












![Scala Crash Course (cont.)
// Tuples
// Immutable lists
val captainStuff = ("Picard", "EnterpriseD", "NCC1701D")
//> captainStuff : (String, String, String) = ...
// Lists
// Like a tuple with more functionality, but it cannot hold items of different types.
val shipList = List("Enterprise", "Defiant", "Voyager", "Deep Space Nine") //> shipList : List[String]
// Access individual members using () with ZEROBASED index
println(shipList(1)) //> Defiant
// Let's apply a function literal to a list. map() can be used to apply any function to every item in a collection.
val backwardShips = shipList.map( (ship: String) => {ship.reverse} )
//> backwardShips : List[String] = ...
//| pS peeD)
for (ship <backwardShips) { println(ship) } //> esirpretnE
//| tnaifeD
//| regayoV
//| eniN ecapS peeD](https://image.slidesharecdn.com/apachesparkwhatwhywhen-181004093225/85/Apache-Spark-What-Why-When-14-320.jpg)
![Scala Crash Course (cont.)
// reduce() can be used to combine together all the items in a collection using some function.
val numberList = List(1, 2, 3, 4, 5) //> numberList : List[Int] = List(1, 2, 3, 4, 5)
val sum = numberList.reduce( (x: Int, y: Int) => x + y )
//> sum : Int = 15
println(sum) //> 15
// filter() can remove stuff you don't want. Here we'll introduce wildcard syntax while we're at it.
val iHateFives = numberList.filter( (x: Int) => x != 5 )
//> iHateFives : List[Int] = List(1, 2, 3, 4)
val iHateThrees = numberList.filter(_ != 3) //> iHateThrees : List[Int] = List(1, 2, 4, 5)](https://image.slidesharecdn.com/apachesparkwhatwhywhen-181004093225/85/Apache-Spark-What-Why-When-15-320.jpg)



















![Interactive Spark application
$ bin/sparkshell
Using Spark's default log4j profile: org/apache/spark/log4jdefaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.1.137:4041
Spark context available as 'sc' (master = local[*], app id = local1534089873554).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 2.1.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@281963c
scala>](https://image.slidesharecdn.com/apachesparkwhatwhywhen-181004093225/85/Apache-Spark-What-Why-When-35-320.jpg)





























![Netcat Streaming Example
...
Time: 1535630570000 ms
(how,1)
(into,1)
(go,1)
(what,1)
(program,,1)
(want,1)
(looks,1)
(program,1)
(Spark,2)
(a,4)
...
Time: 1535630580000 ms
[sparkuser@horst ~]$ nc lk 9999
...
Spark Streaming is a special SparkContext
that you can use for processing data quickly
in neartime. It’s similar to the standard
SparkContext, which is geared toward batch
operations. Spark Streaming uses a little
trick to create small batch windows (micro
batches) that offer all of the advantages of
Spark: safe, fast data handling and lazy
evaluation combined with realtime
processing. It’s a combination of both batch
and interactive processing.
...](https://image.slidesharecdn.com/apachesparkwhatwhywhen-181004093225/85/Apache-Spark-What-Why-When-66-320.jpg)





Apache Spark: What? Why? When?
- 1. Apache Spark : What? Why? When? Massimo Schenone Sr Consultant
- 2. Big Data Scenario Data is growing faster than computation speeds ⇾ Web apps, mobile, social media, scientific, … Requires large clusters to analyze Programming clusters is hard ⇾ Failures, placement, load balancing
- 3. Challenges of Data Science «The vast majority of work that goes into conducting successful analyses lies in preprocessing data. Data is messy, and cleansing, munging, fusing, mushing, and many other verbs are prerequisites to doing anything useful with it.» «Iteration is a fundamental part of data science. Modeling and analysis typically require multiple passes over the same data.» Advanced Analytics with Spark Sandy Riza, Uri Laserson, Sean Owen & Josh Wills
- 4. Overview The Story of Today Motivations Internals Deploy SQL Streaming If you are immune to boredom, there is literally nothing you cannot accomplish. —David Foster Wallace
- 5. What is Apache Spark? Apache Spark is a cluster computing platform designed to be fast, easy to use and general-purpose. Run workloads 100x faster df = spark.read.json("logs.json") df.where("age > 21") .select("name.first").show() Write applications quickly in Java, Scala, Python, R, and SQL. Spark's Python DataFrame API Combine SQL, streaming, and complex analytics.
