




















![Copyright © 2016 NTT DATA Corporation
【DEMO】 WordCountみよう
val textFile = sc.textFile("CHANGES.txt")
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b)
=> a + b)
wordCounts.sortBy(_._2,false).take(10)
res0: Array[(String, Int)] = Array(("",61509), (Commit:,6830), (-0700,3672), (-0800,2162),
(in,1766), (to,1417), (for,1298), ([SQL],1277), (the,777), (and,663))
wordCounts.filter(_._1.matches("[a-zA-Z0-9]+")).sortBy(_._2,false).take(10)
res1: Array[(String, Int)] = Array((in,1766), (to,1417), (for,1298), (the,777), (and,663), (Add,631),
(of,630), (Fix,547), (Xin,491), (Reynold,490))
まずは簡単に、tgzを展開した直下にあるCHANGES.txtで試してみる
ちゃんとカウントできてるかな?数の多い上位10件を出力してみよう
ノイズが多いな…英数字のみ含まれる文字列のみフィルタしてみよう
spark-shellを起動し、Hadoop界隈のHello WorldであるWordCount実行
試行錯誤
できる](https://image.slidesharecdn.com/2016021803-160225013559/85/Apache-Spark-Apache-Spark-2016-22-320.jpg)



![Copyright © 2016 NTT DATA Corporation
【DEMO】キャッシュ機能を使ってみよう
wordCounts.cache()
wordCounts.filter(_._1.matches("[a-zA-Z0-9]+")).sortBy(_._2,false).take(10)
res1: Array[(String, Int)] = Array((in,1766), (to,1417), (for,1298), (the,777), (and,663), (Add,631),
(of,630), (Fix,547), (Xin,491), (Reynold,490))
wordCounts.filter(_._1.matches("[a-zA-Z0-9]+")).sortBy(_._2,false).take(10)
res1: Array[(String, Int)] = Array((in,1766), (to,1417), (for,1298), (the,777), (and,663), (Add,631),
(of,630), (Fix,547), (Xin,491), (Reynold,490))
.cache()でキャッシュ機能を有効化。(ここではキャッシュされない)
アクション契機に処理が実行され、データの実体がキャッシュに残る
WordCountの続き。先ほどのwordCountsを明示的にキャッシュしてみる
次にキャッシュされたRDDを対象とした処理を実行すると、キャッシュから
優先的にデータが読み込まれる。(キャッシュし切れなかったデータは、通
常通り計算されて求められる)](https://image.slidesharecdn.com/2016021803-160225013559/85/Apache-Spark-Apache-Spark-2016-27-320.jpg)
































Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
- 1. Copyright © 2016 NTT DATA Corporation NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス 土橋 昌 吉田 耕陽 Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~
- 2. Copyright © 2016 NTT DATA Corporation 自己紹介 土橋 昌 オープンソースを徹底活用してシステム開 発/運用するプロジェクト、R&Dに従事。 登壇歴 Spark Summit 2014、Hadoop Conference Japan、Strata + Hadoop Worldなど 執筆等 Spark関連の執筆では「Apache Spark入 門」や「初めてのSpark」付録、雑誌など 吉田 耕陽 入社以来、Hadoopをはじめとする分散処 理OSS関連の案件に従事。 登壇歴 Hadoop Conference Japan、OSCなど 執筆等 「Apache Spark入門」、デジタルプラクティ スなど
- 3. Copyright © 2016 NTT DATA Corporation 本日のおはなし Sparkのキホンを知って… Sparkアプリの書き方を知って… Sparkの中身を少しだけ知って… 大規模データ処理を少しでも身近に 感じて楽しんでいただければ嬉しいです
