Apache Spark Workshop at Hadoop Summit
1 like624 views

This document provides an overview of installing and programming with Apache Spark on the Hortonworks Data Platform (HDP). It discusses how Spark fits within HDP and can be used for batch processing, streaming, SQL queries and machine learning. The document outlines how to install Spark on HDP using Ambari and describes Spark programming with Resilient Distributed Datasets (RDDs), transformations, actions and caching/persistence. It provides examples of Spark APIs and programming patterns.








![Page 9 © Hortonworks Inc. 2014
What is Spark?
• Spark is
– an open-source software solution that performs rapid calculations
on in-memory datasets
- Open Source [Apache hosted & licensed]
• Free to download and use in production
• Developed by a community of developers
- In-memory datasets
• RDD (Resilient Distributed Data) is the basis for what Spark enables
• Resilient – the models can be recreated on the fly from known state
• Distributed – the dataset is often partitioned across multiple nodes for
increased scalability and parallelism](https://image.slidesharecdn.com/spark-workshop-final-150624020145-lva1-app6891/85/Apache-Spark-Workshop-at-Hadoop-Summit-9-320.jpg)











![Page 21 © Hortonworks Inc. 2014
1. Resilient Distributed Dataset [RDD] Graph
val v = sc.textFile("hdfs://…some-‐hdfs-‐data")
mapmap reduceByKey collecttextFile
v.flatMap(line=>line.split(" "))
.map(word=>(word, 1)))
.reduceByKey(_ + _, 3)
.collect()
RDD[String]
RDD[List[String]]
RDD[(String, Int)]
Array[(String, Int)]
RDD[(String, Int)]](https://image.slidesharecdn.com/spark-workshop-final-150624020145-lva1-app6891/85/Apache-Spark-Workshop-at-Hadoop-Summit-21-320.jpg)

![Page 23 © Hortonworks Inc. 2014
Looking at the State in the Machine
//run debug command to inspect RDD:
scala> fltr.toDebugString
//simplified output:
res1: String =
FilteredRDD[2] at filter at <console>:14
MappedRDD[1] at textFile at <console>:12
HadoopRDD[0] at textFile at <console>:12
23](https://image.slidesharecdn.com/spark-workshop-final-150624020145-lva1-app6891/85/Apache-Spark-Workshop-at-Hadoop-Summit-23-320.jpg)


![Page 26 © Hortonworks Inc. 2014
And Finally – the Formal ‘def’
def myFunc(line:String): Array[String]={
return line.split(",")
}
//and now that it has a name:
myFunc("Hi Mom, I’m home.").foreach(println)
Return type of the function)
Body of the function
Argument to the function)](https://image.slidesharecdn.com/spark-workshop-final-150624020145-lva1-app6891/85/Apache-Spark-Workshop-at-Hadoop-Summit-26-320.jpg)



![Page 31 © Hortonworks Inc. 2014
What About Integration With Hive?
scala> val hiveCTX = new org.apache.spark.sql.hive.HiveContext(sc)
scala> hiveCTX.hql("SHOW TABLES").collect().foreach(println)
…
[omniture]
[omniturelogs]
[orc_table]
[raw_products]
[raw_users]
…
31](https://image.slidesharecdn.com/spark-workshop-final-150624020145-lva1-app6891/85/Apache-Spark-Workshop-at-Hadoop-Summit-31-320.jpg)
![Page 32 © Hortonworks Inc. 2014
More Integration With Hive:
scala> hCTX.hql("DESCRIBE raw_users").collect().foreach(println)
[swid,string,null]
[birth_date,string,null]
[gender_cd,string,null]
scala> hCTX.hql("SELECT * FROM raw_users WHERE gender_cd='F' LIMIT
5").collect().foreach(println)
[0001BDD9-EABF-4D0D-81BD-D9EABFCD0D7D,8-Apr-84,F]
[00071AA7-86D2-4EB9-871A-A786D27EB9BA,7-Feb-88,F]
[00071B7D-31AF-4D85-871B-7D31AFFD852E,22-Oct-64,F]
[000F36E5-9891-4098-9B69-CEE78483B653,24-Mar-85,F]
[00102F3F-061C-4212-9F91-1254F9D6E39F,1-Nov-91,F]
32](https://image.slidesharecdn.com/spark-workshop-final-150624020145-lva1-app6891/85/Apache-Spark-Workshop-at-Hadoop-Summit-32-320.jpg)




