Apache Spark Overview part2 (20161117)
7 likes1,260 views

Spark Streaming allows for scalable, high-throughput, fault-tolerant stream processing of live data streams. It works by chopping data streams into batches, treating each batch as an RDD, and processing them using RDD transformations and operations. This provides a simple abstraction called a DStream that represents a continuous stream of data as a series of RDDs. Transformations applied to DStreams are similarly applied to the underlying RDDs. Spark Streaming also supports window operations, output operations, and integrating streaming with Spark's ML and graph processing capabilities.







![DStream Transformation
• Any operation applied on a DStream translates to opeartions on the
underlying RDDs.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-8-320.jpg)

![Transformations on DStreams
Transformation Meaning
countByValue() When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where
the value of each key is its frequency in each RDD of the source DStream.
reduceByKey
(func, [numTasks])
When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values
for each key are aggregated using the given reduce function. Note: By default, this uses Spark's
default number of parallel tasks (2 for local mode, and in cluster mode the number is
determined by the config property spark.default.parallelism) to do the grouping. You can pass
an optional numTasks argument to set a different number of tasks.
Join
(otherStream, [numTasks])
When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W))
pairs with all pairs of elements for each key.
Cogroup
(otherStream, [numTasks])
When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V],
Seq[W]) tuples.
transform(func) Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream.
This can be used to do arbitrary RDD operations on the DStream.
updateStateByKey(func) Return a new "state" DStream where the state for each key is updated by applying the given
function on the previous state of the key and the new values for the key. This can be used to
maintain arbitrary state data for each key.](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-10-320.jpg)

![Receivers – Advanced Sources
Source Artifact
Kafka spark-streaming-kafka_2.10
Flume spark-streaming-flume_2.10
Kinesis spark-streaming-kinesis-asl_2.10 [Amazon Software License]
Twitter spark-streaming-twitter_2.10
ZeroMQ spark-streaming-zeromq_2.10
MQTT spark-streaming-mqtt_2.10
https://spark.apache.org/docs/1.6.2/streaming-programming-guide.html](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-12-320.jpg)
![Example: Word Count with Kafka
object WordCount {
def main(args: Array[String]) {
val context = new StreamingContext(conf, Seconds(1))
val lines = KafkaUtils.createStream(context,...)
val words = lines.flatMap(_.split(“ "))
val wordCounts = words.map( x => (x, 1))
.reduceByKey(_ + _)
wordCounts.print()
context.start()
context.awaitTermination()
}
}](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-13-320.jpg)

![Window Operations
Transformation Meaning
window(windowLength, slideInterval) Return a new DStream which is computed based on windowed batches of the
source DStream.
countByWindow
(windowLength, slideInterval)
Return a sliding window count of elements in the stream.
reduceByWindow
(func, windowLength, slideInterval)
Return a new single-element stream, created by aggregating elements in the
stream over a sliding interval using func. The function should be associative so
that it can be computed correctly in parallel.
reduceByKeyAndWindow
(func, windowLength, slideInterval,
[numTasks])
When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs
where the values for each key are aggregated using the given reduce
function func over batches in a sliding window.
reduceByKeyAndWindow
(func, invFunc, windowLength, slideInterval,
[numTasks])
A more efficient version of the above reduceByKeyAndWindow() where the
reduce value of each window is calculated incrementally using the reduce values
of the previous window.
countByValueAndWindow
(windowLength,slideInterval, [numTasks])
When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long)
pairs where the value of each key is its frequency within a sliding window.](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-15-320.jpg)

![Output Operations on DStreams
Output operations allow Dstream’s data to be pushed out to external
systems like a database or a file systems.
Output Operation Meaning
print() Prints the first ten elements of every batch of data in a DStream on the driver node
running the streaming application. This is useful for development and debugging.
saveAsTextFiles(prefix, [suffix]) Save this DStream's contents as text files. The file name at each batch interval is
generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".
saveAsObjectFiles(prefix, [suffix]) Save this DStream's contents as SequenceFiles of serialized Java objects. The file
name at each batch interval is generated based on prefix and suffix: "prefix-
TIME_IN_MS[.suffix]".
saveAsHadoopFiles(prefix, [suffix]) Save this DStream's contents as Hadoop files. The file name at each batch interval is
generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".
foreachRDD(func) The most generic output operator that applies a function, func, to each RDD
generated from the stream. This function should push the data in each RDD to an
external system, such as saving the RDD to files, or writing it over the network to a
database.](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-17-320.jpg)

![DataFrame and SQL Operations
Combine streaming with DataFrame and SQL operations
/** DataFrame operations inside your streaming program */
val words: DStream[String] = ... words.foreachRDD { rdd =>
// Get the singleton instance of SQLContext
val sqlContext = SQLContext.getOrCreate(rdd.sparkContext)
import sqlContext.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.toDF("word")
// Register as table
wordsDataFrame.registerTempTable("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame = sqlContext.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-19-320.jpg)






































![Data Types - Local Vector
• A local vector has integer-typed and 0-based indices and double-typed values, stored on a
single machine.
• Two types of vectors
• Dense vectors: double array, [1.0, 0.0, 3.0]
• Sparse vectors: indices and values, (3, [0, 2], [1.0, 3.0])
• Vectors: local vectors를 위한 utility(local vector를 생성)
• Two types of libraries
• Breeze: 초기버전에 포함, library for numerical processing for scala
• Jblas: 최신버전, library for linear algebra for java
import org.apache.spark.mllib.linalg.{Vector, Vectors}
// Create a dense vector (1.0, 0.0, 3.0).
val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its indices and values corresponding to nonzero entries.
val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its nonzero entries.
val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-58-320.jpg)
![Data Types – Labeled Point
• A local vector, either dense or sparse, associated with a label/response
• Types of labeled point
• Regression and classification: Use a double
• Binary classification: either 0(negative) or 1(positive).