- 4. Copyright © 2016 NTT DATA Corporation 翔泳社「Apache Spark入門」について 第1章:Apache Sparkとは 第2章:Sparkの処理モデル 第3章:Sparkの導入 第4章:Sparkアプリケーションの開発と実行 第5章:基本的なAPIを用いたプログラミング 第6章:構造化データセットを処理する - Spark SQL - 第7章:ストリームデータを処理する - Spark Streaming - 第8章:機械学習を行う - MLlib - Appendix A. GraphXによるグラフ処理 B. SparkRを使ってみる C. 機械学習とストリーム処理の連携 D. Web UIの活用 ここで紹介する内容のもっと詳しい版が掲載されています。 Sparkの動作原理から標準ライブラリを使った具体的な プログラム例まで。 Spark1.5系 対応
- 5. Copyright © 2016 NTT DATA Corporation まず初めにApache Sparkとは? ひとことで言うと…オープンソースの並列分散処理系 並列分散処理の面倒な部分は処理系が解決してくれる! • 障害時のリカバリ • タスクの分割やスケジューリング • etc 大量のデータを たくさんのサーバを並べて 並列分散処理し、 現実的な時間(数分~数時間)で 目的の処理結果を得る データ管理には向きませんが、データ処理には向いています。
- 6. Copyright © 2016 NTT DATA Corporation 守備範囲の広い優等生ですが、あくまで分散処理系 いろいろ出来るので、ついうっかり分散処理でなくても良い処理も 実装しようとしがちですが、それはあまり筋が良くありません。 (そういう場合は分散のための仕組みは不要なものとなります) とはいえ、もちろん規模の小さなデータに対しても動きます。 現実的には実現したいことの全体の傾向によって Sparkを使うか、他の手段を組み合わせるのかを 判断して用います。
- 7. Copyright © 2016 NTT DATA Corporation では、うちではSpark使うべき?使わないべき? 自分にとって嬉しいかどうかは、 PoCなどを通じてちゃんと確かめましょう。 すでにHadoopを利用している 1台のマシンでは収まらない量のデータがある データ件数が多くて既存の仕組みだと一括処理が辛い SQLもいいが、他の言語の内部DSLとして実装したい 集計を中心としたストリーム処理をやりたい 大規模データに対して定番の機械学習アルゴリズムを適用したい できれば Sparkがあると嬉しい典型的なケース例
- 8. Copyright © 2016 NTT DATA Corporation とはいえ、試すのであれば簡単! http://spark.apache.org/downloads.html Demo JDKのインストールされた環境でパッケージを解凍して動かす Spark体験の始まり
- 9. Copyright © 2016 NTT DATA Corporation さて、ここでひとつ質問 なぜSparkが生まれたのか?
- 10. Copyright © 2016 NTT DATA Corporation さて、ここでひとつ質問 オープンソースの並列分散処理系としては、 既に Hadoop が普及しているけど? これで 良くない?
- 11. Copyright © 2016 NTT DATA Corporation さて、ここでひとつ質問 ものすごく簡単にHadoopの特徴をおさらいし、 Sparkが生まれた背景 を紐解きます 使ったことのない/使い始めのプロダクトに触れるときは重要
- 12. Copyright © 2016 NTT DATA Corporation Hadoopのあっさり紹介 Hadoop:コモディティなサーバを複数並べて分散処理 1. データを貯める HDFS 2. データ処理のリソースを管理する YARN 3. 処理する MapReduceフレームワーク
- 13. Copyright © 2016 NTT DATA Corporation Hadoopのあっさり紹介 Hadoop:コモディティなサーバを複数並べて分散処理 1. データを貯める HDFS 2. データ処理のリソースを管理する YARN 3. 処理する MapReduceフレームワーク Sparkは ここに相当
- 14. Copyright © 2016 NTT DATA Corporation (補足) MapReduceフレームワークとは アプリ開発者はMap処理とReduce処理を実装する(原則Java) 上記を元にフレームワークが分散処理する。障害発生時もリトライ で処理が継続する。 基本的にサーバを増やせば処理性能はスケールアウトする Map処理 Reduce処理 Map処理とReduce処理で完結したジョブを形成する データの加工や フィルタリングなど データの集計や 結合など HDFS HDFSと組み合わせるこ とで、I/Oが分散され、高 スループットで処理可能 HDFS 処理結果処理対象のデータ
- 15. Copyright © 2016 NTT DATA Corporation MapReduceフレームワークの嬉しい点をざっくりと シンプルな処理モデル 大量データでも動き切ってくれること 企業で使うのに 程良かったわけ ですね
