics of RDD union() + Simply appends one rdd to another + Is not same as mathematical function + It may have duplicates Set operations (Pseudo)
- 20. Basics of RDD subtract() + Returns values in first RDD and not second + Requires Shuffling like intersection() Set operations (Pseudo)
- 21. Basics of RDD intersection() + Finds common values in RDDs + Also removes duplicates + Requires shuffling Set operations (Pseudo)
- 22. Basics of RDD cartesian() + Returns all possible pairs of (a,b) + a is in source RDD and b is in other RDD Set operations (Pseudo)
- 23. Basics of RDD fold(initial value, func) + Very similar to reduce + Provides a little extra control over the initialisation + Lets us specify an initial value More Actions - fold()
- 24. Basics of RDD More Actions - fold() fold(initial value, func) Aggregates the elements of each partition and then the results for all the partitions using a given associative and commutative function and a neutral "zero value". 1 7 2 4 7 6 Partition 1 Partition 2
- 25. Basics of RDD More Actions - fold() fold(initial value, func) Aggregates the elements of each partition and then the results for all the partitions using a given associative and commutative function and a neutral "zero value". 1 7 2 4 7 6 Partition 1 Partition 2 Initial Value Initial Value
- 26. Basics of RDD More Actions - fold() fold(initial value)(func) Aggregates the elements of each partition and then the results for all the partitions using a given associative and commutative function and a neutral "zero value". Initial Value 1 7 2 4 7 6Initial Value Partition 1 Partition 2 1 1
- 27. Basics of RDD More Actions - fold() fold(initial value)(func) Aggregates the elements of each partition and then the results for all the partitions using a given associative and commutative function and a neutral "zero value". Initial Value 1 7 2 4 7 6Initial Value Partition 1 Partition 2 1 2 3 1 2 3 Result1 Result2
- 28. Basics of RDD More Actions - fold() fold(initial value)(func) Aggregates the elements of each partition and then the results for all the partitions using a given associative and commutative function and a neutral "zero value". Result1 Result2Initial Value 4 5 1 7 2 4 7 6 Partition 1 Partition 2 1 2 3 1 2 3
- 29. Basics of RDD var myrdd = sc.parallelize(1 to 10, 2) More Actions - fold() fold(initial value, func) Example: Concatnating to _
- 30. Basics of RDD var myrdd = sc.parallelize(1 to 10, 2) var myrdd1 = myrdd.map(_.toString) More Actions - fold() fold(initial value, func) Example: Concatnating to _
- 31. Basics of RDD var myrdd = sc.parallelize(1 to 10, 2) var myrdd1 = myrdd.map(_.toString) def concat(s:String, n:String):String = s + n More Actions - fold() fold(initial value, func) Example: Concatnating to _
- 32. Basics of RDD More Actions - fold() var myrdd = sc.parallelize(1 to 10, 2) var myrdd1 = myrdd.map(_.toString) def concat(s:String, n:String):String = s + n var s = "_" myrdd1.fold(s)(concat) res1: String = _ _12345 _678910 fold(initial value, func) Example: Concatnating to _
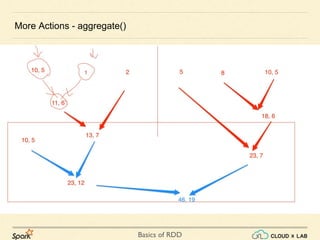
- 33. Basics of RDD More Actions - aggregate() aggregate(initial value) (seqOp, combOp) 1. First, all values of each partitions are merged to Initial value using SeqOp() 2. Second, all partitions result is combined together using combOp 3. Used specially when the output is different data type 1, 2, 3 4,5 6,7 SeqOp() SeqOp() SeqOp() CombOp() Output
- 34. Basics of RDD More Actions - aggregate() aggregate(initial value) (seqOp, combOp) 1. First, all values of each partitions are merged to Initial value using SeqOp() 2. Second, all partitions result is combined together using combOp 3. Used specially when the output is different data type
- 35. Basics of RDD More Actions - aggregate()
- 36. Basics of RDD var rdd = sc.parallelize(1 to 100) More Actions - aggregate() aggregate(initial value) (seqOp, combOp) 1. First, all values of each partitions are merged to Initial value using SeqOp() 2. Second, all partitions result is combined together using combOp 3. Used specially when the output is different data type