Apache Spark Workshop at Hadoop Summit
- 1. Page 1 © Hortonworks Inc. 2014 In-memory processing with Apache Spark Dhruv Kumar and Saptak Sen Hortonworks. We do Hadoop. June 9, 2015
- 2. Page 2 © Hortonworks Inc. 2014 About the presenters Saptak Sen Technical Product Manager Hortonworks Inc. Dhruv Kumar Partner Solutions Engineer. Hortonworks Inc.
- 3. Page 3 © Hortonworks Inc. 2014 In this workshop • Introduction to HDP and Spark • Installing Spark on HDP • Spark Programming • Core Spark: working with RDDs • Spark SQL: structured data access • Conclusion and Further Reading, Q/A
- 4. Page 4 © Hortonworks Inc. 2014 Installing Spark on HDP
- 5. Page 5 © Hortonworks Inc. 2014 Installing Spark on HDP • If you have Hortonworks Sandbox with HDP 2.2.4.2 you have Spark 1.2.1 • If you have Hortonworks Sandbox with HDP 2.3 Preview you have Spark 1.3.1 • If you have Hortonworks Sandbox on Azure you will need to install Spark For instructions and workshop content goto http://saptak.in/spark • GA of Spark 1.3.1 – Fully supported by Hortonworks – Install with Ambari HDP 2.2.2. Other combination unsupported.
- 6. Page 6 © Hortonworks Inc. 2014 Introduction to HDP and Spark
- 7. Page 7 © Hortonworks Inc. 2014 HDP delivers a comprehensive data management platform HDP 2.2 Hortonworks Data Platform Provision, Manage & Monitor Ambari Zookeeper Scheduling Oozie Data Workflow, Lifecycle & Governance Falcon Sqoop Flume NFS WebHDFS YARN: Data Operating System DATA MANAGEMENT SECURITY BATCH, INTERACTIVE & REAL-TIME DATA ACCESS GOVERNANCE & INTEGRATION Authentication Authorization Accounting Data Protection Storage: HDFS Resources: YARN Access: Hive, … Pipeline: Falcon Cluster: Knox OPERATIONS Script Pig Search Solr SQL Hive HCatalog NoSQL HBase Accumulo Stream Storm Other ISVs 1 ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° N HDFS (Hadoop Distributed File System) In-Memory Spark Deployment Choice Linux Windows On- Premise Cloud YARN is the architectural center of HDP • Enables batch, interactive and real-time workloads • Single SQL engine for both batch and interactive • Enables best of breed ISV tools to deeply integrate into Hadoop via YARN Provides comprehensive enterprise capabilities • Governance • Security • Operations The widest range of deployment options • Linux & Windows • On premise & cloud TezTez
- 8. Page 8 © Hortonworks Inc. 2014 Let’s drill into one workload … Spark HDP 2.1 Hortonworks Data Platform Provision, Manage & Monitor Ambari Zookeeper Scheduling Oozie Data Workflow, Lifecycle & Governance Falcon Sqoop Flume NFS WebHDFS YARN: Data Operating System DATA MANAGEMENT SECURITY BATCH, INTERACTIVE & REAL-TIME DATA ACCESS GOVERNANCE & INTEGRATION Authentication Authorization Accounting Data Protection Storage: HDFS Resources: YARN Access: Hive, … Pipeline: Falcon Cluster: Knox OPERATIONS Script Pig Search Solr SQL Hive HCatalog NoSQL HBase Accumulo Stream Storm Other ISVs 1 ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° N HDFS (Hadoop Distributed File System) Deployment Choice Linux Windows On- Premise Cloud YARN is the architectural center of HDP • Enables batch, interactive and real-time workloads • Single SQL engine for both batch and interactive • Enables best of breed ISV tools to deeply integrate into Hadoop via YARN Provides comprehensive enterprise capabilities • Governance • Security • Operations The widest range of deployment options • Linux & Windows • On premise & cloud TezTez In-Memory
- 9. Page 9 © Hortonworks Inc. 2014 What is Spark? • Spark is – an open-source software solution that performs rapid calculations on in-memory datasets - Open Source [Apache hosted & licensed] • Free to download and use in production • Developed by a community of developers - In-memory datasets • RDD (Resilient Distributed Data) is the basis for what Spark enables • Resilient – the models can be recreated on the fly from known state • Distributed – the dataset is often partitioned across multiple nodes for increased scalability and parallelism
- 10. Page 10 © Hortonworks Inc. 2014 Spark Components Spark allows you to do data processing, ETL, machine learning, stream processing, SQL querying from one framework
- 11. Page 11 © Hortonworks Inc. 2014 Why Spark? • One tool for data engineering and data science tasks • Native integration with Hive, HDFS and any Hadoop FileSystem implementation • Faster development: concise API, Scala (~3x lesser code than Java) • Faster execution: for iterative jobs because of in-memory caching (not all workloads are faster in Spark) • Promotes code reuse: APIs and data types are similar for batch and streaming
