Asynchronous Hyperparameter Optimization with Apache Spark
1 like608 views

The document discusses asynchronous hyperparameter optimization using Apache Spark, focusing on making Spark more efficient for directed search tasks. It highlights the challenges of traditional bulk-synchronous methods and introduces Maggy, a framework for black-box optimization tailored for Spark. The presentation also outlines advancements in machine learning platforms and the need for support in automated hyperparameter tuning and ablation studies.






![The Complexity of Deep
Learning
8
Data validation
Distributed
Training
Model
Serving
A/B
Testing
Monitoring
Pipeline
Management
HyperParameter
Tuning
Feature Engineering
Data
Collection
Hardware
Management
Data Model Prediction
φ(x)
[Adapted from Schulley et al “Technical Debt of ML” ]](https://image.slidesharecdn.com/moritzmeisterjimdowling-191029231637/85/Asynchronous-Hyperparameter-Optimization-with-Apache-Spark-8-320.jpg)
![The Complexity of Deep
Learning
9
Data validation
Distributed
Training
Model
Serving
A/B
Testing
Monitoring
Pipeline
Management
HyperParameter
Tuning
Feature Engineering
Data
Collection
Hardware
Management
Data Model Prediction
φ(x)
Hopsworks
Feature Store
Hopsworks
REST API
[Adapted from Schulley et al “Technical Debt of ML” ]](https://image.slidesharecdn.com/moritzmeisterjimdowling-191029231637/85/Asynchronous-Hyperparameter-Optimization-with-Apache-Spark-9-320.jpg)




![Engines Matter!
15
[Image from https://twitter.com/_youhadonejob1/status/1143968337359187968?s=20]](https://image.slidesharecdn.com/moritzmeisterjimdowling-191029231637/85/Asynchronous-Hyperparameter-Optimization-with-Apache-Spark-14-320.jpg)

