• Multiclass classification: class indices starting from zero: 0, 1, 2, …
• Sparse data
• Support LIBSVM format: default format used by LIBSVM and LIBLINEAR
• Indices are one-based and in ascending order.
• After loading, the feature indices are converted to zero-based
label index1:value1 index2:value2 ...
// Create a labeled point with a positive label and a dense feature vector.
val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
// Create a labeled point with a negative label and a sparse feature vector. corresponding to nonzero entries.
val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
val examples: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-59-320.jpg)

![Data Types – Distributed Matrix
1개 이상의 RDD들로 분산으로 저장되는 Matrix
Row Matrix
- row-oriented distributed matrix
- RDD[Vector]를 rows로 정의
- QR decomposition
Indexed Row Matrix:
- row index + Row Matrix
- RDD[IndexedRow]를 rows로 정의
- case class IndexedRow(index: Long, vector: Vector)](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-61-320.jpg)
![Data Types – Distributed Matrix
Coordinate Matrix
• RDD[MatrixEntry]를 entries로 정의
• MatrixEntry(i: Long, j: Long, value: Double)
Block Matrix
• RDD[MatrixBlock]를 entries로 정의
• MatrixBlock = ((bri:Long, bci:Long), sub-
matrix:Matrix)
• add, multiply지원
• block size: 1024*1024 default](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-62-320.jpg)
![Basic Statistics
• Summary statistics: colum단위 통계, colStats()
• Correlations: series간의 상관관계를 제공, 2*RDD[Double] or RDD[Vector]](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-63-320.jpg)














![Example ML Workflow
Training
Load data
Extract features
Train model
Evaluate
labels + plain text
labels + feature vectors
labels + predictions
Create many RDDs
val lables:RDD[Double] =
data.map(_.label)
val features:RDD[Vector]
val predictions:RDD[Double]
Explicitly unzip & zip RDDs
val lables:RDD[Double] =
data.map(_.label)
labels.zip(predictions).map {
if (_._1 == _._2) …
}
Pain Point
http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-78-320.jpg)





































![Pregel - 쾨니히스베르크 다리건너기 문제
(Königsberg's bridge problem)
• 독일에는 프레겔(Pregel) 강이 지나는 쾨니히스베르크(Königsberg)라는 도
시가 있다. 18세기경 쾨니히스베르크에는 강에 있는 두 개의 섬을 연결하
는 일곱 개의 다리가 있었는데, 그 곳 사람들은 그 다리를 건너 산보하기를
즐겼다.
• '각각의 다리들을 정확히 한 번씩만 지나 모든 다리를 건너갈 수 있을까?‘
• 오일러가 솔루션이 없음을 증명 (위상수학)
http://www.slideshare.net/payberah/pregel-43904273
https://en.wikipedia.org/wiki/Seven_Bridges_of_K%C3%B6nigsberg
[네이버 지식백과] 쾨니히스베르크 다리건너기 문제 [Königsberg's bridge problem] (수학백과, 2015.5, 대한수학회)](https://image.slidesharecdn.com/apachesparkpart2201611170-161130124124/85/Apache-Spark-Overview-part2-20161117-118-320.jpg)
























Apache Spark Overview part2 (20161117)
- 1. 아파치 스파크 소개 Part 2 2016.11.17 민형기
- 2. Contents • Spark Streaming • Spark GraphX • Spark ML
- 4. Spark Streaming • Spark Streaming is an extension of the core API that scalable, high-throughput, fault- tolerant stream processing of live data streams • Spark’s built-in machine learning algorithms and graph processing algorithms can be applied to data streams
- 5. Spark Streaming Motivation Limitations of Streaming of Hadoop • MR is not suitable for streaming • Apache storm needs learning new API’s and new paradigm • No way to combine batch results from MR with apache storm streams • Maintaining two runtimes are always hard
- 6. How does Spark Streaming work? • Chop up data streams into batches of few secs • Spark treats each batch of data as RDDs and processes them using RDD operations • Processed results are pushed out in batches https://stanford.edu/~rezab/sparkclass/slides/td_streaming.pdf
- 7. Discretized streams(DStream) • Basic abstraction provided by Spark Streaming • Represents a continuous stream of data • Input data stream received from source • The processed data stream generated by transforming the input stream • Represented by a continuous series of RDDs • Each RDD in a DStream contains data from a certain interval
- 8. DStream Transformation • Any operation applied on a DStream translates to opeartions on the underlying RDDs. val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(1)) // Create a DStream that will connect to hostname:port, like localhost:9999 val lines = ssc.socketTextStream("localhost", 9999) // Split each line into words val words = lines.flatMap(_.split(" "))
- 9. Transformations on DStreams Transformation Meaning map(func) Return a new DStream by passing each element of the source DStream through a function func. flatMap(func) Similar to map, but each input item can be mapped to 0 or more output items. filter(func) Return a new DStream by selecting only the records of the source DStream on which func returns true. repartition(numPartitions) Changes the level of parallelism in this DStream by creating more or fewer partitions. union(otherStream) Return a new DStream that contains the union of the elements in the source DStream and other DStream. count() Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. reduce(func) Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative so that it can be computed in parallel.
- 10. Transformations on DStreams Transformation Meaning countByValue() When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. reduceByKey (func, [numTasks]) When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. Join (otherStream, [numTasks]) When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. Cogroup (otherStream, [numTasks]) When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. transform(func) Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. updateStateByKey(func) Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key.
- 11. Input DStreams and Receivers Spark Streaming provides two categories of built-in streaming sources • Basic Sources: Sources directly available in the StreamingContext API. • Eg) file systems, socket connections, and Akka actors. • Advanced Sources: Kafka, Flume, Kinesis, Twitter, etc. are available through extra utility classes.
