Apache Spark - Basics of RDD | Big Data Hadoop Spark Tutorial | CloudxLab
4 likes2,782 views

The document provides an overview of Resilient Distributed Datasets (RDDs) in Apache Spark, explaining their structure as immutable collections of data that are partitioned across clusters and recoverable from failures. It covers key operations on RDDs including transformations (like map, filter, and flatMap) and actions (like collect, take, and reduce), emphasizing the importance of lazy evaluation for optimization. Additionally, the document discusses practical examples and the differences between map and flatMap operations.












![Basics of RDD
➢ val arr = 1 to 10000
➢ val nums = sc.parallelize(arr)
➢ def multiplyByTwo(x:Int):Int = x*2
➢ multiplyByTwo(5)
10
➢ var dbls = nums.map(multiplyByTwo);
➢ dbls.take(5)
[2, 4, 6, 8, 10]
Map Transformation - Scala](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-13-320.jpg)
![Basics of RDD
Transformations - filter() - scala
1 2 3 4 5 6 7
2 4 6
isEven(2) isEven(4) isEven(6)
isEven(1) isEven(7)isEven(3) isEven(5)
nums
evens
➢ var arr = 1 to 1000
➢ var nums = sc.parallelize(arr)
➢ def isEven(x:Int):Boolean = x%2 == 0
➢ var evens =
nums.filter(isEven)
➢ evens.take(3)
➢ [2, 4, 6]
…..
…..](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-14-320.jpg)

![Basics of RDD
➢ val arr = 1 to 1000000
➢ val nums = sc.parallelize(arr)
➢ def multipleByTwo(x:Int):Int = x*2
Action Example - take()
➢ var dbls =
nums.map(multipleByTwo);
➢ dbls.take(5)
➢ [2, 4, 6, 8, 10]](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-16-320.jpg)










![Basics of RDD
Transformations:: flatMap() - Scala
➢ var linesRDD = sc.parallelize( Array("this is a dog", "named jerry"))
➢ def toWords(line:String):Array[String]= line.split(" ")
➢ var wordsRDD = linesRDD.flatMap(toWords)
➢ wordsRDD.collect()
➢ ['this', 'is', 'a', 'dog', 'named', 'jerry']
this is a dog named jerry
this is a dog
toWords() toWords()
linesRDD
wordsRDD named jerry](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-27-320.jpg)

![Basics of RDD
What would happen if map() is used
➢ var linesRDD = sc.parallelize( Array("this is a dog", "named jerry"))
➢ def toWords(line:String):Array[String]= line.split(" ")
➢ var wordsRDD1 = linesRDD.map(toWords)
➢ wordsRDD1.collect()
➢ [['this', 'is', 'a', 'dog'], ['named', 'jerry']]
this is a dog named jerrylinesRDD
wordsRDD1 ['this', 'is', 'a', 'dog'] ['named', 'jerry']
toWords() toWords()](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-29-320.jpg)


![Basics of RDD
➢ val arr = 1 to 10000
➢ val nums = sc.parallelize(arr)
➢ def multiplyByTwo(x:Int) = Array(x*2)
➢ multiplyByTwo(5)
Array(10)
➢ var dbls = nums.flatMap(multiplyByTwo);
➢ dbls.take(5)
[2, 4, 6, 8, 10]
flatMap as map](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-32-320.jpg)
![Basics of RDD
flatMap as filter
➢ var arr = 1 to 1000
➢ var nums = sc.parallelize(arr)
➢ def isEven(x:Int):Array[Int] = {
➢ if(x%2 == 0) Array(x)
➢ else Array()
➢ }
➢ var evens =
nums.flatMap(isEven)
➢ evens.take(3)
➢ [2, 4, 6]](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-33-320.jpg)
![Basics of RDD
Transformations:: Union
['1', '2', '3']
➢ var a = sc.parallelize(Array('1','2','3'));
➢ var b = sc.parallelize(Array('A','B','C'));
➢ var c=a.union(b)
➢ Note: doesn't remove duplicates
➢ c.collect();
[1, 2, 3, 'A', 'B', 'C']
['A','B','C'])
['1', '2', '3', 'A','B','C']
Union](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-34-320.jpg)


![Basics of RDD
➢ var a = sc.parallelize(Array(1,2,3, 4, 5 , 6, 7));
➢ a
org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[16] at parallelize at <console>:21
➢ var localarray = a.collect();
➢ localarray
[1, 2, 3, 4, 5, 6, 7]
Actions: collect() - Scala
1 2 3 4 5 6 7
Brings all the elements back to you. Data must fit into memory.