- 6. Project Goals Extend the MapReduce model to better support two common classes of analytics apps: ● Iterative algorithms (machine learning, graphs) ● Interactive data mining Enhance programmability: ● Integrate into Scala programming language ● Allow interactive use from Scala interpreter Matei Zaharia, Spark project creator Performance and Productivity
- 7. MapReduce Data Flow ● map function: processes data and generates a set of intermediate key/value pairs. ● reduce function: merges all intermediate values associated with the same intermediate key.
- 10. Motivations to move forward ● MapReduce greatly simplified big data analysis on large, unreliable clusters ● It provides fault-tolerance, but also has drawbacks: – M/R programming model has not been designed for complex operations – iterative computation: hard to reuse intermediate results across multiple computations – efficiency: the only way to share data across jobs is stable storage, which is slow
- 11. Solution ● Extends MapReduce with more operators ● Support for advanced data flow graphs. ● In-memory and out-of-core processing.
- 12. The Scala Programming Language Scala combines object-oriented and functional programming in one concise, high-level language.
- 13. Scala Crash Course // Simple function def sum(a:Int, b:Int) = a+b // High Order Function def calc(a:Int, b:Int, op: (Int, Int) => Int) = op(a,b) // Passing function sum as argument calc(3, 5, sum) // res: Int = 8 // Passing an inlined function calc(3, 5, _ + _) // res: Int = 8
- 14. Scala Crash Course (cont.) // Tuples // Immutable lists val captainStuff = ("Picard", "EnterpriseD", "NCC1701D") //> captainStuff : (String, String, String) = ... // Lists // Like a tuple with more functionality, but it cannot hold items of different types. val shipList = List("Enterprise", "Defiant", "Voyager", "Deep Space Nine") //> shipList : List[String] // Access individual members using () with ZEROBASED index println(shipList(1)) //> Defiant // Let's apply a function literal to a list. map() can be used to apply any function to every item in a collection. val backwardShips = shipList.map( (ship: String) => {ship.reverse} ) //> backwardShips : List[String] = ... //| pS peeD) for (ship <backwardShips) { println(ship) } //> esirpretnE //| tnaifeD //| regayoV //| eniN ecapS peeD
- 15. Scala Crash Course (cont.) // reduce() can be used to combine together all the items in a collection using some function. val numberList = List(1, 2, 3, 4, 5) //> numberList : List[Int] = List(1, 2, 3, 4, 5) val sum = numberList.reduce( (x: Int, y: Int) => x + y ) //> sum : Int = 15 println(sum) //> 15 // filter() can remove stuff you don't want. Here we'll introduce wildcard syntax while we're at it. val iHateFives = numberList.filter( (x: Int) => x != 5 ) //> iHateFives : List[Int] = List(1, 2, 3, 4) val iHateThrees = numberList.filter(_ != 3) //> iHateThrees : List[Int] = List(1, 2, 4, 5)
- 16. And in the End it was ...