- 12. Page 12 © Hortonworks Inc. 2014 Hortonworks Commitment to Spark Hortonworks is focused on making Apache Spark enterprise ready so you can depend on it for mission critical applications YARN: Data Operating System SECURITY BATCH, INTERACTIVE & REAL-TIME DATA ACCESS GOVERNANCE & INTEGRATION OPERATIONS Script Pig Search Solr SQL Hive HCatalog NoSQL HBase Accumulo Stream Storm Other ISVs TezTez In-Memory 1. YARN enable Spark to co-exist with other engines Spark is “YARN Ready” so its memory & CPU intensive apps can work with predictable performance along side other engines all on the same set(s) of data. 2. Extend Spark with enterprise capabilities Ensure Spark can be managed, secured and governed all via a single set of frameworks to ensure consistency. Ensure reliability and quality of service of Spark along side other engines. 3. Actively collaborate within the open community As with everything we do at Hortonworks we work entirely within the open community across Spark and all related projects to improve this key Hadoop technology.
- 13. Page 13 © Hortonworks Inc. 2014 Reference Deployment Architecture Batch Source Streaming Source Reference Data Stream Processing Storm/Spark-Streaming Data Pipeline Hive/Pig/Spark Long Term Data Warehouse Hive + ORC Data Discovery Operational Reporting Business Intelligence Ad Hoc/On Demand Source Data Science Spark-ML, Spark-SQL Advanced Analytics Data Sources Data Processing, Storage & Analytics Data Access Hortonworks Data Platform
- 14. Page 14 © Hortonworks Inc. 2014 Spark Deployment Modes Mode setup with Ambari • Spark Standalone Cluster – For developing Spark apps against a local Spark (similar to develop/deploying in IDE) • Spark on YARN – Spark driver (SparkContext) in YARN AM(yarn-cluster) – Spark driver (SparkContext) in local (yarn-client) • Spark Shell runs in yarn-client only Client Executor App Master Client Executor App Master Spark Driver Spark Driver YARN-Client YARN-Cluster
- 15. Page 15 © Hortonworks Inc. 2014 Spark on YARN YARN RM App Master Monitoring UI
- 16. Page 16 © Hortonworks Inc. 2014 Programming Spark
- 17. Page 17 © Hortonworks Inc. 2014 How Does Spark Work? • RDD • Your data is loaded in parallel into structured collections • Actions • Manipulate the state of the working model by forming new RDDs and performing calculations upon them • Persistence • Long-term storage of an RDD’s state
- 18. Page 18 © Hortonworks Inc. 2014 Example RDD Transformations •map(func) •filter(func) •distinct(func) • All create a new DataSet from an existing one • Do not create the DataSet until an action is performed (Lazy) • Each element in an RDD is passed to the target function and the result forms a new RDD
- 19. Page 19 © Hortonworks Inc. 2014 Example Action Operations •count() •reduce(func) •collect() •take() • Either: • Returns a value to the driver program • Exports state to external system
- 20. Page 20 © Hortonworks Inc. 2014 Example Persistence Operations •persist() -- takes options •cache() -- only one option: in-memory • Stores RDD Values • in memory (what doesn’t fit is recalculated when necessary) • Replication is an option for in-memory • to disk • blended
- 21. Page 21 © Hortonworks Inc. 2014 1. Resilient Distributed Dataset [RDD] Graph val v = sc.textFile("hdfs://…some-‐hdfs-‐data") mapmap reduceByKey collecttextFile v.flatMap(line=>line.split(" ")) .map(word=>(word, 1))) .reduceByKey(_ + _, 3) .collect() RDD[String] RDD[List[String]] RDD[(String, Int)] Array[(String, Int)] RDD[(String, Int)]
- 22. Page 22 © Hortonworks Inc. 2014 Processing A File in Scala //Load the file: val file = sc.textFile("hdfs://…/user/DAW/littlelog.csv") //Trim away any empty rows: val fltr = file.filter(_.length > 0) //Print out the remaining rows: fltr.foreach(println) 22
- 23. Page 23 © Hortonworks Inc. 2014 Looking at the State in the Machine //run debug command to inspect RDD: scala> fltr.toDebugString //simplified output: res1: String = FilteredRDD[2] at filter at <console>:14 MappedRDD[1] at textFile at <console>:12 HadoopRDD[0] at textFile at <console>:12 23
- 24. Page 24 © Hortonworks Inc. 2014 A Word on Anonymous Functions Scala programmers make great use of anonymous functions as can be seen in the code: flatMap( line => line.split(" ") ) 24 Argument to the function Body of the function