Mostly it is impractical.](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-37-320.jpg)
![Basics of RDD
➢ var a = sc.parallelize(Array(1,2,3, 4, 5 , 6, 7));
➢ var localarray = a.take(4);
➢ localarray
[1, 2, 3, 4]
Actions: take() - Scala
1 2 3 4 5 6 7
Bring only few elements to the driver.
This is more practical than collect()](https://image.slidesharecdn.com/s2-180514105405/85/Apache-Spark-Basics-of-RDD-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-38-320.jpg)






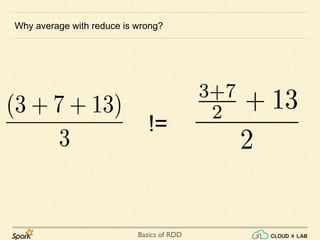





































Apache Spark - Basics of RDD | Big Data Hadoop Spark Tutorial | CloudxLab
- 2. Basics of RDD Dataset: Collection of data elements. e.g. Array, Tables, Data frame (R), collections of mongodb Distributed: Parts Multiple machines Resilient: Recovers on Failure What is RDD? RDDs - Resilient Distributed Datasets
- 3. Basics of RDD SPARK - CONCEPTS - RESILIENT DISTRIBUTED DATASET A collection of elements partitioned across cluster Machine 1 Machine 2 Machine 3 Machine 4
- 4. Basics of RDD SPARK - CONCEPTS - RESILIENT DISTRIBUTED DATASET Resilient Distributed Dataset (RDD) Node 1 Node 2 Node 3 Node 4 Driver Application Spark Application Spark Application Spark Application Spark Application 5, 6, 7, 8 9, 10, 11, 121, 2, 3, 4 13, 14, 15
- 5. Basics of RDD SPARK - CONCEPTS - RESILIENT DISTRIBUTED DATASET A collection of elements partitioned across cluster • An immutable distributed collection of objects. • Split in partitions which may be on multiple nodes • Can contain any data type: ○ Python, ○ Java, ○ Scala objects ○ including user defined classes
- 6. Basics of RDD SPARK - CONCEPTS - RESILIENT DISTRIBUTED DATASET • RDD Can be persisted in memory • RDD Auto recover from node failures • Can have any data type but has a special dataset type for key-value • Supports two type of operations: ○ Transformation ○ Action
- 7. Basics of RDD >> val arr = 1 to 10000 >> var nums = sc.parallelize(arr) Creating RDD - Scala >>var lines = sc.textFile("/data/mr/wordcount/input/big.txt") Method 1: By Directly Loading a file from remote Method 2: By distributing existing object
- 8. Basics of RDD WordCount - Scala var linesRdd = sc.textFile("/data/mr/wordcount/input/big.txt") var words = linesRdd.flatMap(x => x.split(" ")) var wordsKv = words.map(x => (x, 1)) //def myfunc(x:Int, y:Int): Int = x + y var output = wordsKv.reduceByKey(_ + _) output.take(10) or output.saveAsTextFile("my_result")
- 9. Basics of RDD RDD Operations Two Kinds Operations Transformation Action
- 10. Basics of RDD RDD - Operations : Transformation Resilient Distributed Dataset 2 (RDD) Transformation Transformation Transformation Transformation Resilient Distributed Dataset 1 (RDD) • Transformations are operations on RDDs • return a new RDD • such as map() and filter()
- 11. Basics of RDD RDD - Operations : Transformation • Transformations are operations on RDDs • return a new RDD • such as map() and filter()
- 12. Basics of RDD ➢ Map is a transformation ➢ That runs provided function against each element of RDD ➢ And creates a new RDD from the results of execution function Map Transformation
- 13. Basics of RDD ➢ val arr = 1 to 10000 ➢ val nums = sc.parallelize(arr) ➢ def multiplyByTwo(x:Int):Int = x*2 ➢ multiplyByTwo(5) 10 ➢ var dbls = nums.map(multiplyByTwo); ➢ dbls.take(5) [2, 4, 6, 8, 10] Map Transformation - Scala
- 14. Basics of RDD Transformations - filter() - scala 1 2 3 4 5 6 7 2 4 6 isEven(2) isEven(4) isEven(6) isEven(1) isEven(7)isEven(3) isEven(5) nums evens ➢ var arr = 1 to 1000 ➢ var nums = sc.parallelize(arr) ➢ def isEven(x:Int):Boolean = x%2 == 0 ➢ var evens = nums.filter(isEven) ➢ evens.take(3) ➢ [2, 4, 6] ….. …..