- 37. Basics of RDD var rdd = sc.parallelize(1 to 100) var init = (0, 0) // sum, count More Actions - aggregate() aggregate(initial value) (seqOp, combOp) 1. First, all values of each partitions are merged to Initial value using SeqOp() 2. Second, all partitions result is combined together using combOp 3. Used specially when the output is different data type
- 38. Basics of RDD var rdd = sc.parallelize(1 to 100) var init = (0, 0) // sum, count def seq(t:(Int, Int), i:Int): (Int, Int) = (t._1 + i, t._2 + 1) More Actions - aggregate() aggregate(initial value) (seqOp, combOp) 1. First, all values of each partitions are merged to Initial value using SeqOp() 2. Second, all partitions result is combined together using combOp 3. Used specially when the output is different data type
- 39. Basics of RDD More Actions - aggregate() aggregate(initial value) (seqOp, combOp) 1. First, all values of each partitions are merged to Initial value using SeqOp() 2. Second, all partitions result is combined together using combOp 3. Used specially when the output is different data type var rdd = sc.parallelize(1 to 100) var init = (0, 0) // sum, count def seq(t:(Int, Int), i:Int): (Int, Int) = (t._1 + i, t._2 + 1) def comb(t1:(Int, Int), t2:(Int, Int)): (Int, Int) = (t1._1 + t2._1, t1._2 + t2._2) var d = rdd.aggregate(init)(seq, comb) res6: (Int, Int) = (5050,100)
- 40. Basics of RDD More Actions - aggregate() var rdd = sc.parallelize(1 to 100) var init = (0, 0) // sum, count def seq(t:(Int, Int), i:Int): (Int, Int) = (t._1 + i, t._2 + 1) def comb(t1:(Int, Int), t2:(Int, Int)): (Int, Int) = (t1._1 + t2._1, t1._2 + t2._2) var d = rdd.aggregate(init)(seq, comb) aggregate(initial value) (seqOp, combOp) 1. First, all values of each partitions are merged to Initial value using SeqOp() 2. Second, all partitions result is combined together using combOp 3. Used specially when the output is different data type res6: (Int, Int) = (5050,100)
- 41. Basics of RDD Number of times each element occurs in the RDD. More Actions: countByValue() 1 2 3 3 5 5 5 var rdd = sc.parallelize(List(1, 2, 3, 3, 5, 5, 5)) var dict = rdd.countByValue() dict Map(1 -> 1, 5 -> 3, 2 -> 1, 3 -> 2)
- 42. Basics of RDD Sorts and gets the maximum n values. More Actions: top(n) 4 4 8 1 2 3 10 9 var a=sc.parallelize(List(4,4,8,1,2, 3, 10, 9)) a.top(6) Array(10, 9, 8, 4, 4, 3)
- 43. Basics of RDD sc.parallelize(List(10, 1, 2, 9, 3, 4, 5, 6, 7)).takeOrdered(6) var l = List((10, "SG"), (1, "AS"), (2, "AB"), (9, "AA"), (3, "SS"), (4, "RG"), (5, "AU"), (6, "DD"), (7, "ZZ")) var r = sc.parallelize(l) r.takeOrdered(6)(Ordering[Int].reverse.on(x => x._1)) (10,SG), (9,AA), (7,ZZ), (6,DD), (5,AU), (4,RG) r.takeOrdered(6)(Ordering[String].reverse.on(x => x._2)) (7,ZZ), (3,SS), (10,SG), (4,RG), (6,DD), (5,AU) r.takeOrdered(6)(Ordering[String].on(x => x._2)) (9,AA), (2,AB), (1,AS), (5,AU), (6,DD), (4,RG) Get the N elements from an RDD ordered in ascending order or as specified by the optional key function. More Actions: takeOrdered()
- 44. Basics of RDD Applies a function to all elements of this RDD. More Actions: foreach() >>> def f(x:Int)= println(s"Save $x to DB") >>> sc.parallelize(1 to 5).foreach(f) Save 2 to DB Save 1 to DB Save 4 to DB Save 5 to DB
- 45. Basics of RDD Differences from map() More Actions: foreach() 1. Use foreach if you don't expect any result. For example saving to database. 2. Foreach is an action. Map is transformation
- 46. Basics of RDD Applies a function to each partition of this RDD. More Actions: foreachPartition(f)
- 47. Basics of RDD def partitionSum(itr: Iterator[Int]) = println("The sum of the parition is " + itr.sum.toString) Applies a function to each partition of this RDD. More Actions: foreachPartition(f)
- 48. Basics of RDD Applies a function to each partition of this RDD. More Actions: foreachPartition(f) def partitionSum(itr: Iterator[Int]) = println("The sum of the parition is " + itr.sum.toString) sc.parallelize(1 to 40, 4).foreachPartition(partitionSum) The sum of the parition is 155 The sum of the parition is 55 The sum of the parition is 355 The sum of the parition is 255
- 49. Thank you! Basics of RDD