- 25. Page 25 © Hortonworks Inc. 2014 Scala Functions Come In a Variety of Styles flatMap( line => line.split(" ") ) flatMap((line:String) => line.split(" ")) flatMap(_.split(" ")) 25 Argument to the function (type inferred) Body of the function Argument to the function (explicit type) Body of the function No Argument to the function declared (placeholder) instead Body of the function includes placeholder _ which allows for exactly one use of one arg for each _ present. _ essentially means ‘whatever you pass me’
- 26. Page 26 © Hortonworks Inc. 2014 And Finally – the Formal ‘def’ def myFunc(line:String): Array[String]={ return line.split(",") } //and now that it has a name: myFunc("Hi Mom, I’m home.").foreach(println) Return type of the function) Body of the function Argument to the function)
- 27. Page 27 © Hortonworks Inc. 2014 Things You Can Do With RDDs • RDDs are objects and expose a rich set of methods: 27 Name Description Name Description filter Return a new RDD containing only those elements that satisfy a predicate collect Return an array containing all the elements of this RDD count Return the number of elements in this RDD first Return the first element of this RDD foreach Applies a function to all elements of this RDD (does not return an RDD) reduce Reduces the contents of this RDD subtract Return an RDD without duplicates of elements found in passed-in RDD union Return an RDD that is a union of the passed-in RDD and this one
- 28. Page 28 © Hortonworks Inc. 2014 More Things You Can Do With RDDs • More stuff you can do… 28 Name Description Name Description flatMap Return a new RDD by first applying a function to all elements of this RDD, and then flattening the results checkpoint Mark this RDD for checkpointing (its state will be saved so it need not be recreated from scratch) cache Load the RDD into memory (what doesn’t fit will be calculated as needed) countByValue Return the count of each unique value in this RDD as a map of (value, count) pairs distinct Return a new RDD containing the distinct elements in this RDD persist Store the RDD to either memory, Disk, or hybrid according to passed in value sample Return a sampled subset of this RDD unpersist Clear any record of the RDD from disk/memory
- 29. Page 29 © Hortonworks Inc. 2014 Code ‘select count’ Equivalent SQL Statement: Select count(*) from pagecounts WHERE state = ‘FL’ Scala statement: val file = sc.textFile("hdfs://…/log.txt") val numFL = file.filter(line => line.contains("fl")).count() scala> println(numFL) 29 1. Load the page as an RDD 2. Filter the lines of the page eliminating any that do not contain “fl“ 3. Count those lines that remain 4. Print the value of the counted lines containing ‘fl’
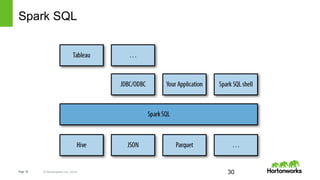
- 30. Page 30 © Hortonworks Inc. 2014 Spark SQL 30
- 31. Page 31 © Hortonworks Inc. 2014 What About Integration With Hive? scala> val hiveCTX = new org.apache.spark.sql.hive.HiveContext(sc) scala> hiveCTX.hql("SHOW TABLES").collect().foreach(println) … [omniture] [omniturelogs] [orc_table] [raw_products] [raw_users] … 31
- 32. Page 32 © Hortonworks Inc. 2014 More Integration With Hive: scala> hCTX.hql("DESCRIBE raw_users").collect().foreach(println) [swid,string,null] [birth_date,string,null] [gender_cd,string,null] scala> hCTX.hql("SELECT * FROM raw_users WHERE gender_cd='F' LIMIT 5").collect().foreach(println) [0001BDD9-EABF-4D0D-81BD-D9EABFCD0D7D,8-Apr-84,F] [00071AA7-86D2-4EB9-871A-A786D27EB9BA,7-Feb-88,F] [00071B7D-31AF-4D85-871B-7D31AFFD852E,22-Oct-64,F] [000F36E5-9891-4098-9B69-CEE78483B653,24-Mar-85,F] [00102F3F-061C-4212-9F91-1254F9D6E39F,1-Nov-91,F] 32
- 33. Page 33 © Hortonworks Inc. 2014 Querying RDD Using SQL // SQL statements can be run directly on RDD’s val teenagers = sqlC.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19") // The results of SQL queries are SchemaRDDs and support // normal RDD operations: val nameList = teenagers.map(t => "Name: " + t(0)).collect() // Language integrated queries (ala LINQ) val teenagers = people.where('age >= 10).where('age <= 19).select('name)
- 34. Page 34 © Hortonworks Inc. 2014 Conclusion and Resources
- 35. Page 35 © Hortonworks Inc. 2014 Conclusion • Spark is a unified framework for data engineering and data science • Spark can be programmed in Scala, Java and Python. • Spark issupported by Hortonworks • Certain workloads are faster in Spark because of in-memory caching.
- 36. Page 36 © Hortonworks Inc. 2014 References and Further Reading • Apache Spark website: https://spark.apache.org/ • Hortonworks Spark website: http://hortonworks.com/hadoop/spark/ • Hortonworks Sandbox Tutorials https://hortonworks.com/tutorials • “Learning Spark” by O’Reilly Publishers