- 15. Basics of RDD RDD - Operations : Actions • Causes the full execution of transformations • Involves both spark driver as well as the nodes • Example - Take(): Brings back the data to driver
- 16. Basics of RDD ➢ val arr = 1 to 1000000 ➢ val nums = sc.parallelize(arr) ➢ def multipleByTwo(x:Int):Int = x*2 Action Example - take() ➢ var dbls = nums.map(multipleByTwo); ➢ dbls.take(5) ➢ [2, 4, 6, 8, 10]
- 17. Basics of RDD To save the results in HDFS or Any other file system Call saveAsTextFile(directoryName) It would create directory And save the results inside it If directory exists, it would throw error. Action Example - saveAsTextFile()
- 18. Basics of RDD val arr = 1 to 1000 val nums = sc.parallelize(arr) def multipleByTwo(x:Int):Int = x*2 Action Example - saveAsTextFile() var dbls = nums.map(multipleByTwo); dbls.saveAsTextFile("mydirectory") Check the HDFS home directory
- 19. Basics of RDD RDD Operations Transformation Action Examples map() take() Returns Another RDD Local value Executes Lazily Immediately. Executes transformations
- 20. Basics of RDD Cheese burger, soup and a Plate of Noodles please Soup and A Plate of Noodles for me Ok. One cheese burger Two soups Two plates of Noodles Anything else, sir? The chef is able to optimize because of clubbing multiple order together Lazy Evaluation Example - The waiter takes orders patiently
- 21. Basics of RDD And Soup? Cheese Burger... Let me get a cheese burger for you. I'll be right back! Instant Evaluation The soup order will be taken once the waiter is back.
- 22. Basics of RDD Instant Evaluation The usual programing languages have instant evaluation. As you as you type: var x = 2+10. It doesn't wait. It immediately evaluates.
- 23. Basics of RDD Actions: Lazy Evaluation 1. Every time we call an action, entire RDD must be computed from scratch 2. Everytime d gets executed, a,b,c would be run a. lines = sc.textFile("myfile"); b. fewlines = lines.filter(...) c. uppercaselines = fewlines.map(...) d. uppercaselines.count() 3. When we call a transformation, it is not evaluated immediately. 4. It helps Spark optimize the performance 5. Similar to Pig, tensorflow etc. 6. Instead of thinking RDD as dataset, think of it as the instruction on how to compute data
- 24. Basics of RDD Actions: Lazy Evaluation - Optimization - Scala def Map1(x:String):String = x.trim(); def Map2(x:String):String = x.toUpperCase(); var lines = sc.textFile(...) var lines1 = lines.map(Map1); var lines2 = lines1.map(Map2); lines2.collect() def Map3(x:String):String={ var y = x.trim(); return y.toUpperCase(); } lines = sc.textFile(...) lines2 = lines.map(Map3); lines2.collect()
- 25. Basics of RDD Lineage Graph lines = sc.textFile("myfile"); fewlines = lines.filter(...) uppercaselines = fewlines.map(...) uppercaselines.count() lines Spark Code Lineage Graph HDFS Input Split fewlines uppercaselines sc.textFile filter map lowercaselines = fewlines.map(...) lowercaselines map 1 2 3
- 26. Basics of RDD Transformations:: flatMap() - Scala To convert one record of an RDD into multiple records.
- 27. Basics of RDD Transformations:: flatMap() - Scala ➢ var linesRDD = sc.parallelize( Array("this is a dog", "named jerry")) ➢ def toWords(line:String):Array[String]= line.split(" ") ➢ var wordsRDD = linesRDD.flatMap(toWords) ➢ wordsRDD.collect() ➢ ['this', 'is', 'a', 'dog', 'named', 'jerry'] this is a dog named jerry this is a dog toWords() toWords() linesRDD wordsRDD named jerry
- 28. Basics of RDD How is it different from Map()? ● In case of map() the resulting rdd and input rdd having same number of elements. ● map() can only convert one to one while flatMap could convert one to many.