- 17. Spark Core The Spark Core itself has two parts: ● A Computation engine which provides some basic functionalities like memory management, task scheduling, fault recovery and most importantly interacting with the cluster manager and storage system (HDFS, Amazon S3, Google Cloud storage, Cassandra, Hive, etc.) ● Spark Core APIs (available in Scala, Python, Java, and R): – Unstructured APIs : RDDs, Accumulators and Broadcast variables – Structured APIs : DataFrames and DataSets
- 18. Resilient Distributed Datasets (RDDs) A distributed memory abstraction ● Immutable collections of objects spread across a cluster ● An RDD is divided into a number of partitions, which are atomic pieces of information ● Built through parallel transformations from: – data in stable storage (fs, HDFS, S3, via JDBC, etc.) – existing RDDs
- 19. RDD Operators High-order functions: ● Transformations: lazy operators that create new RDDs ( map, filter, groupBy, join, etc.). Their result RDD is not immediately computed. ● Actions: launch a computation and return a value (non-RDD) to the program or write data to the external storage ( count, take, collect, save, etc.). Data is sent from executors to the driver.
- 20. Creating RDDs The SparkContext is our handle to the Spark cluster. It defines a handful of methods which can be used to create and populate a RDD: ● Turn a collection into an RDD ● Load text file from local FS, HDFS, or S3 val rdd = sc.parallelize(Array(1, 2, 3)) val a = sc.textFile("file.txt") val b = sc.textFile("directory/*.txt") val c = sc.textFile("hdfs://namenode:9000/path/file")
- 21. RDD Transformations - map ● Passing each element through a function ● All items are independently processed. val nums = sc.parallelize(Array(1, 2, 3)) val squares = nums.map(x => x * x) // {1, 4, 9}
- 22. RDD Transformations - groupBy ● Pairs with identical key are grouped. ● Groups are independently processed. val schools = sc.parallelize(Seq(("sics", 1), ("kth", 1), ("sics", 2))) schools.groupByKey() // {("sics", (1, 2)), ("kth", (1))} schools.reduceByKey((x, y) => x + y) // {("sics", 3), ("kth", 1)}
- 23. Basic RDD Actions ● Return all the elements of the RDD as an array. ● Return an array with the first n elements of the RDD. ● Return the number of elements in the RDD. val nums = sc.parallelize(Array(1, 2, 3)) nums.collect() // Array(1, 2, 3) nums.take(2) // Array(1, 2) nums.count() // 3
- 24. Fault Tolerance Transformations on RDDs are represented as a lineage graph, a DAG representing the computations done on the RDD. RDD itself contains all the dependency informa‐ tion needed to recreate each of its partitions. val rdd = sc.textFile(...) val filtered = rdd.map(...).filter(...) val count = filtered.count() val reduced = filtered.reduce()
- 25. Checkpointing ● It prevents RDD graph from growing too large. ● RDD is saved to a file inside the checkpointing directory. ● All references to its parent RDDs are removed. ● Done lazily, saved to disk the first time it is computed. ● You can force it: rdd.checkpoint()
- 26. Caching There are many ways to configure how the data is persisted: ● MEMORY_ONLY (default): in memory as regular java objects (just like a regular Java program - least used elements are evacuated by JVM) ● DISK_ONLY: on disk as regular java objects ● MEMORY_ONLY_SER: in memory as serialize Java objects (more compact since uses byte arrays) ● MEMORY_AND_DISK: both in memory and on disk (spill over to disk to avoid re-computation) ● MEMORY_AND_DISK_SER: on disk as serialize Java objects (more compact since uses byte arrays)
- 27. RDD Transformations (revisited) ● Narrow Dependencies: an output RDD has partitions that originate from a single partition in the parent RDD (e.g. map, filter) ● Wide Dependencies: the data required to compute the records in a single partition may reside in many partitions on the parent RDD (e.g. groupByKey, reduceByKey)
- 28. Spark Application Tree Spark groups narrow transformations as a stage which is called pipelining. At a high level, one stage can be thought of as the set of computations (tasks) that can each be computed on one executor without communication with other executors or with the driver.
- 29. Stage boundaries //stage 0 counts = sc.textFile("/path/to/input/") .flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) //stage 1 .reduceByKey(lambda a, b: a + b) counts.saveAsTextFile("/path/to/output/") In general, a new stage begins whenever network communication between workers is required (for instance, in a shuffle).