- 16. Copyright © 2016 NTT DATA Corporation MapReduceフレームワークの課題 とはいえ、色々と使っていくと…処理効率が気になってきます ジョブが多段に構成される場合 複数のジョブで何度も同じデータを利用する場合 M R Map処理 Reduce処理 M R M R ・・・ ・・・ ・・・ ジョブ M R M R データの受け渡し
- 17. Copyright © 2016 NTT DATA Corporation 処理効率が気になる場面の例 ジョブが多段に 構成される場合 反復処理 •機械学習 •グラフ処理 複雑な 業務処理 複数のジョブで 何度も同じデータ を利用する場合 アドホックな 分析処理 複雑な 業務処理
- 18. Copyright © 2016 NTT DATA Corporation ジョブが多段に構成される場合の課題 ジョブ間でのデータの受け渡しのために、都度HDFSへのI/Oが発生 HDFSへの都度のI/Oのレイテンシが、処理時間の大部分を占めること につながる M R Map処理 Reduce処理 M R M R ・・・ ジョブ HDFS IO IOIO IO ジョブ間のデータの受け渡しのたびに、HDFSへのI/Oが伴う
- 19. Copyright © 2016 NTT DATA Corporation 複数のジョブで何度も同じデータを利用する場合の課題 何度も利用するデータを効率的に扱う仕組みがないため、同じデータを利用する 場合に都度巨大なデータの読み出しのための待ち時間が発生する ・・・ ・・・ M R M R ・・・M R ・・・M R HDFS ジョブごとに大きな データの読み込みの 待ち時間がかかる
- 20. Copyright © 2016 NTT DATA Corporation そこで生まれたSparkとは? 抽象化を進めて、スループットとレイテンシのバランス を追求し、使いやすいAPIをユーザに提供。 最新安定バージョンは1.6.0。現在2.0.0のリリースに向けて開発中 RDD RDD RDDRDD ユーザ定義の 処理の流れ フォーマット変換 グルーピング フィルター 集計入力 処理モデル RDDと呼ばれる部分故障への耐性を考慮した分散コレク ションに対し、典型的なデータ処理を繰り返して目的の 結果を得る
- 21. Copyright © 2016 NTT DATA Corporation Sparkのプログラミングモデルの基礎 RDDに対する処理は、コレクション操作のように記述 Scala / Java / Python向けのAPIが提供されている インタラクティブシェルが「試行錯誤」を加速する 都度のビルドが不要なため、ロジックの試作から効果の確認 のサイクルを高速化できる rdd.filter(...).map(...).reduceByKey(...).saveAsText(...) フィルタして 加工して 集計して 結果を保存
- 22. Copyright © 2016 NTT DATA Corporation 【DEMO】 WordCountみよう val textFile = sc.textFile("CHANGES.txt") val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordCounts.sortBy(_._2,false).take(10) res0: Array[(String, Int)] = Array(("",61509), (Commit:,6830), (-0700,3672), (-0800,2162), (in,1766), (to,1417), (for,1298), ([SQL],1277), (the,777), (and,663)) wordCounts.filter(_._1.matches("[a-zA-Z0-9]+")).sortBy(_._2,false).take(10) res1: Array[(String, Int)] = Array((in,1766), (to,1417), (for,1298), (the,777), (and,663), (Add,631), (of,630), (Fix,547), (Xin,491), (Reynold,490)) まずは簡単に、tgzを展開した直下にあるCHANGES.txtで試してみる ちゃんとカウントできてるかな?数の多い上位10件を出力してみよう ノイズが多いな…英数字のみ含まれる文字列のみフィルタしてみよう spark-shellを起動し、Hadoop界隈のHello WorldであるWordCount実行 試行錯誤 できる
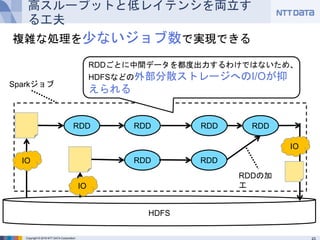
- 23. Copyright © 2016 NTT DATA Corporation 高スループットと低レイテンシを両立する工夫 複雑な処理を少ないジョブ数で実現できる RDD RDD RDDRDD RDD RDD Sparkジョブ RDDごとに中間データを都度出力するわけではないため、HDFS などの外部分散ストレージへのI/Oが抑えられる HDFS IO IO IO RDDの加工
