Apache Spark on Supercomputers: A Tale of the Storage Hierarchy with Costin Iancu and Nicholas Chaimov
1 like205 views

This document discusses the performance optimization of Apache Spark on high-performance computing (HPC) systems, emphasizing the impact of storage hierarchy, network latency, and I/O operations. It highlights the need for strategies like keeping files open to improve I/O performance and the use of containers for better resource management. The findings indicate that while latency and bandwidth are important, variability and network time are more critical at scale.



























Apache Spark on Supercomputers: A Tale of the Storage Hierarchy with Costin Iancu and Nicholas Chaimov
- 1. Costin Iancu, Khaled Ibrahim – LBNL Nicholas Chaimov – U. Oregon Spark on Supercomputers: A Tale of the Storage Hierarchy
- 2. Apache Spark • Developed for cloud environments • Specialized runtime provides for – Performance J, Elastic parallelism, Resilience • Programming productivity through – HLL front-ends (Scala, R, SQL), multiple domain-specific libraries: Streaming, SparkSQL, SparkR, GraphX, Splash, MLLib, Velox • We have huge datasets but little penetration in HPC
- 3. Apache Spark • In-memory Map-Reduce framework • Central abstraction is the Resilient Distributed Dataset. • Data movement is important – Lazy, on-demand – Horizontal (node-to-node) – shuffle/Reduce – Vertical (node-to-storage) - Map/Reduce p1 p2 p3 textFile p1 p2 p3 flatMap p1 p2 p3 map p1 p2 p3 reduceByKey (local) STAGE 0 p1 p2 p3 reduceByKey (global) STAGE 1 JOB 0
- 4. Data Centers/Clouds Node local storage, assumes all disk operations are equal Disk I/O optimized for latency Network optimized for bandwidth HPC Global file system, asymmetry expected Disk I/O optimized for bandwidth Network optimized for latency
- 5. HDD/ SSD NIC CPU Mem HDD/ SDD HDD/ SDD HDD/ SDD CPU Mem NIC HDD/ SDD HDD/ SSD HDD/ SSD HDD/ SSD HDD /SSD Cloud: commodity CPU, memory, HDD/SSD NIC Data appliance: server CPU, large fast memory, fast SSD Backend storage Intermediate storage HPC: server CPU, fast memory, combo of fast and slower storage
- 6. HDD/ SSD NIC CPU Mem HDD/ SDD HDD/ SDD HDD/ SDD CPU Mem NIC HDD/ SDD HDD/ SSD HDD/ SSD HDD/ SSD HDD /SSD Backend storage Intermediate storage 2.5 GHz Intel Haswell - 24 cores 2.3 GHz Intel Haswell – 32 cores 128GB/1.5TB DDR4 128GB DDR4 320 GB of SSD local 56 Gbps FDR InfiniBand Cray Data Warp 1.8PB at 1.7TB/s Sonexion Lustre 30PB Cray Aries Comet (DELL) Cori (Cray XC40)
- 7. Scaling Spark on Cray XC40 (It’s all about file system metadata)
- 8. Not ALL I/O is Created Equal 0 2000 4000 6000 8000 10000 12000 1 2 4 8 16 Time Per Opera1on (microseconds) Nodes GroupByTest - I/O Components - Cori Lustre - Open BB Striped - Open BB Private - Open Lustre - Read BB Striped - Read BB Private - Read Lustre - Write BB Striped - Write # Shuffle opens = # Shuffle reads O(cores2) Time per open increases with scale, unlike read/write 9,216 36,864 147,456 589,824 2,359,296 opens
- 9. I/O Variability is HIGH fopen is a problem: • Mean time is 23X larger than SSD • Variability is 14,000X READ fopen
- 10. Improving I/O Performance Eliminate file metadata operations 1. Keep files open (cache fopen) • Surprising 10%-20% improvement on data appliance • Argues for user level file systems, gets rid of serialized system calls 2. Use file system backed by single Lustre file for shuffle • This should also help on systems with local SSDs 3. Use containers • Speeds up startup, up to 20% end-to-end performance improvement • Solutions need to be used in conjunction – E.g. fopen from Parquet reader Plenty of details in “Scaling Spark on HPC Systems”. HPDC 2016
- 11. 0 100 200 300 400 500 600 700 32 160 320 640 1280 2560 5120 10240 Time (s) Cores Cori - GroupBy - Weak Scaling - Time to Job Completion Ramdisk Mounted File Lustre Scalability 6x 12x 14x 19x 33x 61x At 10,240 cores only 1.6x slower than RAMdisk (in memory execution) We scaled Spark from O(100) up to O(10,000) cores