- 30. Spark Programming Model ● Spark expresses computation by defining RDDs ● Based on parallelizable operators: higher-order functions that execute user defined functions in parallel ● A data flow is composed of any number of data sources and operators:
- 31. How do RDDs evolve into tasks?
- 32. Spark Execution Model An application maps to a single driver process and a set of executor processes distributed across the hosts in a cluster. The executors are responsible for performing work, in the form of tasks, as well as for storing any data. Invoking an action triggers the launch of a job to fulfill it. A stage is a collection of tasks that run the same code, each on a different subset of the data. task result
- 33. Parallelism more partitions = more parallelism
- 34. How to run Spark ● Interactive Mode: spark-shell or Spark Notebook ● Batch Mode: spark-submit Deployment Modes : ● Local ● Standalone ● YARN Cluster ● Mesos Cluster ● Kubernetes Runs Everywhere
- 35. Interactive Spark application $ bin/sparkshell Using Spark's default log4j profile: org/apache/spark/log4jdefaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://192.168.1.137:4041 Spark context available as 'sc' (master = local[*], app id = local1534089873554). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/_,_/_/ /_/_ version 2.1.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64Bit Server VM, Java 1.8.0_181) Type in expressions to have them evaluated. Type :help for more information. scala> sc res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@281963c scala>
- 36. Standalone Application You need to import the Spark packages in your program and create a SparkContext (driver program): ● Initializing Spark in Python from pyspark import SparkConf, SparkContext conf = SparkConf().setMaster(“local”).setAppName(“My App”) sc = SparkContext(conf = conf) ● Initializing Spark in Scala import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ val conf = new SparkConf().setMaster(“local”).setAppName(“My App”) val sc = new SparkContext(conf)
- 37. Batch Mode sparksubmit master MASTER_URL spark://host:port, mesos://host:port, yarn, or local deploymode DEPLOY_MODE (client or cluster) name NAME (name of the application) jars JARS (list of jars to be added to classpath of the driver and executors) conf PROP=VALUE (spark configurations) drivermemory MEM (Memory for the driver program. Format 300M or 1G) executormemory MEM (Memory for executor. Format 500M or 2G) drivercores NUM (Cores for drivers – applicable for YARN and standalone) executorcores NUM (Cores for executors – applicable for YARN and standalone) numexecutors NUM (Number of executors to launch (Default: 2)) Launch the application via spark-submit command:
- 38. Spark job running on HDFS
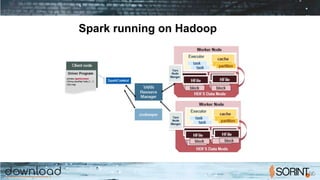
- 39. Spark running on Hadoop
- 40. Advantages of running on Hadoop ● YARN resource manager, which takes responsibility for scheduling tasks across available nodes in the cluster. ● Hadoop Distributed File System, which stores data when the cluster runs out of free memory, and which persistently stores historical data when Spark is not running. ● Disaster Recovery capabilities, inherent to Hadoop, which enable recovery of data when individual nodes fail. ● Data Security, which becomes increasingly important as Spark tackles production workloads in regulated industries such as healthcare and financial services. Projects like Apache Knox and Apache Ranger offer data security capabilities that augment Hadoop.
- 41. SCALING Thanks to Holden Karau and her lesson in unintended consequences.
- 42. Scaling tips ● Spark only “understands” the program to the point we have an action (not like a compiler) ● If we are going to re-use an RDD better caching it in memory or persisting at an another level (MEMORY_AND_DISK, ..) ● In a shared environment checkpointing can help ● Persist before checkpointing (gets rid of the lineage)
- 43. Key-Value Data Scaling ● What does the distribution of keys look like? ● What type of aggregations do we need to do? ● What’s partition structure ● ...