- 24. Copyright © 2016 NTT DATA Corporation 【DEMO】ウェブUIからジョブの構成を確認 WordCount(takeで上位10件確認まで)を実行するときのDAG 実際に実行される処理は 「ステージ」を軸に構成され、 「タスク」として計算マシンで 実行される
- 25. Copyright © 2016 NTT DATA Corporation 高スループットと低レイテンシを両立する工夫 何度も利用するRDDは、複数のサーバのメモリに分割して キャッシュしてI/Oや計算を減らせる RDDRDD ジョブA RDD HDFS RDD ジョブBはジョブAがキャッシュ したデータを利用できる RDD RDD RDD ジョブB キャッシュを活用することで、同じデータを利用する場合でも、 都度データを読み込む必要がない キャッシュ済みのRDD キャッシュを利用できるので、 HDFSからのデータの読み込 みは発生しない
- 26. Copyright © 2016 NTT DATA Corporation 高スループットと低レイテンシを両立する工夫 キャッシュは反復処理にも有効 RDD RDD RDD 前段の反復処理の結果を 入力とするジョブ キャッシュ済みのRDD 2回目の反復以降は、 キャッシュしたRDDを 処理すれば良い。HDFS 最初の反復のみ、 HDFSからデータ を読み出す
- 27. Copyright © 2016 NTT DATA Corporation 【DEMO】キャッシュ機能を使ってみよう wordCounts.cache() wordCounts.filter(_._1.matches("[a-zA-Z0-9]+")).sortBy(_._2,false).take(10) res1: Array[(String, Int)] = Array((in,1766), (to,1417), (for,1298), (the,777), (and,663), (Add,631), (of,630), (Fix,547), (Xin,491), (Reynold,490)) wordCounts.filter(_._1.matches("[a-zA-Z0-9]+")).sortBy(_._2,false).take(10) res1: Array[(String, Int)] = Array((in,1766), (to,1417), (for,1298), (the,777), (and,663), (Add,631), (of,630), (Fix,547), (Xin,491), (Reynold,490)) .cache()でキャッシュ機能を有効化。(ここではキャッシュされない) アクション契機に処理が実行され、データの実体がキャッシュに残る WordCountの続き。先ほどのwordCountsを明示的にキャッシュしてみる 次にキャッシュされたRDDを対象とした処理を実行すると、キャッシュから 優先的にデータが読み込まれる。(キャッシュし切れなかったデータは、通 常通り計算されて求められる)
- 28. Copyright © 2016 NTT DATA Corporation 【DEMO】キャッシュされたデータの様子 キャッシュの状況は、WebUIのStorageタブから確認できる
- 29. Copyright © 2016 NTT DATA Corporation データソース(HDFSなど) 速いだけじゃないSparkの豊富な機能 http://cdn.oreillystatic.com/en/assets/1/event/126/Apache%20Spark_%20What_s%20new_%20what_s%20coming%20Presentation.pdf SQL
- 30. Copyright © 2016 NTT DATA Corporation データソース(HDFSなど) 速いだけじゃないSparkの豊富な機能 http://cdn.oreillystatic.com/en/assets/1/event/126/Apache%20Spark_%20What_s%20new_%20what_s%20coming%20Presentation.pdf SQL 分散処理エンジンを含むコア部分
- 31. Copyright © 2016 NTT DATA Corporation データソース(HDFSなど) 速いだけじゃないSparkの豊富な機能 • 機械学習などの複雑な処理を簡単に実現するための 標準ライブラリ http://cdn.oreillystatic.com/en/assets/1/event/126/Apache%20Spark_%20What_s%20new_%20what_s%20coming%20Presentation.pdf SQL
- 32. Copyright © 2016 NTT DATA Corporation データソース(HDFSなど) 速いだけじゃないSparkの豊富な機能 • 例えばScala/Java/Python/SQL等で処理が記述可能 • インタラクティブシェルが付属し、試行錯誤も可能 http://cdn.oreillystatic.com/en/assets/1/event/126/Apache%20Spark_%20What_s%20new_%20what_s%20coming%20Presentation.pdf SQL