- 12. Receivers – Advanced Sources Source Artifact Kafka spark-streaming-kafka_2.10 Flume spark-streaming-flume_2.10 Kinesis spark-streaming-kinesis-asl_2.10 [Amazon Software License] Twitter spark-streaming-twitter_2.10 ZeroMQ spark-streaming-zeromq_2.10 MQTT spark-streaming-mqtt_2.10 https://spark.apache.org/docs/1.6.2/streaming-programming-guide.html
- 13. Example: Word Count with Kafka object WordCount { def main(args: Array[String]) { val context = new StreamingContext(conf, Seconds(1)) val lines = KafkaUtils.createStream(context,...) val words = lines.flatMap(_.split(“ ")) val wordCounts = words.map( x => (x, 1)) .reduceByKey(_ + _) wordCounts.print() context.start() context.awaitTermination() } }
- 14. Window Operations • Transformations over a sliding window of data • parameters • window length: The duration of the window (3 in the figure). • sliding interval: The interval at which the window operation is performed (2 in the figure). // Reduce last 30 seconds of data, every 10 seconds val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
- 15. Window Operations Transformation Meaning window(windowLength, slideInterval) Return a new DStream which is computed based on windowed batches of the source DStream. countByWindow (windowLength, slideInterval) Return a sliding window count of elements in the stream. reduceByWindow (func, windowLength, slideInterval) Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative so that it can be computed correctly in parallel. reduceByKeyAndWindow (func, windowLength, slideInterval, [numTasks]) When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. reduceByKeyAndWindow (func, invFunc, windowLength, slideInterval, [numTasks]) A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. countByValueAndWindow (windowLength,slideInterval, [numTasks]) When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window.
- 16. Join Operations • Stream-stream joins • Streams can be easily joined with other streams • Support leftOuterJoin, rightOuterJoin, fullOutherJoin • Stream-dataset joins • dynamically change the dataset you want to join against.
- 17. Output Operations on DStreams Output operations allow Dstream’s data to be pushed out to external systems like a database or a file systems. Output Operation Meaning print() Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. saveAsTextFiles(prefix, [suffix]) Save this DStream's contents as text files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". saveAsObjectFiles(prefix, [suffix]) Save this DStream's contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix- TIME_IN_MS[.suffix]". saveAsHadoopFiles(prefix, [suffix]) Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". foreachRDD(func) The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database.
- 18. Dstreams + RDDs = Power • Combine live data streams with historical data • Generate historical data models with Spark, etc • Use data models to process live data stream • Combine streaming with Mllib, GraphX algos • Offline learning, online prediction • Online learning and prediction • Combine streaming with DataFrame and SQL operations https://stanford.edu/~rezab/sparkclass/slides/td_streaming.pdf
- 19. DataFrame and SQL Operations Combine streaming with DataFrame and SQL operations /** DataFrame operations inside your streaming program */ val words: DStream[String] = ... words.foreachRDD { rdd => // Get the singleton instance of SQLContext val sqlContext = SQLContext.getOrCreate(rdd.sparkContext) import sqlContext.implicits._ // Convert RDD[String] to DataFrame val wordsDataFrame = rdd.toDF("word") // Register as table wordsDataFrame.registerTempTable("words") // Do word count on DataFrame using SQL and print it val wordCountsDataFrame = sqlContext.sql("select word, count(*) as total from words group by word") wordCountsDataFrame.show() }
- 20. Advantage of an Unified Stack • Explore data interactively to identify problems • Use same code in Spark for processing large logs • Use similar code in Spark Streaming for realtime processing https://stanford.edu/~rezab/sparkclass/slides/td_streaming.pdf
- 21. Performance • Can processes 60M records/sec(6 GB/sec) on 100 nodes at sub-second latency https://stanford.edu/~rezab/sparkclass/slides/td_streaming.pdf
- 22. Spark GraphX Graph Analytics in Spark
- 23. Spark GraphX • Spark API for graphs and graph-parallel computation • Flexibility: seamlessly work with both graphs and collections • Speed: Comparable performance to the fastest specialized graph processing systems • Algorithms: PageRank, Connected Components, Triangle count etc. • Resilient Distributed Property Graph(RDPG, extends RDD) • Directed multigraph (-> parallels edges) • Properties attached to each vertex and edge • Common graph operations (subgraph computation, joining vertices, …) • Growing collection of graph algorithms http://www.slideshare.net/PetrZapletal1/spark-concepts-spark-sql-graphx-streaming
- 25. Graph 101 • A graph is a mathematical representation of linked data • It’s defined in term of its Vertices and Edges, G(V,E) Edge Vertex
- 29. Page Rank – Identifying Leaders http://www.slideshare.net/SessionsEvents/joey-gonzalez-graph-lab-m-lconf-2013
- 30. Triangle Counting – Finding Community Count triangles passing through each vertex: Measures “cohensiveness” of local community http://www.slideshare.net/SessionsEvents/joey-gonzalez-graph-lab-m-lconf-2013
- 31. Collaborative Filtering – Recommending Product http://www.slideshare.net/SessionsEvents/joey-gonzalez-graph-lab-m-lconf-2013
- 32. Collaborative Filtering – Recommending Product http://www.slideshare.net/SessionsEvents/joey-gonzalez-graph-lab-m-lconf-2013