- 44. Key Skew Keys not evenly distributed (e.g. zip code, null values) ● Straggler: a task which takes much longer to complete than the other ones ● The function groupByKey groups all of the records with the same key into a single record. When called all the key-value pairs are shuffled around (data is transferred over the network). By default, Spark uses hash partitioning to determine which key-value pair should be sent to which machine. ● Spark flushes out the data to disk one key at a time, so key-value pairs can be too big to fit in memory (OOM) ● If we have enough key skew, sortByKey will explode too. Sorting the key can put all records in the same partition.
- 45. groupByKey vs reduceByKey val words = Array("one", "two", "two", "three", "three", "three") val wordPairsRDD = sc.parallelize(words).map(word => (word, 1)) val wordCountsWithReduce = wordPairsRDD .reduceByKey(_ + _) .collect() val wordCountsWithGroup = wordPairsRDD .groupByKey() .map(t => (t._1, t._2.sum)) .collect()
- 46. groupByKey vs reduceByKey By reducing the dataset first, the amount of data sent over the network during the shuffle is greatly reduced
- 47. Shuffle explosion (sortByKey) All the examples by lessons of Holden Karau in unintended consequences
- 48. Shuffle “caching” ● Spark keeps shuffle files so that they can be re-used ● Shuffle files live in the driver program memory until GC is triggered ● You need to trigger a GC event on the worker to free the memory or call the API function to cleanup shuffle memory ● Enable off-heap memory: shuffle data structures are allocated out of JVM memory
- 49. Summary Spark offers an innovative, efficient model of parallel computing that centers on lazily evaluated, immutable, distributed datasets, known as RDDs. RDD methods can be used without any knowledge of their implementation - but having an understanding of the details will help you write more performant code.
- 51. Structured vs Unstructured Data Spark and RDDs don't know anything about the schema of the data it's dealing with.
- 52. Spark vs Databases In Spark: ● we do functional transformations on data ● we pass user defined function literal to higher order functions like map, flatMap, filter In Database/Hive: ● we do declarative transformations on data ● Specialized and structured, pre- defined operations Eg. SELECT * FROM * WHERE *
- 53. Spark SQL: DataFrames, Datasets Like RDDs, DataFrames and Datasets represent distributed collections, with additional schema information not found in RDDs. This additional schema informationis used to provide a more efficient storage layer (Tungsten), and in the optimizer (Catalyst) to perform additional optimizations. ● DataFrames and Datasets have a specialized representation and columnar cache format. ● Instead of specifying arbitrary functions, which the optimizer is unable to introspect, you use a restricted expression syntax so the optimizer can have more information.
- 54. DataFrames A DataFrame is a distributed collection of data organized into named columns. DataFrames can be created from different data sources such as: • existing RDDs • structured data files • JSON datasets • Hive tables • external databases (via JDBC)
- 55. DataFrame API example val employeeDF = sc.textFile(...).toDF employeeDF.show() // employeeDF: // +---+-----+-------+---+--------+ // | id|fname| lname |age| city | // +---+-----+-------+---+--------+ // | 12| Joe| Smith| 38|New York| // |563|Sally| Owens| 48|New York| // |645|Slate|Markham| 28| Sydney| // |221|David| Walker| 21| Sydney| // +---+-----+-------+---+--------+ val sydneyEmployeesDF = sparkSession.select("id", "lname") .where("city = sydney") .orderBy("id") // sydneyEmployeesDF: // +---+-------+ // | id| lname| // +---+-------+ // |221| Walker| // |645|Markham| // +---+-------+
- 56. RDD versus DataFrame storage size
- 57. DataFrames vs DataSets DataFrames ● Relational flavour ● Lack of compile-time type checking ● DataFrames are a specialized version of Datasets that operate on generic Row objects DataSets ● Mix of relational and functional transformations ● Compile-time type checking ● Can be used when you know the type information at compile time ● Datasets can be easily converted to/from DataFrames and RDDs
- 58. DataFrames/DataSets vs RDDs DataFrames/DataSets ● Catalyst Optimizer ● Efficient storage format ● Restrict subset of data types ● DataFrames are not strongly typed ● Dataset API is continuing to evolve RDDs ● Unstructured data ● Wider variety of data types ● Not primarly relational transformations ● Number of partitions needed for different parts of your pipeline changes
- 59. User-Defined Functions and Aggregate Functions (UDFs, UDAFs) User-defined functions and user-defined aggregate functions provide you with ways to extend the DataFrame and SQL APIs with your own custom code while keeping the Catalyst optimizer. If most of your work is in Python but you want to access some UDFs without the performance penalty, you can write your UDFs in Scala and register them for use in Python.