- 29. Basics of RDD What would happen if map() is used ➢ var linesRDD = sc.parallelize( Array("this is a dog", "named jerry")) ➢ def toWords(line:String):Array[String]= line.split(" ") ➢ var wordsRDD1 = linesRDD.map(toWords) ➢ wordsRDD1.collect() ➢ [['this', 'is', 'a', 'dog'], ['named', 'jerry']] this is a dog named jerrylinesRDD wordsRDD1 ['this', 'is', 'a', 'dog'] ['named', 'jerry'] toWords() toWords()
- 30. Basics of RDD FlatMap ● Very similar to Hadoop's Map() ● Can give out 0 or more records
- 31. Basics of RDD FlatMap ● Can emulate map as well as filter ● Can produce many as well as no value which empty array as output ○ If it give out single value, it behaves like map(). ○ If it gives out empty array, it behaves like filter.
- 32. Basics of RDD ➢ val arr = 1 to 10000 ➢ val nums = sc.parallelize(arr) ➢ def multiplyByTwo(x:Int) = Array(x*2) ➢ multiplyByTwo(5) Array(10) ➢ var dbls = nums.flatMap(multiplyByTwo); ➢ dbls.take(5) [2, 4, 6, 8, 10] flatMap as map
- 33. Basics of RDD flatMap as filter ➢ var arr = 1 to 1000 ➢ var nums = sc.parallelize(arr) ➢ def isEven(x:Int):Array[Int] = { ➢ if(x%2 == 0) Array(x) ➢ else Array() ➢ } ➢ var evens = nums.flatMap(isEven) ➢ evens.take(3) ➢ [2, 4, 6]
- 34. Basics of RDD Transformations:: Union ['1', '2', '3'] ➢ var a = sc.parallelize(Array('1','2','3')); ➢ var b = sc.parallelize(Array('A','B','C')); ➢ var c=a.union(b) ➢ Note: doesn't remove duplicates ➢ c.collect(); [1, 2, 3, 'A', 'B', 'C'] ['A','B','C']) ['1', '2', '3', 'A','B','C'] Union
- 35. Basics of RDD Transformations:: union() RDD lineage graph created during log analysis InputRDD errorsRDD warningsRDD badlinesRDD Filter Filter Union
- 36. Basics of RDD Saves all the elements into HDFS as text files. ➢ var a = sc.parallelize(Array(1,2,3, 4, 5 , 6, 7)); ➢ a.saveAsTextFile("myresult"); ➢ // Check the HDFS. ➢ //There should myresult folder in your home directory. Actions: saveAsTextFile() - Scala
- 37. Basics of RDD ➢ var a = sc.parallelize(Array(1,2,3, 4, 5 , 6, 7)); ➢ a org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[16] at parallelize at <console>:21 ➢ var localarray = a.collect(); ➢ localarray [1, 2, 3, 4, 5, 6, 7] Actions: collect() - Scala 1 2 3 4 5 6 7 Brings all the elements back to you. Data must fit into memory. Mostly it is impractical.
- 38. Basics of RDD ➢ var a = sc.parallelize(Array(1,2,3, 4, 5 , 6, 7)); ➢ var localarray = a.take(4); ➢ localarray [1, 2, 3, 4] Actions: take() - Scala 1 2 3 4 5 6 7 Bring only few elements to the driver. This is more practical than collect()
- 39. Basics of RDD ➢ var a = sc.parallelize(Array(1,2,3, 4, 5 , 6, 7), 3); ➢ var mycount = a.count(); ➢ mycount 7 Actions: count() - Scala 1, 2, 3 4,5 6,7 3 2 2 3+ 2 + 2 = 7 To find out how many elements are there in an RDD. Works in distributed fashion.
