Apache Spark in Scientific Applications
Download as PPTX, PDF•0 likes•1,085 views

This document provides an overview of Apache Spark, including: - Apache Spark is a next generation data processing engine for Hadoop that allows for fast in-memory processing of huge distributed and heterogeneous datasets. - Spark offers tools for data science and components for data products and can be used for tasks like machine learning, graph processing, and streaming data analysis. - Spark improves on MapReduce by being faster, allowing parallel processing, and supporting interactive queries. It works on both standalone clusters and Hadoop clusters.






































Apache Spark in Scientific Applications
- 1. ‹#›© Cloudera, Inc. All rights reserved. Mirko Kämpf | 2015 Apache Spark: Next Generation Data Processing for Hadoop
- 2. ‹#›© Cloudera, Inc. All rights reserved. Agenda • The Data Science Process (DSP) - Why or when to use Spark • The role of: Apache Hadoop and Apache Spark - History & Hadoop Ecosystem • Apache Spark: Overview and Concepts • Practical Tips
- 3. ‹#›© Cloudera, Inc. All rights reserved. The Data Science Process Application of Big-Data-Technology Images from: http://semanticommunity.info/Data_Science/Doing_Data_Science
- 4. ‹#›© Cloudera, Inc. All rights reserved. Huge Data Sets in Science Application of Big-Data-Technology Images from: http://semanticommunity.info/Data_Science/Doing_Data_Science
- 5. ‹#›© Cloudera, Inc. All rights reserved. “Spark offers tools for Data Science and components for Data Products.” —How can Apache Spark fit into my world?
- 6. ‹#›© Cloudera, Inc. All rights reserved. Should I use Apache Spark? • If all my data fits into Excel-Spreadsheets? • If I have a special purpose application to work with? • If my current system is just a bit to slow?
- 7. ‹#›© Cloudera, Inc. All rights reserved. Should I use Apache Spark? • If all my data fits into Excel-Spreadsheets? • If I have a special purpose application to work with? • If my current system is just a bit to slow? • Just export as CSV / JSON and use a DataFrame to join with other DS. Why not?
- 8. ‹#›© Cloudera, Inc. All rights reserved. Should I use Apache Spark? • If all my data fits into Excel-Spreadsheets? • If I have a special purpose application to work with? • If my current system is just a bit to slow? • Just export as CSV / JSON and use a DataFrame to join with other DS. • Think about additional analysis methods! Maybe it is already built into Apache Spark! Why not?
- 9. ‹#›© Cloudera, Inc. All rights reserved. Should I use Apache Spark? • If all my data fits into Excel-Spreadsheets? • If I have a special purpose application to work with? • If my current system is just a bit to slow? • Just export as CSV / JSON and use a DataFrame to join with other DS. • Think about additional analysis methods! Maybe it is build into Spark. • OK, Spark will probably not help to speed up your system, but maybe you can offload data to Hadoop, which releases some resources. Why not?
- 10. ‹#›© Cloudera, Inc. All rights reserved. “Spark offers fast in memory processing on huge distributed and even on heterogeneous datasets.” —What type of data fits into Spark?
- 11. ‹#›© Cloudera, Inc. All rights reserved. History of Spark Spark is really young, but has a very active community!
- 12. ‹#›© Cloudera, Inc. All rights reserved. Timeline: Spark Adoption
- 13. ‹#›© Cloudera, Inc. All rights reserved. Apache Spark: Overview & Concepts
- 14. ‹#›© Cloudera, Inc. All rights reserved. Hadoop Ecosystem incl. Apache Spark Spark can be an entry point to your Big Data world …
- 15. ‹#›© Cloudera, Inc. All rights reserved. “Apache Spark is distributed on top of Hadoop and brings parallel processing to powerful workstations.” —Do I need a Hadoop cluster to work with Apache Spark?
- 16. ‹#›© Cloudera, Inc. All rights reserved. Spark vs. MapReduce
- 17. ‹#›© Cloudera, Inc. All rights reserved. How to interact with Spark?