- 33. Copyright © 2016 NTT DATA Corporation データソース(HDFSなど) 速いだけじゃないSparkの豊富な機能 http://cdn.oreillystatic.com/en/assets/1/event/126/Apache%20Spark_%20What_s%20new_%20what_s%20coming%20Presentation.pdf SQL • YARNなどのクラスタ管理基盤と連係動作する • すでにHadoop環境がある場合は特に導入簡単
- 34. Copyright © 2016 NTT DATA Corporation データソース(HDFSなど) 速いだけじゃないSparkの豊富な機能 http://cdn.oreillystatic.com/en/assets/1/event/126/Apache%20Spark_%20What_s%20new_%20what_s%20coming%20Presentation.pdf SQL • データソースの分散ファイルシステムにはHDFSも利用可能 • 従来MapReduceで実装していた処理をSparkにマイグレーションしやすい
- 35. Copyright © 2016 NTT DATA Corporation 便利なライブラリ: Spark SQL DataFrameに対してSQL/HiveQLを発行して分散処理する └ RDDの上に成り立つスキーマ付きのテーブル状のデータ構造 SQLを使い慣れたデータ分析者担当者が分散処理の恩恵を受けられる // ScalaでSQLを使用する例 Val teenager = sqlContext.sql(“SELECT name FROM people WHERE age >= 13 AND age <= 19”) 例えばPythonによるデータ分析アプリケーションを実装していて、 「ここはSQLで書きたいな」って箇所で有用。
- 36. Copyright © 2016 NTT DATA Corporation 便利なライブラリ: Spark SQL オプティマイザ付き RDDベースの処理の物理プランが生成される 構造化データを取り扱うための仕組みが付属 – Parquet / ORC / CSV / JSON / テキスト / JDBC ... – データソースによってはフィルタ処理をデータソース側に移譲することで、 無駄なデータの読み込みを避けられる http://cdn.oreillystatic.com/en/assets/1/event/126/Apache%20Spark_%20What_s%20new_%20what_s%20coming%20Presentation.pdf オペレータの実行順序の 最適化など データソースの特性を活用した 最適化など
- 37. Copyright © 2016 NTT DATA Corporation 【DEMO】SQLによる処理を実行してみる case class Person(name: String, age: Int) val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF() people.registerTempTable("people") val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19").show サンプルに含まれるデータで、SparkSQLを試してみる 参考 : http://spark.apache.org/docs/latest/sql-programming-guide.html
- 38. Copyright © 2016 NTT DATA Corporation 便利なライブラリ: MLlib / ML Pipelines 統計処理、機械学習を分散処理するためのライブラリ レコメンデーション / 分類 / 予測など 分散処理に向くポピュラーなアルゴリズムを提供 2016/2現在、spark.mllib と spark.ml の2種類のパッケージが存在 (一例) RDD利用 DataFrame利用
- 39. Copyright © 2016 NTT DATA Corporation 便利なライブラリ: MLlib / ML Pipelines 昨今はspark.mlのML Pipelinesの開発が活発 scikit-learnのように機械学習を含む処理全体をパイプラインとして扱うAPI val tokenizer = new Tokenizer() .setInputCol("text") .setOutputCol("words") val hashingTF = new HashingTF() .setNumFeatures(1000) .setInputCol(tokenizer.getOutputCol) .setOutputCol("features") val lr = new LogisticRegression() .setMaxIter(10) .setRegParam(0.01) // パイプラインにトークン分割、ハッシュ化、処理とロジスティック回帰を設定 val pipeline = new Pipeline().setStages(Array(tokenizer, hashingTF, lr)) val model = pipeline.fit(trainingDataset) // モデルの当てはめ 処理全体のポータビリティ向上! 見通しの良くなって開発効率の向上!