- 33. The Graph–Parallel Pattern Computation depends only on the neighbors https://amplab.cs.berkeley.edu/wp-content/uploads/2014/02/graphx.pdf
- 34. Many Graph-Parallel Algorithms Collaborative Filtering Alternating Least Squares Stochastic Gradient Descent Tensor Factorization Structured Prediction Loopy Belief Propagation Max-Product Linear Programs Gibbs Sampling Semi-supervised ML Graph SSL CoEM Community Detection Triangle-Counting K-core Decomposition K-Truss Graph Analytics PageRank Personalized PageRank Shortest Path Graph Coloring Classification Neural Networks https://amplab.cs.berkeley.edu/wp-content/uploads/2014/02/graphx.pdf
- 40. Modern Analytics Problems • Difficult to Program and Use • Users must Learn, Deploy, and Manage multiple systems • Inefficient • Extensive data movement and duplication across https://stanford.edu/~rezab/sparkclass/slides/ankur_graphx.pdf
- 41. Solution: The GraphX Unified Approach https://stanford.edu/~rezab/sparkclass/slides/ankur_graphx.pdf
- 42. Tables and Graphs are composable " views of the same physical data Each view has its own operators that exploit the semantics of the view to achieve efficient execution
- 43. The Property Graph: Graph as a Table http://spark.apache.org/docs/1.6.2/graphx-programming-guide.html
- 44. Creating a Graph (Scala) http://spark.apache.org/docs/1.6.2/graphx-programming-guide.html
- 47. Graph Operations (Scala) PageRank Triangle Count Connected Components http://spark.apache.org/docs/1.6.2/graphx-programming-guide.html
- 48. Triplets Join Vertices and Edges • The triplets operator joins vertices and edges: • The mrTriplets operator sums adjacent triplets SELECT src.Id, dst.Id, src.attr, e.attr, dst.attr FROM edges AS e JOIN vertices AS src, vertices AS dst ON e.srcId = src.Id AND e.dstId = dst.Id SELECT t.dstId, reduceUDF( mapUDF(t) ) AS sum FROM triplets AS t GROUPBY t.dstId https://spark.apache.org/docs/1.6.2/graphx-programming-guide.html https://stanford.edu/~rezab/sparkclass/slides/ankur_graphx.pdf
- 51. Distributed Graphs as Tables(RDDs) http://spark.apache.org/docs/1.6.2/graphx-programming-guide.html
- 54. Spark ML
- 55. Spark MLlib • MLlib is Spark’s machine learning (ML) library to make practical machine learning scalable and easy. • Shipped with Spark since 2013.09 (0.8.1) • two packages • spark.mllib: contains the original API built on top of RDDs • spark.ml: provides higher-level API built on top of DataFrames for constructing ML pipelines
- 56. MLlib’s Mission • MLlib‘s mission is to make practical machine learning easy and scalable. • Easy to build machine learning applications • Capable of learning from large-scale datasets • Easy to integrate into existing workflows http://www.slideshare.net/databricks/combining-machine-learning-frameworks-with-apache-spark
- 58. Data Types - Local Vector • A local vector has integer-typed and 0-based indices and double-typed values, stored on a single machine. • Two types of vectors • Dense vectors: double array, [1.0, 0.0, 3.0] • Sparse vectors: indices and values, (3, [0, 2], [1.0, 3.0]) • Vectors: local vectors를 위한 utility(local vector를 생성) • Two types of libraries • Breeze: 초기버전에 포함, library for numerical processing for scala • Jblas: 최신버전, library for linear algebra for java import org.apache.spark.mllib.linalg.{Vector, Vectors} // Create a dense vector (1.0, 0.0, 3.0). val dv: Vector = Vectors.dense(1.0, 0.0, 3.0) // Create a sparse vector (1.0, 0.0, 3.0) by specifying its indices and values corresponding to nonzero entries. val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)) // Create a sparse vector (1.0, 0.0, 3.0) by specifying its nonzero entries. val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))
- 59. Data Types – Labeled Point • A local vector, either dense or sparse, associated with a label/response • Types of labeled point • Regression and classification: Use a double • Binary classification: either 0(negative) or 1(positive). • Multiclass classification: class indices starting from zero: 0, 1, 2, … • Sparse data • Support LIBSVM format: default format used by LIBSVM and LIBLINEAR • Indices are one-based and in ascending order. • After loading, the feature indices are converted to zero-based label index1:value1 index2:value2 ... // Create a labeled point with a positive label and a dense feature vector. val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0)) // Create a labeled point with a negative label and a sparse feature vector. corresponding to nonzero entries. val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))) val examples: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
- 60. Data Types – Local Matrix • Local Matrix: single machine에 저장되는 matrix, size는 Int 타입 • dense matrices: (row, column) 값(int) + 1차원 배열(double) • Matrix size: (3,2) • Value: 1차원 배열로 저장, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0) • sparse matrices: CSC(Compressed Sparse Column) format • Matrix size(3,2) • col_ptr:Array(0,3,6) • row_ind: Array(0,1,2,0,1,2) • val: Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0) 1.0 2.0 3.0 4.0 5.0 6.0 9.0 0.0 0.0 8.0 0.0 6.0 1.0 0.0 2.0 0.0 0.0 3.0 4.0 5.0 6.0 • Matrix size: (3,3) • col_ptr:Array(0,2,3,6) • row_ind:Array(0,2,2,0,1,2) • val:Array(1.0,4.0,5.0,2.0,3.0,6.0) http://www.scipy-lectures.org/advanced/scipy_sparse/csc_matrix.html https://spark.apache.org/docs/1.6.2/api/scala/index.html#org.apache.spark.mllib.linalg.SparseMatrix
