Avoiding the Pit of Despair - Event Sourcing with Akka and Cassandra
13 likes3,054 views

The document presents an overview of using Akka and Cassandra for event sourcing, highlighting the actor model's benefits for building distributed applications. It covers persistent actors, event journaling, and challenges such as unbounded partition growth in Cassandra, along with strategies to mitigate these issues. The discussion includes practical implementations for handling deletes and optimizing data storage using snapshots and partitions.







![Obligatory E-Commerce Example
8
ShoppingCartActor
mailbox
state
behavior
messages
sent asynchronously
send messages to other
Actors (could be replies)
Examples:
InitializeCart
AddItemToCart
RemoveItemFromCart
ChangeItemQuantity
ApplyDiscount
GetCartItems
{
cart_id: 1345,
user_id: 4762
created_on: "7/10/2015",
items: [
{
item_id: 7621,
quantity: 1,
unit_price: 19.99
},
{
item_id: 9134,
quantity: 2,
unit_price: 16.99
}
]
}
Examples:
CartItems
ItemAdded
GetDiscount
if (items.length > 5)
Become(Discounted)](https://image.slidesharecdn.com/avoidingthepitofdespair-eventsourcingwithakkaandcassandra-150716144634-lva1-app6892/85/Avoiding-the-Pit-of-Despair-Event-Sourcing-with-Akka-and-Cassandra-8-320.jpg)






![Speeding up Replays with Snapshots
12
Shopping Cart (id = 1345)
user_id= 4762
created_on= 7/10/2015…
Cart Created
item_id= 7621
quantity= 1
price= 19.99
Item Added
item_id= 9134
quantity= 2
price= 16.99
Item Added
{
event_id: 3,
cart_id: 1345,
user_id: 4762
created_on: "7/10/2015",
items: [
{
item_id: 7621,
quantity: 1,
price: 19.99
},
{
item_id: 9134,
quantity: 2,
price: 16.99
}
]
}
Take Snapshot](https://image.slidesharecdn.com/avoidingthepitofdespair-eventsourcingwithakkaandcassandra-150716144634-lva1-app6892/85/Avoiding-the-Pit-of-Despair-Event-Sourcing-with-Akka-and-Cassandra-15-320.jpg)
![Speeding up Replays with Snapshots
12
Shopping Cart (id = 1345)
user_id= 4762
created_on= 7/10/2015…
Cart Created
item_id= 7621
quantity= 1
price= 19.99
Item Added
item_id= 9134
quantity= 2
price= 16.99
Item Added
Item Removed item_id= 7621
Qty Changed
item_id= 9134
quantity= 1
{
event_id: 3,
cart_id: 1345,
user_id: 4762
created_on: "7/10/2015",
items: [
{
item_id: 7621,
quantity: 1,
price: 19.99
},
{
item_id: 9134,
quantity: 2,
price: 16.99
}
]
}](https://image.slidesharecdn.com/avoidingthepitofdespair-eventsourcingwithakkaandcassandra-150716144634-lva1-app6892/85/Avoiding-the-Pit-of-Despair-Event-Sourcing-with-Akka-and-Cassandra-16-320.jpg)
![Speeding up Replays with Snapshots
12
Shopping Cart (id = 1345)
user_id= 4762
created_on= 7/10/2015…
Cart Created
item_id= 7621
quantity= 1
price= 19.99
Item Added
item_id= 9134
quantity= 2
price= 16.99
Item Added
Item Removed item_id= 7621
Qty Changed
item_id= 9134
quantity= 1
{
event_id: 3,
cart_id: 1345,
user_id: 4762
created_on: "7/10/2015",
items: [
{
item_id: 7621,
quantity: 1,
price: 19.99
},
{
item_id: 9134,
quantity: 2,
price: 16.99
}
]
}
Load Snapshot](https://image.slidesharecdn.com/avoidingthepitofdespair-eventsourcingwithakkaandcassandra-150716144634-lva1-app6892/85/Avoiding-the-Pit-of-Despair-Event-Sourcing-with-Akka-and-Cassandra-17-320.jpg)


![The Async Journal API
20
Task ReplayMessagesAsync(
string persistenceId,
long fromSequenceNr,
long toSequenceNr,
long max,
Action<IPersistentRepr> replayCallback);
Task<long> ReadHighestSequenceNrAsync(
string persistenceId,
long fromSequenceNr);
Task WriteMessagesAsync(
IEnumerable<IPersistentRepr> messages);
Task DeleteMessagesToAsync(
string persistenceId,
long toSequenceNr,
bool isPermanent);
def asyncReplayMessages(
persistenceId: String,
fromSequenceNr: Long,
toSequenceNr: Long,
max: Long)
(replayCallback: PersistentRepr => Unit)
: Future[Unit]
def asyncReadHighestSequenceNr(
persistenceId: String,
fromSequenceNr: Long)
: Future[Long]
def asyncWriteMessages(
messages: immutable.Seq[PersistentRepr])
: Future[Unit]
def asyncDeleteMessagesTo(
persistenceId: String,
toSequenceNr: Long,
permanent: Boolean)
: Future[Unit]](https://image.slidesharecdn.com/avoidingthepitofdespair-eventsourcingwithakkaandcassandra-150716144634-lva1-app6892/85/Avoiding-the-Pit-of-Despair-Event-Sourcing-with-Akka-and-Cassandra-20-320.jpg)





