- 12. File-Backed Filesystems • NERSC Shifter (container infrastructure for HPC) – Compatible with Docker images – Integrated with Slurm scheduler – Can control mounting of filesystems within container • Per-Node Cache – File-backed filesystem mounted within each node’s container instance at common path (/mnt) – --volume=$SCRATCH/backingFile:/mnt:perNodeCache= size=100G – File for each node is created stored on backend Lustre filesystem – Single file open — intermediate data file opens are kept local
- 13. Now the fun part J Architectural Performance Considerations Cori Comet The Supercomputer vs The Data Appliance
- 14. HDD/ SSD NIC CPU Mem HDD/ SDD HDD/ SDD HDD/ SDD CPU Mem NIC HDD/ SDD HDD/ SSD HDD/ SSD HDD/ SSD HDD /SSD Backend storage Intermediate storage 2.5 GHz Intel Haswell - 24 cores 2.3 GHz Intel Haswell – 32 cores 128GB/1.5TB DDR4 128GB DDR4 320 GB of SSD local 56 Gbps FDR InfiniBand Cray Data Warp 1.8PB at 1.7TB/s Sonexion Lustre 30PB Cray Aries Comet (DELL) Cori (Cray XC40)
- 15. CPU, Memory, Network, Disk? • Multiple extensions to Blocked Time Analysis (Ousterhout, 2015) • BTA indicated that CPU dominates – Network 2%, disk 19% • Concentrate on scaling out, weak scaling studies – Spark-perf, BigDataBenchmark, TPC-DS, TeraSort • Interested in determining right ratio, machine balance for – CPU, memory, network, disk … • Spark 2.0.2 & Spark-RDMA 0.9.4 from Ohio State University, Hadoop 2.6
- 16. Storage hierarchy and performance
- 17. Global Storage Matches Local Storage 0 20000 40000 60000 80000 100000 120000 140000 160000 180000 200000 Lustre Mount+Pool SSD+IB Lustre Mount+Pool SSD+IB Lustre Mount+Pool SSD+IB 1 5 20 Time (ms) Nodes (32 cores) App JVM RW Input RW Shuffle Open Input Open Shuffle • Variability matters more than advertised latency and bandwidth number • Storage performance obscured/mitigated by network due to client/server in BlockManager • Small scale local is slightly faster • Large scale global is faster Disk+Network Latency/BW Metadata Overhead Cray XC40 – TeraSort (100GB/node)
- 18. 0 0.2 0.4 0.6 0.8 1 1.2 1 16 1 16 Comet RDMA Singularity 24 Cores Cori Shifter 24 Cores Average Across MLLib Benchmarks App Fetch JVM Global Storage Matches Local Storage 11.8% Fetch 12.5% Fetch
- 19. Intermediate Storage Hurts Performance 0 2000 4000 6000 8000 10000 12000 14000 1 2 4 8 16 32 64 1 2 4 8 16 32 64 1 2 4 8 16 32 64 Cori Shifter Lustre Cori Shifter BB Striped Cori Shifter BB Private Time (s) TPC-DS - Weak Scaling App Fetch JVM 19.4% slower on average 86.8% slower on average (Without our optimizations, intermediate storage scaled better)
- 21. 0 50 100 150 200 250 300 350 1 2 4 8 16 32 64 1 2 4 8 16 32 64 1 2 4 8 16 32 64 Comet Singularity Comet RDMA Singularity Cori Shifter 24 cores Time (s) Singular Value Decomposition App Fetch JVM Latency or Bandwidth? 10X in bandwidth, latency differences matter Can hide 2X differences Average message size for spark-perf is 43B
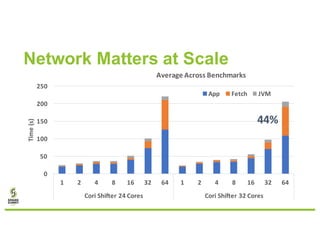
- 22. Network Matters at Scale 0 50 100 150 200 250 1 2 4 8 16 32 64 1 2 4 8 16 32 64 Cori Shifter 24 Cores Cori Shifter 32 Cores Time (s) Average Across Benchmarks App Fetch JVM 44%
- 23. CPU
- 24. More cores or better memory? • Need more cores to hide disk and network latency at scale. • Preliminary experiences with Intel KNL are bad • Too much concurrency • Not enough integer throughput • Execution does not seem to be memory bandwidth limited 0 50 100 150 200 250 1 2 4 8 16 32 64 1 2 4 8 16 32 64 Cori Shifter 24 Cores Cori Shifter 32 Cores Time (s) Average Across Benchmarks App Fetch JVM
- 25. Summary/Conclusions • Latency and bandwidth are important, but not dominant – Variability more important than marketing numbers • Network time dominates at scale – Network, disk is mis-attributed as CPU • Comet matches Cori up to 512 cores, Cori twice as fast at 2048 cores – Spark can run well on global storage • Global storage opens the possibility of global name space, no more client-server
- 26. Ackowledgement Work partially supported by Intel Parallel Computing Center: Big Data Support for HPC
- 27. Thank You. Questions, collaborations, free software [email protected] [email protected] [email protected]
- 28. Burst Buffer Setup • Cray XC30 at NERSC (Edison): 2.4 GHz IvyBridge - Global • Cray XC40 at NERSC (Cori): 2.3 GHz Haswell + Cray DataWarp • Comet at SDSC: 2.5GHz Haswell, InfiniBand FDR, 320 GB SSD, 1.5TB memory - LOCAL