- 61. Data Types – Distributed Matrix 1개 이상의 RDD들로 분산으로 저장되는 Matrix Row Matrix - row-oriented distributed matrix - RDD[Vector]를 rows로 정의 - QR decomposition Indexed Row Matrix: - row index + Row Matrix - RDD[IndexedRow]를 rows로 정의 - case class IndexedRow(index: Long, vector: Vector)
- 62. Data Types – Distributed Matrix Coordinate Matrix • RDD[MatrixEntry]를 entries로 정의 • MatrixEntry(i: Long, j: Long, value: Double) Block Matrix • RDD[MatrixBlock]를 entries로 정의 • MatrixBlock = ((bri:Long, bci:Long), sub- matrix:Matrix) • add, multiply지원 • block size: 1024*1024 default
- 63. Basic Statistics • Summary statistics: colum단위 통계, colStats() • Correlations: series간의 상관관계를 제공, 2*RDD[Double] or RDD[Vector]
- 64. Basic Statistics • Stratified sampling • Hypothesis testing • chi-squared tests: vector, matrix, laveledPoint를 인자로 받을 수 있음 • Kolmogorov-Smirnov test: 1-sample, 2-sided Kolmogorov-Smirnov test
- 65. Basic Statistics • Random data generation • Useful for Randomized algorithms, prototyping, and performance testing • Given distribution: Uniform, standard normal, poisson • Kernel density estimation • Technique useful for visualizing empirical probability distributions
- 68. Example: PCA(Principal component analysis) https://stanford.edu/~rezab/sparkclass/slides/reza_mllib.pdf
- 73. spark.ml(w/DataFrame) – ML Pipelines
- 74. ML Workflows are complex http://www.slideshare.net/databricks/dataframes-and-pipelines * Evan Sparks. “ML Pipelines.” amplab.cs.berkeley.edu/ml-‐pipelines Image classification pipeline* Specify pipeline Inspect & debug Re‐run on new data Tune parameters
- 75. Data scientist’s wish list: • Run original code on a production environment • Use distributed data sources • Use familiar APIs and libraries • Distribute ML workload piece by piece • Only distribute as needed • Easily switch between local & distributed settings
- 76. Example: Text Classification • Goal: Given a text document, predict its topic. Subject: Re: Lexan Polish? Suggest McQuires #1 plastic polish. It will help somewhat but nothing will remove deep scratches without making it worse than it already is. McQuires will do something... Features Label 1: about science 0: not about science Dataset: “20 Newsgroups” From UCI KDD Archive http://www.slideshare.net/databricks/dataframes-and-pipelines
- 77. Training & Testing Training Testing / Production http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib
- 78. Example ML Workflow Training Load data Extract features Train model Evaluate labels + plain text labels + feature vectors labels + predictions Create many RDDs val lables:RDD[Double] = data.map(_.label) val features:RDD[Vector] val predictions:RDD[Double] Explicitly unzip & zip RDDs val lables:RDD[Double] = data.map(_.label) labels.zip(predictions).map { if (_._1 == _._2) … } Pain Point http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib
- 79. Example ML Workflow Training Load data Extract features Train model Evaluate labels + plain text labels + feature vectors labels + predictions http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib Write as a script Not modular Difficult to re-use workflow Pain Point
- 80. Example ML Workflow Training Testing/Production Load data Extract features Train model Evaluate labels + plain text labels + feature vectors labels + predictions Load new data Extract features Predict using model Act on predictions plain text feature vectors predictions Almost identical workflow http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib
- 81. Example ML Workflow Training Load data Extract features Train model Evaluate labels + plain text labels + feature vectors labels + predictions Parameter tuning Key part of ML Involves training many models For different splits of the data For different sets of parameters Pain Point http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib
- 82. Main Concepts • DataFrame: The ML Dataset(= Table in Spark SQL) • Abstractions • Transformer: An algorithm that transforms one DataFrame into another • Estimator: An algorithm that can be fit on a DataFrame to produce a Transformer • Pipeline: Chains multiple transformers and estimators to produce a ML workflow • Evaluator: compute metrics from predictions • Parameter: Common API for specifying parameters Load data Extract features Train model Evaluate
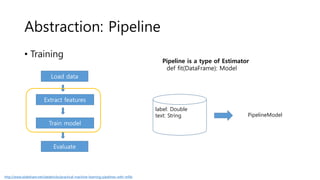
- 83. DataFrame: Load Data • Training Load data Extract features Train model Evaluate labels + plain text labels + feature vectors labels + predictions http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib
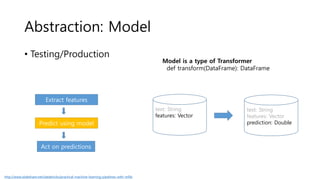
- 84. Abstraction: Transformer • Training Extract features Train model Evaluate labels + feature vectors labels + predictions def transform(DataFrame): DataFrame http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib label: Double text: String label: Double text: String features: Vector
- 85. Abstraction: Estimator • Training Extract features Train model Evaluate labels + feature vectors labels + predictions def fit(DataFrame): Model LogisticRegression Model http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib label: Double text: String features: Vector label: Double text: String features: Vector prediction: Double
- 86. Abstraction: Evaluator • Training Extract features Train model Evaluate labels + feature vectors labels + predictions def evaluate(DataFrame): Double Metric: accuracy AUC MSE … http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib label: Double text: String features: Vector prediction: Double
- 87. Abstraction: Model • Testing/Production Model is a type of Transformer def transform(DataFrame): DataFrame http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib Extract features Predict using model Act on predictions text: String features: Vector text: String features: Vector prediction: Double
