Avoiding Log Data Overload in a CI/CD System: Streaming 190 Billion Events and Batch Processing 40 TB/Hour with Joshua Robinson
1 like415 views

The document outlines Pure Storage's log analytics pipeline, emphasizing the volume of data processed and the automated triaging of failures. It describes various stages of log analysis, the infrastructure used, and the need for scalability and throughput optimization. Key takeaways include indexing only necessary data and disaggregating compute and storage for efficient performance.





























Avoiding Log Data Overload in a CI/CD System: Streaming 190 Billion Events and Batch Processing 40 TB/Hour with Joshua Robinson
- 1. 1 © 2018 PURE STORAGE INC. PURE PROPRIETARY How to Avoid Drowning in Logs Joshua Robinson Founding Engineer, FlashBlade Streaming 180 Billion Events/Day and Batching 150 TB/Hour
- 2. 2 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analytics Pipeline in Numbers ü2M events / second ü5 seconds SLA ü0.5 - 1 PB of data / day
- 3. 3 © 2018 PURE STORAGE INC. PURE PROPRIETARY Continuous Integration & Continuous Deployment Source Build Functional Test Stress Test Deploy
- 4. 4 © 2018 PURE STORAGE INC. PURE PROPRIETARY < 5 1 Test coordinator (Jenkins) < 10 < 10 CI/CD works! 100s tests / day < 5 failures Email developer
- 5. 5 © 2018 PURE STORAGE INC. PURE PROPRIETARY 700 failures x 15 min 70,000+ tests / day 20 Triage Engineers 2x in the next 12 months 1500+ VMs 250+ FBs 20+ Jenkins 700+ clients 100+ Engineers Scale Problems
- 6. 6 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Dream 1. Automate triaging of failures 2. Extract performance metrics 3. Save our logs for future use 4. Do all of this in a scalable system 5. Real-time results!
- 7. 7 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Volume Value
- 8. 8 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis v1 Volume Value Save Alert / Take action
- 9. 9 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis v2 Volume Value Save ETL / Add Structure Alert / Take action
- 10. 10 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis v3 Volume Value Save Aggregate / Search ETL / Add Structure Alert / Take action
- 11. 11 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis v10 Volume Value Save Aggregate / Search ETL / Add Structure Alert / Take action
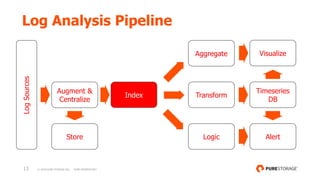
- 12. 12 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline Augment & Centralize LogSources Index Aggregate Transform Logic Timeseries DB AlertStore Visualize
- 13. 13 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline Augment & Centralize LogSources Aggregate Transform Logic Timeseries DB AlertStore Visualize Index
- 14. 14 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline Augment & Centralize LogSources Streaming Buffer Filter Store Aggregate Transform Logic Timeseries DB Alert Visualize Index
- 15. 15 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline Augment & Centralize LogSources Streaming Buffer Filter Store Re-Filter Aggregate Transform Logic Timeseries DB Alert Visualize Index
- 16. 16 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline Augment & Centralize LogSources Streaming Buffer Filter Store Aggregate Transform Logic Timeseries DB Alert Visualize Index Re-Filter
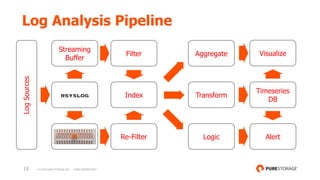
- 17. 17 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline rsyslog LogSources Streaming Buffer Filter Store Re-Filter Aggregate Transform Logic Timeseries DB Alert Visualize Index
- 18. 18 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline rsyslog LogSources Streaming Buffer Filter Re-Filter Aggregate Transform Logic Timeseries DB Alert Visualize Index
- 19. 19 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline rsyslog LogSources Filter Re-Filter Timeseries DB Alert Aggregate Transform Logic Visualize Index
- 20. 20 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline rsyslog LogSources Timeseries DB Alert Aggregate Transform Logic Visualize Index
- 21. 21 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline rsyslog LogSources Timeseries DB Alert Aggregate Transform Logic Visualize
- 22. 22 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline rsyslog LogSources Timeseries DB Alert Visualize
- 23. 23 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline rsyslog LogSources
- 24. 24 © 2018 PURE STORAGE INC. PURE PROPRIETARY Log Analysis Pipeline rsyslog LogSources
- 25. 25 © 2018 PURE STORAGE INC. PURE PROPRIETARY Indexing Use filesystem directory structure to encode metadata • Raw data: <host>/<year>/<month>/<day>/<flat files> • Producer: Rsyslog • Consumer: Spark batch (re-filter or custom lookbacks) • Indexed data: <pattern>/<year>/<month>/<day>/<hour>/<host>/<flat files> • Producer: Spark streaming (filter) • Consumer: Python services (e.g. ETL, alert, searchability)
- 26. 26 © 2018 PURE STORAGE INC. PURE PROPRIETARY Querying Find and load data • FlashBlade NFS protocol. < 1ms latency • Listing • “ls -alR” is still SLOW • NFS client in kernel sequentially discovers filesystem structure. • Solution: Skip the kernel. Use libnfs to create our own parallelized discovery. 1000x faster for 1M files • Reading • Buffering: Create input pipeline to optimize for throughput and hide latency away
- 27. 27 © 2018 PURE STORAGE INC. PURE PROPRIETARY Full Pipeline 2,500+ VMs 300+ FBs 20+ Jenkins 1,000+ clients 72T 12 12 12 12 12 12 12 12 12 12 72T 12 12 12 12 12 12 12 12 12 12 12 12 12 12 120,000+ tests / day 24T rsyslog 16 16 16 16 16 16 800G 12 12 12 12 12 12 ü Duplicate bug ü Infrastructure failure ü Performance regression
- 28. 28 © 2018 PURE STORAGE INC. PURE PROPRIETARY Full Pipeline 2,500+ VMs 350+ FBs 20+ Jenkins 1,000+ clients 72T 12 12 12 12 12 12 12 12 12 12 72T 12 12 12 12 12 12 12 12 12 12 12 12 12 12 120,000+ tests / day 24T rsyslog 16 16 16 16 16 16 800G 12 12 12 12 12 12 ü Duplicate bug ü Infrastructure failure ü Performance regression200T 12 12 12 12 12 12 90G
- 29. 29 © 2018 PURE STORAGE INC. PURE PROPRIETARY Full Pipeline 2,500+ VMs 350+ FBs 20+ Jenkins 1,000+ clients 72T 12 12 12 12 12 12 12 12 12 12 72T 12 12 12 12 12 12 12 12 12 12 12 12 12 12 120,000+ tests / day 24T rsyslog 16 16 16 16 16 16 800G 12 12 12 12 12 12 ü Duplicate bug ü Infrastructure failure ü Performance regression200T 12 12 12 12 12 12 90G 50G 12 12 12 12189T ü Low level details ü Easy to read graphs
- 30. 30 © 2018 PURE STORAGE INC. PURE PROPRIETARY Takeaways ü Index only what you need, store the rest (in a storage layer that scales in throughput and to billions of files/objects) ü Optimize for throughput and not latency ü Disaggregation of compute and storage for scalability of subsystems
- 31. 31 © 2018 PURE STORAGE INC. PURE PROPRIETARY QUESTIONS?