- 40. Copyright © 2016 NTT DATA Corporation 【DEMO】K-meansによるカテゴライズ import org.apache.spark.mllib.clustering.KMeans import org.apache.spark.mllib.linalg.Vectors val data = sc.textFile("data/mllib/kmeans_data.txt") val parsedData = data.map { s => Vectors.dense(s.split(' ').map(_.toDouble)) }.cache() val numClusters = 2 val numIterations = 20 val clusters = KMeans.train(parsedData, numClusters, numIterations) // 確認 clusters.k clusters.clusterCenters // 入力データのベクトルが所属するクラスタを出力 parsedData.foreach{ vec => println(vec + " => " + clusters.predict(vec)) } サンプルに含まれるサンプルデータでK-meansを試してみる
- 41. Copyright © 2016 NTT DATA Corporation 便利なライブラリ: Spark Streaming 小さなバッチ処理を繰り返してストリーミング処理を実現 ストリーム処理用のスケジューラが以下の流れを繰り返し実行。実際 のデータ処理はSparkの機能で実現。 http://spark.incubator.apache.org/docs/latest/streaming-programming-guide.html ストリームデータ を小さく区切って 取りこむ 区切った塊(バッチ)に対してマイクロバッチ処理を適用する
- 42. Copyright © 2016 NTT DATA Corporation 便利なライブラリ: Spark Streaming 特に向いているケース 集計を中心とした処理 バッチ処理と共通の処理 ある程度のウィンドウ幅でスループットも重視する処理
- 43. Copyright © 2016 NTT DATA Corporation 【DEMO】 Twitterのハッシュタグフィルタリング import org.apache.spark.streaming.twitter.TwitterUtils import org.apache.spark.streaming.{Durations, StreamingContext} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.log4j.{Level, Logger} Logger.getRootLogger.setLevel(Level.ERROR) $./bin/spark-shell --jars lib/spark-examples-1.6.0-hadoop2.6.0.jar Localモードで本コードを動作させると多くのWARNが出力され見づらくなるた め、ログレベルをErrorレベルに変更 SparkStreamingでお手軽にTwitterデータを使ってみる Twitter用のライブラリ(org.apache.spark.streaming.twitter.TwitterUtils)を利用するが SparkのJarには含まれないため、デモではお手軽にサンプルプログラムのjarファイルを読 み込ませて実行
- 44. Copyright © 2016 NTT DATA Corporation 【DEMO】 Twitterのハッシュタグフィルタリング val config = new java.util.Properties config.load(this.getClass().getClassLoader().getResourceAsStream("config.properties")) System.setProperty("twitter4j.oauth.consumerKey", config.get("twitter_consumerKey").toString) System.setProperty("twitter4j.oauth.consumerSecret", config.get("twitter_consumerSecret").toString) System.setProperty("twitter4j.oauth.accessToken", config.get("twitter_accessToken").toString) System.setProperty("twitter4j.oauth.accessTokenSecret", config.get("twitter_accessTokenSecret").toString) val filters = Array("#devsumi") val ssc = new StreamingContext(sc, Seconds(10)) val stream = TwitterUtils.createStream(ssc, None, filters) //Tweet本文のみ出力 stream.map(status => status.getText()).print ssc.start() ssc.awaitTermination() ------------------------------------------- Time: 1455770400000 ms ------------------------------------------- #devsumi デモなう 検索ワードを入れる 前ページの続き 10秒に1回のマイクロバッチ デモではTwitter API Keyは外部ファイルとして準備 この後にも様々な処理を追加できます
- 45. Copyright © 2016 NTT DATA Corporation 翔泳社「Apache Spark入門」について 第1章:Apache Sparkとは 第2章:Sparkの処理モデル 第3章:Sparkの導入 第4章:Sparkアプリケーションの開発と実行 第5章:基本的なAPIを用いたプログラミング 第6章:構造化データセットを処理する - Spark SQL - 第7章:ストリームデータを処理する - Spark Streaming - 第8章:機械学習を行う - MLlib - Appendix A. GraphXによるグラフ処理 B. SparkRを使ってみる C. 機械学習とストリーム処理の連携 D. Web UIの活用 ここで紹介した内容のもっと詳しい版が掲載されています。 Sparkの動作原理から標準ライブラリを使った具体的な プログラム例まで。 Spark1.5系 対応
- 46. Copyright © 2016 NTT DATA Corporation 46 イマドキのSpark
- 47. Copyright © 2016 NTT DATA Corporation 劇的な進化を遂げつづけるSpark RDDを基礎とした分散処理、豊富で便利なライブラリ群の存在など の基本コンセプトは変わらないが、決して進化を止めていない。 特に2014年から2016年に向けて、Sparkの常識が変化。 2014年~2015年にユーザ、開発者が色々と言っていた 不満の多くが考慮されているのは興味深いです。 過去のカンファレンスのネタなどを振り返ると面白いです。
- 48. Copyright © 2016 NTT DATA Corporation イマドキのSpark フロントエンド バックエンド RDDを中心とした処理系から、 DataFrameを中心とした ハイレベルの処理系へ Project Tungstenと 題されるCPU利用効率 の改善
- 49. Copyright © 2016 NTT DATA Corporation イマドキのSpark フロントエンド バックエンド RDDを中心とした処理系から、 DataFrameを中心とした ハイレベルの処理系へ Project Tungstenと 題されるCPU利用効率 の改善
- 50. Copyright © 2016 NTT DATA Corporation RDDのAPIは直感的だが、規模が大きくなり、複雑になると・・・ 見通しが悪い? 最適化が面倒? よりハイレベルのAPIがほしい RDDベースの処理の場合、言語によってバックエンドの処理系が異なるため、 言語によってパフォーマンスが異なる RDDベースの処理の課題 どこに何が入ってい るんだ?! Pythonのデーモン内で 処理が実行される
- 51. Copyright © 2016 NTT DATA Corporation DataFrame API DataFrameに対してSQLを発行できるだけではなく、DataFrame APIと呼ばれるデータ処理用のAPI 構造化データの処理を簡潔に記述 http://cdn.oreillystatic.com/en/assets/1/event/126/Apache%20Spark_%20What_s%20new_%20what_s%20coming%20Presentation.pdf これが… こうなる!これは簡潔!