- 88. (Recall) Abstraction: Estimator • Training Extract features Train model Evaluate def fit(DataFrame): Model LogisticRegression Model http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib label: Double text: String features: Vector label: Double text: String features: Vector prediction: Double Load data
- 89. Abstraction: Pipeline • Training Extract features Train model Evaluate PipelineModel http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib label: Double text: String Load data Pipeline is a type of Estimator def fit(DataFrame): Model
- 90. Abstraction: PipelineModel • Testing/Production Evaluate http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib label: Double text: String text: String features: Vector prediction: Double Load data PipelineModel is a type of Transformer def transform(DataFrame): DataFrame Extract features Predict using model
- 91. Abstractions: Summary Load data Extract features Train model Evaluate Load data Extract features Predict using model Act on predictions Training Testing/Production DataFrame Transformer Estimator Evaluator http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib
- 92. Parameter Tuning Given: • Estimator • Parameter grid • Evaluator Find best parameters CrossValidator Hashing TF Logistic Regression BinaryClassification Evaluator Tokenizer hashingTF.numFeatures {100, 1000, 10000} lr.regParam {0.01, 0.1, 0.5} http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib
- 93. References Papers • Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters : http://people.csail.mit.edu/matei/papers/2012/hotcloud_spark_streaming.pdf • GraphX: Unifying Data-Parallel and Graph-Parallel Analytics : https://amplab.cs.berkeley.edu/wp-content/uploads/2014/02/graphx.pdf • MLlib: Machine Learning in Apache Spark : http://www.jmlr.org/papers/volume17/15-237/15-237.pdf Stanford 자료 • Distributed Computing with Spark: https://stanford.edu/~rezab/sparkclass/slides/reza_introtalk.pdf • Spark Streaming: https://stanford.edu/~rezab/sparkclass/slides/td_streaming.pdf • GraphX: Unified Graph Analytics on Spark: https://stanford.edu/~rezab/sparkclass/slides/ankur_graphx.pdf • GraphX: Graph Analytics in Spark: https://stanford.edu/~rezab/nips2014workshop/slides/ankur.pdf • MLlib and Distributing the Singular Value Decomposition: https://stanford.edu/~rezab/sparkclass/slides/reza_mllib.pdf
- 94. References - Spark Streaming • Spark Streaming Programming Guide: http://spark.apache.org/docs/1.6.2/streaming-programming-guide.html • INTRODUCTION TO SPARK STREAMING: http://hortonworks.com/hadoop-tutorial/introduction-spark-streaming/ • Introduction to Spark Streaming: http://www.slideshare.net/datamantra/introduction-to-spark-streaming • Building Robust, Adaptive Streaming Apps with Spark Streaming: http://www.slideshare.net/databricks/building-robust-adaptive-streaming-apps-with-spark- streaming • Apache storm vs. Spark Streaming: http://www.slideshare.net/ptgoetz/apache-storm-vs-spark-streaming • Four Things to Know About Reliable Spark Streaming with Typesafe and Databricks: http://www.slideshare.net/Typesafe_Inc/four-things-to-know-about- reliable-spark-streaming-with-typesafe-and-databricks • Spark streaming , Spark SQL: http://www.slideshare.net/jerryjung7/spark-streaming-spark-sql • Structuring Spark: DataFrames, Datasets, and Streaming: http://www.slideshare.net/databricks/structuring-spark-dataframes-datasets-and-streaming • Taking Spark Streaming to the Next Level with Datasets and DataFrames: http://www.slideshare.net/databricks/taking-spark-streaming-to-the-next-level-with- datasets-and-dataframes • Integrating Kafka and Spark Streaming: Code Examples and State of the Game: http://www.michael-noll.com/blog/2014/10/01/kafka-spark-streaming- integration-example-tutorial/ • Spark Streaming with Kafka & HBase Example: http://henning.kropponline.de/2015/04/26/spark-streaming-with-kafka-hbase-example/ • Real-Time Streaming Data Pipelines with Apache APIs: Kafka, Spark Streaming, and HBase: https://www.mapr.com/blog/real-time-streaming-data-pipelines- apache-apis-kafka-spark-streaming-and-hbase • A Deep Dive into Structured Streaming: Apache Spark Meetup at Bloomberg 2016: http://www.slideshare.net/databricks/a-deep-dive-into-structured- streaming-apache-spark-meetup-at-bloomberg-2016
- 95. References - Spark GraphX • GraphX: http://ampcamp.berkeley.edu/big-data-mini-course/graph-analytics-with-graphx.html • GraphX: Graph Analytics in Apache Spark (AMPCamp 5, 2014-11-20): http://www.slideshare.net/ankurdave/graphx-ampcamp5 • Machine Learning and GraphX: http://www.slideshare.net/noootsab/machine-learning-and-graphx • Finding Graph Isomorphisms In GraphX And GraphFrames: http://www.slideshare.net/SparkSummit/finding-graph-isomorphisms-in- graphx-and-graphframes • 스사모 테크톡 - GraphX: http://www.slideshare.net/sangwookimme/graphx • GraphFrames: DataFrame-based graphs for Apache® Spark™: http://www.slideshare.net/databricks/graphframes-dataframebased- graphs-for-apache-spark • Graphs are everywhere! Distributed graph computing with Spark GraphX: http://www.slideshare.net/andreaiacono/graphs-are- everywhere-distributed-graph-computing-with-spark-graphx • GraphX and Pregel - Apache Spark: http://www.slideshare.net/AshutoshTrivedi3/graphx-and-pregel-apache-spark • Joey gonzalez, graph lab, m lconf 2013: http://www.slideshare.net/SessionsEvents/joey-gonzalez-graph-lab-m-lconf-2013 • Spark Concepts - Spark SQL, Graphx, Streaming: http://www.slideshare.net/PetrZapletal1/spark-concepts-spark-sql-graphx-streaming • Using spark for timeseries graph analytics: http://www.slideshare.net/SigmoidHR/using-spark-for-timeseries-graph-analytics • An excursion into Graph Analytics with Apache Spark GraphX: http://www.slideshare.net/ksankar/an-excursion-into-graph-analytics- with-apache-spark-graphx • Exploring Titan and Spark GraphX for Analyzing Time-Varying Electrical Networks: http://www.slideshare.net/HadoopSummit/exploring-titan-and-spark-graphx-for-analyzing-timevarying-electrical-networks