- 62. Spark Streaming Spark Streaming is an extension of the core Spark API that makes it easy to build fault-tolerant processing of real-time data streams. It works by dividing the live stream of data into batches (called micro- batches) of a pre-defined interval (N seconds) and then treating each batch of data as a RDD. Each RDD contains only a little chunk of incoming data.
- 63. Spark Streaming With Spark Streaming’s micro-batch approach, we can use other Spark libraries (core, ML, SQL) with the Spark Streaming API in the same application.
- 64. DStream DStream (short for “discretized stream”) is the basic abstraction in Spark Streaming and represents a continuous stream of data. Internally, a DStream is represented as a sequence of RDD objects: Similar to the transformation and action operations on RDDs, Dstreams support the following operations: map, flatMap, filter, count, reduce, countByValue, reduceByKey, join, updateStateByKey
- 65. Netcat Streaming Example import org.apache.spark.streaming.{StreamingContext, Seconds} val ssc = new StreamingContext(sc, Seconds(10)) // This listens to log data sent into port 9999, one second at a time val lines = ssc.socketTextStream("localhost", 9999) // Wordcount val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) wordCounts.print() // You need to kick off the job explicitly ssc.start() ssc.awaitTermination()
- 66. Netcat Streaming Example ... Time: 1535630570000 ms (how,1) (into,1) (go,1) (what,1) (program,,1) (want,1) (looks,1) (program,1) (Spark,2) (a,4) ... Time: 1535630580000 ms [sparkuser@horst ~]$ nc lk 9999 ... Spark Streaming is a special SparkContext that you can use for processing data quickly in neartime. It’s similar to the standard SparkContext, which is geared toward batch operations. Spark Streaming uses a little trick to create small batch windows (micro batches) that offer all of the advantages of Spark: safe, fast data handling and lazy evaluation combined with realtime processing. It’s a combination of both batch and interactive processing. ...
- 67. Twitter Example val ssc = new StreamingContext(conf, Seconds(1)) // Get a Twitter stream and extract just the messages themselves val tweets = TwitterUtils.createStream(ssc, None) val statuses = tweets.map(_.getText()) // Create a new Dstream that has every individual word as its own entry val tweetwords = statuses.flatMap(_.split(“ “)) // Eliminate anything that’s not a hashtag val hashtags = tweetwords.filter(_.startsWith(“#“)) // Convert RRD to key/value pairs val hashtagKeyValues = hashtags.map(hashtag => (hashtag, 1)) // Count up the results over a sliding window val hashtagCounts = hashtagKeyValues.reduceByKeyAndWindow(_+_,__, Seconds(300), Seconds(1)) // Sort and output the results val sortedResults = hashtagCounts.transform(_.sortBy(x._2), false) SortedResults.print
- 68. Real Use Cases • Uber, the ride-sharing service, uses Spark Streaming in their continuous- streaming ETL pipeline to collect terabytes of event data every day from their mobile users for real-time telemetry analysis. • Pinterest uses Spark Streaming, MemSQL, and Apache Kafka technologies to provide real-time insight into how their users are engaging with pins across the globe. • Netflix uses Kafka and Spark Streaming to build a real-time online movie recommendation and data-monitoring solution that processes billions of events received per day from different data sources.
- 69. Conclusions A lightning fast cluster computing framework Apache Spark can help you to address the challenges of Data Science…. A unified engine supporting diverse workloads & environments. Fault-tolerant and Scalable. From simple ETL to complex Machine Learning jobs
- 70. You won’t be a Spark superhero, but...