- 52. Copyright © 2016 NTT DATA Corporation DataFrame API しかも速い。Spark SQLのオプティマイザの恩恵 オプティマイザによってJVMで動作する物理プランが生成されるため、 開発言語の違いによる著しい性能劣化は起こらない http://www.slideshare.net/databricks/introducing-dataframes-in-spark-for-large-scale-data-science
- 53. Copyright © 2016 NTT DATA Corporation お手軽にcsvファイルをDataFrameとして利用するために、デモではspark-csvを利用。 Spark Packagesのリポジトリに存在するため--packagesオプションで指定。 ※spark-csvは、Spark2.0以降よりビルトインのライブラリとして利用可能 【DEMO】 DataFrame APIを使ってみる val df = sqlContext.read.format("com.databricks.spark.csv").option("header", "true").option("inferSchema", "true").load(”/tmp/weather.csv") df.show df.schema // 雪が降った日は何日? df.filter(df("降雪量合計(cm)") > 0).count // 最高気温、最適気温の平均は? df.agg(avg("最高気温(℃)"),avg("最低気温(℃)")).show $ spark-shell --packages com.databricks:spark-csv_2.11:1.3.0 気象庁のオープンデータを元にしたcsvファイルを利用
- 54. Copyright © 2016 NTT DATA Corporation イマドキのSpark フロントエンド バックエンド RDDを中心とした処理系から、 DataFrameを中心とした ハイレベルの処理系へ Project Tungstenと 題されるCPU利用効率 の改善
- 55. Copyright © 2016 NTT DATA Corporation 様々な要因により、ボトルネックのトレンドがCPUに Spark自体のアーキテクチャの改良 •スケーラビリティ重視のシャッフルロジック(ソートベースシャッフル) •ネットワーク越しにデータを転送する際のメモリコピー回数の削減 (Netty) DataFrameをベースとした処理の最適化 •I/Oの削減 •処理の最適化 昨今のハードウェアトレンドの変化 •SSDや高スループットのネットワークの利用が広がってきた •一方でCPUのクロック数は頭打ち
- 56. Copyright © 2016 NTT DATA Corporation Project Tungsten 独自のメモリ管理 メモリ利用効率の 向上 無駄な中間 オブジェクト生成の 回避 GCの削減 HWキャッシュを考 慮したデータレイ アウト メモリアクセスの 待ち時間の削減 コードの動的生成 条件分岐の削減 ボクシング / アン ボクシングによる オブジェクト生成の 削減 バーチャルメソッド コールの回数の 削減 SparkのCPU利用効率を改善するための工夫
- 57. Copyright © 2016 NTT DATA Corporation Spark 2.0 at Spark Summit East Spark Summit EastがNYCで実施されています。 Mateiの講演より。 http://www.slideshare.net/databricks/2016-spark-summit-east-keynote-matei-zaharia
- 58. Copyright © 2016 NTT DATA Corporation まとめ Sparkは分散処理をいかに効率的に実装・実行 するか?を追求している 実行エンジン/インターフェースの工夫がたくさん => RDD、DataFrame、Project Tungsten 優等生的に様々な処理に標準対応 => MLlib、Spark Streaming、Spark SQL、GraphX 抽象化されていることを生かし、ユースケースや ハードウェアのトレンドを考慮して進化
- 59. Copyright © 2016 NTT DATA Corporation Hadoop/Sparkのことなら、NTTデータにお任せくだ さい お問い合わせ先: 株式会社NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス URL: http://oss.nttdata.co.jp/hadoop メール: [email protected] TEL: 050-5546-2496
- 60. Copyright © 2011 NTT DATA Corporation Copyright © 2016 NTT DATA Corporation