- 96. References - Spark Mllib • Apache® Spark™ MLlib: From Quick Start to Scikit-Learn: http://www.slideshare.net/databricks/spark-mllib-from-quick-start-to-scikitlearn • Introduction to Spark ML: http://www.slideshare.net/hkarau/introduction-to-spark-ml • Apache Spark Machine Learning- MapR: http://www.slideshare.net/caroljmcdonald/spark-machine-learning • Distributed ML in Apache Spark: http://www.slideshare.net/databricks/distributed-ml-in-apache-spark • Practical Machine Learning Pipelines with MLlib: http://www.slideshare.net/databricks/practical-machine-learning-pipelines-with-mllib • ML Pipelines: A New High-Level API for MLlib: https://databricks.com/blog/2015/01/07/ml-pipelines-a-new-high-level-api-for-mllib.html • CTR Prediction using Spark Machine Learning Pipelines: http://www.slideshare.net/ManishaSule/ctr-prediction-using-spark-machine-learning-pipelines • Combining Machine Learning Frameworks with Apache Spark: http://www.slideshare.net/databricks/combining-machine-learning-frameworks-with-apache-spark • Machine learning pipeline with spark ml: http://www.slideshare.net/datamantra/machine-learning-pipeline-with-spark-ml • Introduction to Spark ML: http://www.slideshare.net/dbtsai/m-llib-sf-machine-learning • Introduction to ML with Apache Spark MLlib: http://www.slideshare.net/tmatyashovsky/introduction-to-ml-with-apache-spark-mllib • MLlib: Spark's Machine Learning Library: http://www.slideshare.net/jeykottalam/mllib • Large Scale Machine Learning with Apache Spark: http://www.slideshare.net/cloudera/large-scale-machine-learning-with-apache-spark • Spark DataFrames and ML Pipelines: http://www.slideshare.net/databricks/dataframes-and-pipelines • Why you should use Spark for machine learning: http://www.infoworld.com/article/3031690/analytics/why-you-should-use-spark-for-machine-learning.html • Neural Networks, Spark MLlib, Deep Learning: http://www.slideshare.net/AsimJalis/neural-networks-spark-mllib-deep-learning • Apache Spark MLlib 2.0 Preview: Data Science and Production: http://www.slideshare.net/databricks/apache-spark-mllib-20-preview-data-science-and-production
- 97. Appendix
- 98. 구글 빅데이터 관련 기술 기술 연도 내용 GFS 2003 Google File System: A Distributed Storage MapReduce 2004 Simplified Data Processing on Large Clusters Sawzall 2005 Interpreting the Data: Parallel Analysis with Sawzall Chubby 2006 The Chubby Lock Service for Loosely-Coupled Distributed Systems BigTable 2006 A Distributed Storage System for Structured Data Paxos 2007 Paxos Made Live - An Engineering Perspective Colossus 2009 GFS II Percolator 2010 Large-scale Incremental Processing Using Distributed Transactions and Notifications Pregel 2010 A System for Large-Scale Graph Processing Dremel 2010 Interactive Analysis of Web-Scale Datasets Tenzing 2011 A SQL Implementation On The MapReduce Framework Megastore 2011 Providing Scalable, Highly Available Storage for Interactive Services Spanner 2012 Google's Globally-Distributed Database F1 2012 The Fault-Tolerant Distributed RDBMS Supporting Google's Ad Business
- 99. Spark Streaming 2.0 • Structured Streaming • High-level streaming API built on Spark SQL engine • Runs the same queries on DataFrames • Event time, windowing, sessions, sources & sinks • Unifies streaming, interactive and batch queries • Aggregate data in a stream, then serve using JDBC • Change queries at runtime • Build and apply ML models
- 100. Spark Streaming vs. Storm
- 101. Reliability Models 구분 Core Storm Storm Trident Spark Streaming At Most Once Yes Yes No At Least Once Yes Yes No* Once and Only Once (Exactly Once) No Yes Yes* http://www.slideshare.net/ptgoetz/apache-storm-vs-spark-streaming
- 102. Programing Model Core Storm Storm Trident Spark Streaming Stream Primitive Tuple Tuple, Tuple Batch, Partition Dstream Stream Sources Spouts Spouts, Trident Spouts HDFS, Network Computation/ Transformation Bolts Filters, Functions, Aggregations, Joins Transformation, Window Operations Stateful Operation No (roll your own) Yes Yes Output/ Persistence Bolts State, MapState foreachRDD 2014, http://www.slideshare.net/ptgoetz/apache-storm-vs-spark-streaming
- 103. Performance • Storm capped at 10k msgs/sec/node? • Spark Streaming 40x faster than Storm? System Performance Storm(Twitter) 10,000 records/s/node Spark Streaming 400,000 records/s/node Apache S4 7,000 records/s/node Other Commercial Systems 100,000 records/s/node 2014, http://www.slideshare.net/ptgoetz/apache-storm-vs-spark-streaming
- 104. Features in Spark Streaming that Help Prevent Data Loss
- 105. Spark Streaming Application: Receive data http://www.slideshare.net/Typesafe_Inc/four-things-to-know-about-reliable-spark-streaming-with-typesafe-and-databricks
- 106. Spark Streaming Application: Process Data http://www.slideshare.net/Typesafe_Inc/four-things-to-know-about-reliable-spark-streaming-with-typesafe-and-databricks
- 107. Fault Tolerance and Reliability
- 108. What if an executor fails? http://www.slideshare.net/Typesafe_Inc/four-things-to-know-about-reliable-spark-streaming-with-typesafe-and-databricks
- 109. What if an driver fails?