- 40. Basics of RDD More Actions - Reduce() ➢ var seq = sc.parallelize(1 to 100) ➢ def sum(x: Int, y:Int):Int = {return x+y} ➢ var total = seq.reduce(sum); total: Int = 5050 Aggregate elements of dataset using a function: • Takes 2 arguments and returns only one • Commutative and associative for parallelism • Return type of function has to be same as argument
- 41. Basics of RDD More Actions - Reduce()
- 42. Basics of RDD More Actions - Reduce() To confirm, you could use the formula for summation of natural numbers = n*(n+1)/2 = 100*101/2 = 5050
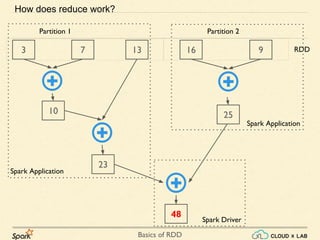
- 43. Basics of RDD 3 7 13 16 10 23 48 How does reduce work? 9 25 Partition 1 Partition 2 RDD Spark Driver Spark Application Spark Application
- 44. Basics of RDD Which is wrong. The correct average of 3, 7, 13, 16, 19 is 11.6. For avg(), can we use reduce? The way we had computed summation using reduce, Can we compute the average in the same way? ≫ var seq = sc.parallelize(Array(3.0, 7, 13, 16, 19)) ≫ def avg(x: Double, y:Double):Double = {return (x+y)/2} ≫ var total = seq.reduce(avg); total: Double = 9.875
- 45. Basics of RDD 3 7 13 16 5 9 10.75 Why average with reduce is wrong? 9 12.5 Partition 1 Partition 2 RDD
- 46. Basics of RDD Why average with reduce is wrong? !=
- 47. Basics of RDD But sum is ok = = =
- 48. Basics of RDD Reduce A reduce function must be commutative and associative otherwise the results could be unpredictable and wrong.
- 49. Basics of RDD Non Commutative Division 2 / 3 not eq 3 / 2 Subtraction 2 - 3 != 3 - 2 Exponent / power 4 ^ 2 != 2^4 Examples Addition 2 + 3 = 3 + 2 Multiplication 2 * 3 = 3*2 Average: (3+4+5)/3 = (4+3+5)/3 Euclidean Distance: = Commutative If changing the order of inputs does not make any difference to output, the function is commutative.
- 50. Basics of RDD Examples Multiplication: (3 * 4 ) * 2 = 3 * ( 4 * 2) Min: Min(Min(3,4), 30) = Min(3, Min(4, 30)) = 3 Max: Max(Max(3,4), 30) = Max(3, Min(4, 30)) = 30 Non Associative Division: (⅔) / 4 not equal to 2 / (¾) Subtraction: (2 - 3) - 1 != 2 - (3-1) Exponent / power: 4 ^ 2 != 2^4 Average: avg(avg(2, 3), 4) != avg(avg(2, 4), 3) Associative Associative property: Can add or multiply regardless of how the numbers are grouped. By 'grouped' we mean 'how you use parenthesis'.
- 51. Solving Some Problems with Spark
- 52. Basics of RDD What's wrong with this approach? Approach 1 - So, how to compute average? Approach 1 ➢ var rdd = sc.parallelize(Array(1.0,2,3, 4, 5 , 6, 7), 3); ➢ var avg = rdd.reduce(_ + _) / rdd.count(); We are computing RDD twice - during reduce and during count. Can we compute sum and count in a single reduce?
- 53. Basics of RDD Approach 2 - So, how to compute average? (Total1, Count1) (Total2, Count2) (Total1 + Total 2, Count1 + Count2) (4, 1) (5,1) (9, 2) 4 5 6 (6,1) (15, 3)15/3 = 5
- 54. Basics of RDD Approach 2 - So, how to compute average? ➢ var rdd = sc.parallelize(Array(1.0,2,3, 4, 5 , 6, 7), 3); ➢ var rdd_count = rdd.map((_, 1)) ➢ var (sum, count) = rdd_count.reduce((x, y) => (x._1 + y._1, x._2 + y._2)) ➢ var avg = sum / count avg: Double = 4.0 (Total1, Count1) (Total2, Count2) (Total1 + Total 2, Count1 + Count2)
- 55. Basics of RDD Comparision of the two approaches? Approach1: 0.023900 + 0.065180 = 0.08908 seconds ~ 89 ms Approach2: 0.058654 seconds ~ 58 ms Approximately 2X difference.
- 56. Basics of RDD How to compute Standard deviation?
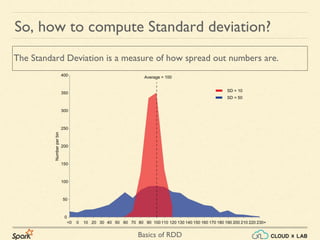
- 57. Basics of RDD So, how to compute Standard deviation? The Standard Deviation is a measure of how spread out numbers are.