- 18. ‹#›© Cloudera, Inc. All rights reserved. Spark Components
- 19. ‹#›© Cloudera, Inc. All rights reserved.
- 20. ‹#›© Cloudera, Inc. All rights reserved. MLLib: GraphX: Basic statistics summary statistics, correlations, stratified sampling, hypothesis testing, random data generation Classification and regression linear models (SVMs, logistic / linear regression) naive Bayes, decision trees ensembles of trees (Random Forests / Gradient-Boosted Trees) isotonic regression Collaborative filtering alternating least squares (ALS) Clustering k-means, Gaussian mixture, power iteration clustering (PIC) latent Dirichlet allocation (LDA), streaming k-means Dimensionality reduction singular value decomposition (SVD) principal component analysis (PCA) … PageRank Connected Components Triangle Counting Pregel API
- 21. ‹#›© Cloudera, Inc. All rights reserved. How to use your code in Spark? A. Interactively, by loading it into the spark-shell. B. Contribute to existing Spark projects. C. Create your module and use it in a spark-shell session. D. Build a data-product which uses Apache Spark. For simple and reliable usage of Java classes and complete third-party libraries, we define a Spark Module as a self-contained artifact created by Maven. This module can easily be shared by multiple users via repositories. http://blog.cloudera.com/blog/2015/03/how-to-build-re-usable-spark-programs-using-spark-shell-and-maven/
- 22. ‹#›© Cloudera, Inc. All rights reserved. Apache Spark: Overview & Concepts
- 23. ‹#›© Cloudera, Inc. All rights reserved. Spark Context
- 24. ‹#›© Cloudera, Inc. All rights reserved. RDDs and DataFrames
- 25. ‹#›© Cloudera, Inc. All rights reserved. Creation of RDDs
- 26. ‹#›© Cloudera, Inc. All rights reserved. Datatypes in RDDs
- 27. ‹#›© Cloudera, Inc. All rights reserved.
- 28. ‹#›© Cloudera, Inc. All rights reserved.
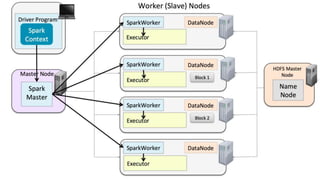
- 29. ‹#›© Cloudera, Inc. All rights reserved. Spark in a Cluster
- 30. ‹#›© Cloudera, Inc. All rights reserved. Spark in a Cluster
- 31. ‹#›© Cloudera, Inc. All rights reserved.
- 32. ‹#›© Cloudera, Inc. All rights reserved.
- 33. ‹#›© Cloudera, Inc. All rights reserved. DStream: The heart of Spark Streaming
- 34. ‹#›© Cloudera, Inc. All rights reserved. “Efficient hardware utilization, caching, simple APIs, and access to a variety of data in Hadoop is key to success.” —What makes Spark so different, compared to core MapReduce?
- 35. ‹#›© Cloudera, Inc. All rights reserved. Practical Tips
- 36. ‹#›© Cloudera, Inc. All rights reserved. Development Techniques • Build your tools and analysis procedures in small cycles. • Test all phases of your work and document carefully. • Document what you expect! => Requirements management … • Collect what you get! => Operational logs … • Reuse well tested components and modularize your analysis scripts. • Learn „state of the art“ tools and share your work!
- 37. ‹#›© Cloudera, Inc. All rights reserved. Data Management • Think about typical access patterns: • random access to each record or field? • access to entire groups of records? • variable size or fixed size sets? • „full table scan“ • OPTIMIZE FOR YOUR DOMINANT ACCESS PATTERN! • Select efficient storage formats: Avro, Parquet • Index your data in SOLR for random access and data exploration • Indexing can be done by just a few clicks in HUE …
- 38. ‹#›© Cloudera, Inc. All rights reserved. Collecting Sensor Data with Spark Streaming … • Spark Streaming works on fixed time slices only (in current version, 1.5) • Use the original time stamp? • Requires additional storage and bandwidth • Original system clock defines resolution • Use „Spark-Time“ or a local time reference: • You may lose information! • You have a limited resolution, defined by batch size.
- 39. ‹#›© Cloudera, Inc. All rights reserved. Thank you ! Enjoy Apache Spark and all your data …