- 110. Recovering Driver w/ DStream Checkpointing
- 111. Recovering Driver w/ DStream Checkpointing
- 112. Recovering data with Write Ahead Logs
- 113. Recovering data with Write Ahead Logs
- 114. RDD checkpointing • Stateful stream processing can lead to long RDD lineages • Long lineage = bad for fault-tolerance, too much recomputation • RDD checkpointing saves RDD data to the fault- tolerant storage to limit lineage and recomputation • More: http://spark.apache.org/docs/latest/streaming- programming-guide.html#checkpointing
- 116. GraphX
- 117. Connected vs. Strongly connected vs. Complete graphs • Connected is usually associated with undirected graphs (two way edges): there is a path between every two nodes. • Strongly connected is usually associated with directed graphs (one way edges): there is a route between every two nodes. • Complete graphs are undirected graphs where there is an edge between every pair of nodes. http://mathoverflow.net/questions/6833/difference-between-connected-vs-strongly-connected-vs-complete-graphs Connected Graph Strongly Connected Graph Completed Graph
- 118. Pregel - 쾨니히스베르크 다리건너기 문제 (Königsberg's bridge problem) • 독일에는 프레겔(Pregel) 강이 지나는 쾨니히스베르크(Königsberg)라는 도 시가 있다. 18세기경 쾨니히스베르크에는 강에 있는 두 개의 섬을 연결하 는 일곱 개의 다리가 있었는데, 그 곳 사람들은 그 다리를 건너 산보하기를 즐겼다. • '각각의 다리들을 정확히 한 번씩만 지나 모든 다리를 건너갈 수 있을까?‘ • 오일러가 솔루션이 없음을 증명 (위상수학) http://www.slideshare.net/payberah/pregel-43904273 https://en.wikipedia.org/wiki/Seven_Bridges_of_K%C3%B6nigsberg [네이버 지식백과] 쾨니히스베르크 다리건너기 문제 [Königsberg's bridge problem] (수학백과, 2015.5, 대한수학회)
- 119. Bulk Synchronous Parallel(BSP) • BSP abstract computer is a bridging model for designing parallel algorithms • developed by Leslie Valiant of Harvard University during the 1980s • Model consist of • Concurrent computation: every participating processor may perform local computations. The computations occur asynchronously of all the others but may overlap with communication. • Communication: The processes exchange data between themselves to facilitate remote data storage capabilities. • Barrier synchronisation: When a process reaches this point (the barrier), it waits until all other processes have reached the same barrier. https://en.wikipedia.org/wiki/Bulk_synchronous_parallel
- 120. Pregel • A System for Large-Scale Graph Processing: Parallel programming model • Inspired by bulk synchronous parallel (BSP) model • Vertex-Centrix Program • Think as Vertex • Each vertex computes individually its value: in parallel • Each vertex can see its local context, and updates its value accodingly http://www.slideshare.net/payberah/pregel-43904273
- 121. Pregel – Execution Model • Applications run in sequence of iterations: supersteps • During a superstep, user-dened functions for each vertex is invoked (method Compute()): in parallel • A vertex in superstep S can: • reads messages sent to it in superstep S-1. • sends messages to other vertices: receiving at superstep S+1. • modies its state. • Vertices communicate directly with one another by sending messages. http://www.slideshare.net/payberah/pregel-43904273
- 122. Pregel – Execution Model • Superstep 0: all vertices are in the active state. • A vertex deactivates itself by voting to halt: no further work to do. • A halted vertex can be active if it receives a message. • The whole algorithm terminates when: • All vertices are simultaneously inactive. • There are no messages in transit. http://www.slideshare.net/payberah/pregel-43904273
- 123. Pregel – Execution Model • Aggregation: a mechanism for global communication, monitoring, and data. • Runs after each superstep. • Each vertex can provide a value to an aggregator in superstep S. • The system combines those values and the resulting value is made available to all vertices in superstep S + 1. • A number of predened aggregators, e.g., min, max, sum. • Aggregation operators should be commutative and associative. http://www.slideshare.net/payberah/pregel-43904273
- 124. Pregel - Example: Max Value i_val := val for each message m if m > val then val := m if i_val == val then vote_to_halt else for each neighbor v send_message(v, val) http://www.slideshare.net/payberah/pregel-43904273
- 125. Graph Processing vs. Graph Database http://www.slideshare.net/SparkSummit/finding-graph-isomorphisms-in-graphx-and-graphframes
- 127. Page Rank – Identifying Leaders https://stanford.edu/~rezab/sparkclass/slides/ankur_graphx.pdf
- 128. Page Rank – Identifying Leaders https://stanford.edu/~rezab/sparkclass/slides/ankur_graphx.pdf
- 132. GraphX - Caching for Iterative mrTriplets
- 133. GraphX - mrTriplets Execution
- 134. Spark ML
- 135. MLlib - Classification and Regression Problem Type Supported Methods Binary Classification linear SVMs, logistic regression, decision trees, random forests, gradient-b oosted trees, naive Bayes Multiclass Classification logistic regression, decision trees, random forests, naive Bayes Regression linear least squares, Lasso, ridge regression, decision trees, random forests, gradient-boosted trees, isotonic regression
- 136. MLlib - Collaborative Filtering • Collaborative Filtering: aim to fill in the missing entries of a user-item association matrix • Mllib • Support model-based collaborative filtering • Use ALS(alternating least squares) algorithm to learn latent factors. • numBlocks: the number of blocks used to parallelize computation (set to -1 to auto-configure). • rank: the number of latent factors in the model. • iterations: the number of iterations to run. • lambda: specifies the regularization parameter in ALS. • implicitPrefs: specifies whether to use the explicit feedback ALS variant or one adapted for implicit feedback data. • alpha: a parameter applicable to the implicit feedback variant of ALS that governs the baseline confidence in preference observations. • Explicit vs. implicit feedback • Implicit feedback (e.g. views, clicks, purchases, likes, shares etc)을 지원함 • Scaling of the regularization parameter • Scale the regularization parameter(lambda) • ALS-WR(alternating least squares with weighted-λ regularization)
- 137. MLlib - Clustering • K-means • Gaussian mixture • Power iteration clustering • Latent Dirichlet allocation(LDA) • Bisecting k-means • Streaming k-means
- 138. MLlib - Dimensionality Reduction • Singular value decomposition (SVD) • Principal component analysis(PCA)
- 139. MLlib - Feature Extraction and Transformation • TF-IDF • Word2Vec • StandardScaler • Normalizer • ChiSqSelector • ElementwiseProduct • PCA
- 140. MLlib - Frequest Pattern Mining • FP-growth • Association Rules • PrefixSpan
- 141. MLlib - Evaluation Metrics • Classification model evaluation • Binary classification • Threshold tuning • Multiclass classification • Label based metrics • Multilabel classification • Ranking systems • Regression model evaluation
- 142. MLlib - Optimization • Mathematical description • Gradient descent • Stochastic gradient descent(SGC) • Update schemes for distributed SGD • Limited-memory BGFS(L-BFGS) • Choosing and Optimization Method • Implementation in Mllib • Gradient descent and stochastic gradient descent • L-BFGS