- 58. Basics of RDD So, how to compute Standard deviation? The Standard Deviation is a measure of how spread out numbers are.
- 59. Basics of RDD So, how to compute Standard deviation? 1. Work out the Mean (the simple average of the numbers) The Standard Deviation is a measure of how spread out numbers are.
- 60. Basics of RDD So, how to compute Standard deviation? 1. Work out the Mean (the simple average of the numbers) 2. Then for each number: subtract the Mean and square the result The Standard Deviation is a measure of how spread out numbers are.
- 61. Basics of RDD 1. Work out the Mean (the simple average of the numbers) 2. Then for each number: subtract the Mean and square the result 3. Then work out the mean of those squared differences. So, how to compute Standard deviation? The Standard Deviation is a measure of how spread out numbers are.
- 62. Basics of RDD So, how to compute Standard deviation? 1. Work out the Mean (the simple average of the numbers) 2. Then for each number: subtract the Mean and square the result 3. Then work out the mean of those squared differences. 4. Take the square root of that and we are done! The Standard Deviation is a measure of how spread out numbers are.
- 63. Basics of RDD So, how to compute Standard deviation? Lets calculate SD of 2 3 5 6
- 64. Basics of RDD So, how to compute Standard deviation? Lets calculate SD of 2 3 5 6 Already Computed in Previous problem 1. Mean of numbers is μ = (2 + 3 + 5 + 6) / 4 => 4
- 65. Basics of RDD 1. Mean of numbers is μ = (2 + 3 + 5 + 6) / 4 => 4 2. xi - μ = (-2, -1, 1 , 2) 3. (xi - μ)2 = (4, 1, 1 , 4) So, how to compute Standard deviation? Lets calculate SD of 2 3 5 6 Already Computed in Previous problem Can be done using map()
- 66. Basics of RDD 1. Mean of numbers is μ = (2 + 3 + 5 + 6) / 4 => 4 2. xi - μ = (-2, -1, 1 , 2) 3. (xi - μ)2 = (4, 1, 1 , 4) 4. ∑(xi - μ)2 = 10 So, how to compute Standard deviation? Lets calculate SD of 2 3 5 6 Already Computed in Previous problem Can be done using map() Requires reduce.
- 67. Basics of RDD 1. Mean of numbers is μ = (2 + 3 + 5 + 6) / 4 => 4 2. xi - μ = (-2, -1, 1 , 2) 3. (xi - μ)2 = (4, 1, 1 , 4) 4. ∑(xi - μ)2 = 10 5. √1/N ∑(xi - μ)2 = √10/4 = √2.5 = 1.5811 So, how to compute Standard deviation? Lets calculate SD of 2 3 5 6 Already Computed in Previous problem Can be done using map() Requires reduce. Can be performed locally
- 68. Basics of RDD ➢ var rdd = sc.parallelize(Array(2, 3, 5, 6)) So, how to compute Standard deviation?
- 69. Basics of RDD ➢ var rdd = sc.parallelize(Array(2, 3, 5, 6)) //Mean or average of numbers is μ ➢ var rdd_count = rdd.map((_, 1)) ➢ var (sum, count) = rdd_count.reduce((x, y) => (x._1 + y._1, x._2 + y._2)) ➢ var avg = sum / count // (xi - μ)2 So, how to compute Standard deviation?
- 70. Basics of RDD So, how to compute Standard deviation? ➢ var rdd = sc.parallelize(Array(2, 3, 5, 6)) //Mean or average of numbers is μ ➢ var rdd_count = rdd.map((_, 1)) ➢ var (sum, count) = rdd_count.reduce((x, y) => (x._1 + y._1, x._2 + y._2)) ➢ var avg = sum / count // (xi - μ)2 ➢ var sqdiff = rdd.map( _ - avg).map(x => x*x)
- 71. Basics of RDD ➢ var rdd = sc.parallelize(Array(2, 3, 5, 6)) //Mean or average of numbers is μ ➢ var rdd_count = rdd.map((_, 1)) ➢ var (sum, count) = rdd_count.reduce((x, y) => (x._1 + y._1, x._2 + y._2)) ➢ var avg = sum / count // (xi - μ)2 ➢ var sqdiff = rdd.map( _ - avg).map(x => x*x) // ∑(xi - μ)2 ➢ var sum_sqdiff = sqdiff.reduce(_ + _) So, how to compute Standard deviation?