Asynchronous Hyperparameter Optimization with Apache Spark
- 1. Jim Dowling, Logical Clocks AB and KTH Moritz Meister, Logical Clocks AB Asynchronous Hyperparameter Optimization with Apache Spark #UnifiedDataAnalytics #SparkAISummit @jim_dowling @morimeister
- 2. The Bitter Lesson (of AI)* “Methods that scale with computation are the future of AI”** 2 ** https://www.youtube.com/watch?v=EeMCEQa85tw Rich Sutton (Father of Reinforcement Learning) * http://www.incompleteideas.net/IncIdeas/BitterLesson.html “The two (general purpose) methods that seem to scale ... are search and learning.”*
- 3. Spark scales with available compute => Spark is the answer! This talk is about why bulk- synchronous parallel compute (Spark) does not scale efficiently for search and how we made Spark efficient for directed search (task-based asynchronous parallel compute). 3
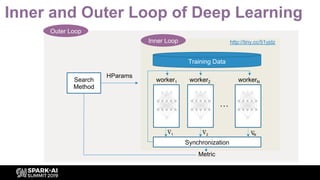
- 4. Inner and Outer Loop of Deep Learning Inner Loop Outer Loop Training Data worker1 worker2 workerN … ∆ 1 ∆ 2 ∆ N Synchronization Metric Search Method HParams http://tiny.cc/51yjdz
- 5. Inner and Outer Loop of Deep Learning Inner Loop Outer Loop Training Data worker1 worker2 workerN … ∆ 1 ∆ 2 ∆ N Synchronization Metric Search Method HParams http://tiny.cc/51yjdz LEARNINGSEARCH
- 6. 6 Hopsworks – a platform for Data-Intensive AI
- 7. Hopsworks Technical Milestones 7 World’s first Hadoop platform to support GPUs-as-a-Resource World’s fastest HDFS Published at USENIX FAST with Oracle and Spotify World’s First Open Source Feature Store for Machine Learning World’s First Distributed Filesystem to store small files in metadata on NVMe disks Winner of IEEE Scale Challenge 2017 with HopsFS - 1.2m ops/sec 2017 World’s most scalable POSIX-like Hierarchical Filesystem with Multi Data Center Availability with 1.6m ops/sec on GCP 2018 2019 First non-Google ML Platform with TensorFlow Extended (TFX) support through Beam/Flink World’s first Unified Hyperparam and Ablation Study Framework
- 8. The Complexity of Deep Learning 8 Data validation Distributed Training Model Serving A/B Testing Monitoring Pipeline Management HyperParameter Tuning Feature Engineering Data Collection Hardware Management Data Model Prediction φ(x) [Adapted from Schulley et al “Technical Debt of ML” ]
- 9. The Complexity of Deep Learning 9 Data validation Distributed Training Model Serving A/B Testing Monitoring Pipeline Management HyperParameter Tuning Feature Engineering Data Collection Hardware Management Data Model Prediction φ(x) Hopsworks Feature Store Hopsworks REST API [Adapted from Schulley et al “Technical Debt of ML” ]
- 10. 10
- 11. 11
- 12. 12 Datasources Applications API Dashboards Hopsworks Apache Beam Apache Spark Pip Conda Tensorflow scikit-learn Keras J upyter Notebooks Tensorboard Apache Beam Apache Spark Apache Flink Kubernetes Batch Distributed ML &DL Model Serving Hopsworks Feature Store Kafka + Spark Streaming Model Monitoring Orchestration in Airflow Data Preparation &Ingestion Experimentation &Model Training Deploy &Productionalize Streaming Filesystem and Metadata storage HopsFS
- 13. “AI is the new Electricity” – Andrew Ng 14 What engine should we use?
- 14. Engines Matter! 15 [Image from https://twitter.com/_youhadonejob1/status/1143968337359187968?s=20]
- 15. Engines Really Matter! 16 Photo by Zbynek Burival on Unsplash
- 16. Hopsworks Engine: ML Pipelines 17 Data Pipelines Ingest & Prep Feature Store Machine Learning Experiments Data Parallel Training Model Serving Ablation Studies Hyperparameter Optimization Bottleneck, due to • iterative nature • human interaction Horizontal Scalability at all Stages
- 17. Iterative Model Development • Trial and Error is slow • Iterative approach is greedy • Search spaces are usually large • Sensitivity and interaction of hyperparameters 18 Set Hyper- parameters Train Model Evaluate Performance
- 18. Black Box Optimization 19 Learning Black Box Metric Meta-level learning & optimization Search space
- 19. Parallel Black Box Optimization 20 Which algorithm to use for search? How to monitor progress? Fault Tolerance?How to aggregate results? Learning Black Box Metric Meta-level learning & optimization Parallel WorkersQueue Trial Trial Search space
- 20. Parallel Black Box Optimization 21 Which algorithm to use for search? How to monitor progress? Fault Tolerance?How to aggregate results? Learning Black Box Metric Meta-level learning & optimization Parallel WorkersQueue Trial Trial Search space This should be managed with platform support!
- 21. Maggy A flexible framework for running different black-box optimization algorithms on Hopsworks: ASHA, Bayesian Optimization, Random Search, Grid Search and more to come… 22
- 23. Add Early Stopping 24 Task11 Driver Task12 Task13 Task1N … HDFS Task21 Task22 Task23 Task2N … Barrier Barrier Task31 Task32 Task33 Task3N … Barrier Metrics1 Metrics2 Metrics3 Wasted Compute Wasted ComputeWasted Compute
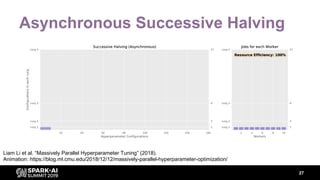
- 24. Performance Enhancement 25 Early Stopping: ● Median Stopping Rule ● Performance curve prediction Multi-fidelity Methods: ● Successive Halving Algorithm ● Hyperband Figure: Successive Halving Algorithm
- 25. 26 Synchronous Successive Halving Kevin G. Jamieson et al. “Non-stochastic Best Arm Identification and Hyperparameter Optimization” (2015). Animation: https://blog.ml.cmu.edu/2018/12/12/massively-parallel-hyperparameter-optimization/
- 26. 27 Asynchronous Successive Halving Liam Li et al. “Massively Parallel Hyperparameter Tuning” (2018). Animation: https://blog.ml.cmu.edu/2018/12/12/massively-parallel-hyperparameter-optimization/
- 27. Challenge How can we fit this into the bulk synchronous execution model of Spark? Mismatch: Spark Tasks and Stages vs. Trials 28 Databricks’ approach: Project Hydrogen (barrier execution mode) & SparkTrials in Hyperopt
- 28. 29 Task11 Driver Task12 Task13 Task1N … Barrier Metrics New Trial Early Stop The Solution Long running tasks:
- 29. Enter Maggy 31
- 30. User API 32
- 31. Developer API 33
- 32. Results 34 Hyperparameter Optimization Task ASHA Validation Task ASHA RS-ES RS-NS ASHA RS-ES RS-NS
- 33. Ablation 35 PClassname survivesex sexname survive Replacing the Maggy Optimizer with an Ablator: • Feature Ablation using the Feature Store • Leave-One-Layer-Out Ablation • Leave-One-Component-Out (LOCO)
- 34. Ablation API 36
- 35. Ablation API 37
- 36. Conclusion ● Avoid iterative Hyperparameter Optimization ● Black box optimization is hard ● State-of-the-art algorithms can be deployed asynchronously ● Maggy: platform support for automated hyperparameter optimization and ablation studies ● Save resources with asynchronism ● Early stopping for sensible models 38
- 37. What next? 39 • More algorithms • Comparability of experiments • Implicit Provenance • Support for PyTorch
- 38. Thank you! Box 1263, Isafjordsgatan 22 Kista, Stockholm https://www.logicalclocks.com Register for a free account at www.hops.site Twitter @logicalclocks @hopsworks GitHub https://github.com/hopshadoop/maggy https://maggy.readthedocs.io/en/latest/ https://github.com/logicalclocks/hopsworks
- 39. Acknowledgements and References Thanks to the entire Logical Clocks Team J Contributions from colleagues: Robin Andersson @robzor92 Sina Sheikholeslami @cutlash Kim Hammar @KimHammar1 Alex Ormenisan @alex_ormenisan • Maggy https://github.com/logicalclocks/maggy or https://maggy.readthedocs.io/en/latest/ • Feature Store: the missing data layer in ML pipelines? https://www.logicalclocks.com/feature-store/ • Hopsworks white paper. https://www.logicalclocks.com/whitepapers/hopsworks • ePipe: Near Real-Time Polyglot Persistence of HopsFS Metadata, CCGrid, 2019
- 40. DON’T FORGET TO RATE AND REVIEW THE SESSIONS SEARCH SPARK + AI SUMMIT