- 72. Basics of RDD So, how to compute Standard deviation? ➢ var rdd = sc.parallelize(Array(2, 3, 5, 6)) //Mean or average of numbers is μ ➢ var rdd_count = rdd.map((_, 1)) ➢ var (sum, count) = rdd_count.reduce((x, y) => (x._1 + y._1, x._2 + y._2)) ➢ var avg = sum / count // (xi - μ)2 ➢ var sqdiff = rdd.map( _ - avg).map(x => x*x) // ∑(xi - μ)2 ➢ var sum_sqdiff = sqdiff.reduce(_ + _) //√1/N ∑(xi - μ)2 ➢ import math._; ➢ var sd = sqrt(sum_sqdiff*1.0/count)
- 73. Basics of RDD So, how to compute Standard deviation? a. var rdd = sc.parallelize(Array(2, 3, 5, 6)) b. //Mean or average of numbers is μ i. var rdd_count = rdd.map((_, 1)) ii. var (sum, count) = rdd_count.reduce((x, y) => (x._1 + y._1, x._2 + y._2)) iii. var avg = sum / count c. // (xi - μ)2 d. var sqdiff = rdd.map( _ - avg).map(x => x*x) e. // ∑(xi - μ)2 f. var sum_sqdiff = sqdiff.reduce(_ + _) g. //√1/N ∑(xi - μ)2 h. import math._; i. var sd = sqrt(sum_sqdiff*1.0/count) 2. sd: Double = 1.5811388300841898
- 74. Basics of RDD Computing random sample from a dataset The objective of the exercise is to pick a random sample from huge data. Though there is a method provided in RDD but we are creating our own.
- 75. Basics of RDD 1. Lets try to understand it for say picking 50% records. Computing random sample from a dataset The objective of the exercise is to pick a random sample from huge data. Though there is a method provided in RDD but we are creating our own.
- 76. Basics of RDD 1. Lets try to understand it for say picking 50% records. 2. The approach is very simple. We pick a record from RDD and do a coin toss. If its head, keep the element otherwise discard it. It can be achieved using filter. Computing random sample from a dataset The objective of the exercise is to pick a random sample from huge data. Though there is a method provided in RDD but we are creating our own.
- 77. Basics of RDD Computing random sample from a dataset 1. Lets try to understand it for say picking 50% records. 2. The approach is very simple. We pick a record from RDD and do a coin toss. If its head, keep the element otherwise discard it. It can be achieved using filter. 3. For picking any fraction, we might use a coin having 100s of faces or in other words a random number generator. The objective of the exercise is to pick a random sample from huge data. Though there is a method provided in RDD but we are creating our own.
- 78. Basics of RDD Computing random sample from a dataset 1. Lets try to understand it for say picking 50% records. 2. The approach is very simple. We pick a record from RDD and do a coin toss. If its head, keep the element otherwise discard it. It can be achieved using filter. 3. For picking any fraction, we might use a coin having 100s of faces or in other words a random number generator. 4. Please notice that it would not give the sample of exact size The objective of the exercise is to pick a random sample from huge data. Though there is a method provided in RDD but we are creating our own.
- 79. Basics of RDD ➢ var rdd = sc.parallelize(1 to 1000); Computing random sample from a dataset
- 80. Basics of RDD ➢ var rdd = sc.parallelize(1 to 1000); ➢ var fraction = 0.1 Computing random sample from a dataset
- 81. Basics of RDD ➢ var rdd = sc.parallelize(1 to 1000); ➢ var fraction = 0.1 ➢ def cointoss(x:Int): Boolean = scala.util.Random.nextFloat() <= fraction Computing random sample from a dataset
- 82. Basics of RDD ➢ var rdd = sc.parallelize(1 to 1000); ➢ var fraction = 0.1 ➢ def cointoss(x:Int): Boolean = scala.util.Random.nextFloat() <= fraction ➢ var myrdd = rdd.filter(cointoss) Computing random sample from a dataset
- 83. Basics of RDD ➢ var rdd = sc.parallelize(1 to 1000); ➢ var fraction = 0.1 ➢ def cointoss(x:Int): Boolean = scala.util.Random.nextFloat() <= fraction ➢ var myrdd = rdd.filter(cointoss) ➢ var localsample = myrdd.collect() ➢ localsample.length Computing random sample from a dataset
- 84. Thank you! Basics of RDD