![Cassandra Data Modeling Anti-Pattern #2
Queue-like Data Sets
51
Journal persistence_id
'57ab...'
partition_nr
1
seq_nr=1
marker='A'
Tombstone
NO DATA HERE
...
Read all messages between 2 sequence numbers
SELECT * FROM messages
WHERE persistence_id = '57ab...'
AND partition_number = 1
AND sequence_number >= 1
AND sequence_number <= [max value];
seq_nr=2
marker='A'
Tombstone
NO DATA HERE
seq_nr=3
marker='A'
Tombstone
NO DATA HERE
seq_nr=4
marker='A'
Tombstone
NO DATA HERE](https://image.slidesharecdn.com/avoidingthepitofdespair-eventsourcingwithakkaandcassandra-150716144634-lva1-app6892/85/Avoiding-the-Pit-of-Despair-Event-Sourcing-with-Akka-and-Cassandra-51-320.jpg)








Avoiding the Pit of Despair - Event Sourcing with Akka and Cassandra
- 1. Avoiding the Pit of Despair: Event Sourcing with Akka and Cassandra Luke Tillman (@LukeTillman) Language Evangelist at DataStax
- 2. Promo Codes 50% off Priority Passes: LukeT50 25% off Training and Certification: LukeTCert
- 3. • Evangelist with a focus on Developers • Long-time Developer on RDBMS (lots of .NET) Who are you?! 3
- 4. 1 An Intro to Akka and Event Sourcing 2 An Event Journal in Cassandra 3 Accounting for Deletes 4 Lessons Learned 4
- 5. An Intro to Akka and Event Sourcing 5
- 6. Akka • An actor framework for building concurrent and distributed applications • Originally for the JVM (written in Scala, includes Java bindings) • Ported to .NET/CLR (written in C#, includes F# bindings) • Both open source, on GitHub 6 http://akka.io http://getakka.net
- 7. Actors in Akka • Lightweight, isolated processes • No shared state (so nothing to lock or synchronize) • Actors have a mailbox (message queue) • Process messages one at a time – Update state – Change behavior – Send messages to other Actors 7 Actor mailbox state behavior messages sent asynchronously send messages to other Actors (could be replies)
- 8. Obligatory E-Commerce Example 8 ShoppingCartActor mailbox state behavior messages sent asynchronously send messages to other Actors (could be replies) Examples: InitializeCart AddItemToCart RemoveItemFromCart ChangeItemQuantity ApplyDiscount GetCartItems { cart_id: 1345, user_id: 4762 created_on: "7/10/2015", items: [ { item_id: 7621, quantity: 1, unit_price: 19.99 }, { item_id: 9134, quantity: 2, unit_price: 16.99 } ] } Examples: CartItems ItemAdded GetDiscount if (items.length > 5) Become(Discounted)
- 9. Actors in Akka • Break a complex system down into lots of smaller pieces • Can easily scale to millions of actors on a single machine – 2.5 million per GB of heap • Since actors only communicate via async message passing, they can also be distributed across many machines – Location Transparency 9 Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor Actor send messages via network
- 10. Persistent Actors in Akka • Actor mailbox and state are transient by default in Akka – Crash/Restart, messages and state are lost 10 Actor mailbox state behavior
- 11. Persistent Actors in Akka • Actor mailbox and state are transient by default in Akka – Crash/Restart, messages and state are lost • We could just write code in the actor to persist the current state to storage 10 Actor mailbox state behavior
- 12. Persistent Actors in Akka • Actor mailbox and state are transient by default in Akka – Crash/Restart, messages and state are lost • We could just write code in the actor to persist the current state to storage • Akka Persistence plugin provides an API for persisting these to durable storage using Event Sourcing 10 PersistentActor mailbox state behavior persistenceId sequenceNr Persist(event) SaveSnapshot(payload)
- 13. Persistence with Event Sourcing • Instead of keeping the current state, keep a journal of all the deltas (events) • Append only (no UPDATE or DELETE) • We can replay our journal of events to get the current state 13 Shopping Cart (id = 1345) user_id= 4762 created_on= 7/10/2015… Cart Created item_id= 7621 quantity= 1 price= 19.99 Item Added item_id= 9134 quantity= 2 price= 16.99 Item Added Item Removed item_id= 7621 Qty Changed item_id= 9134 quantity= 1
- 14. Speeding up Replays with Snapshots 12 Shopping Cart (id = 1345) user_id= 4762 created_on= 7/10/2015… Cart Created item_id= 7621 quantity= 1 price= 19.99 Item Added item_id= 9134 quantity= 2 price= 16.99 Item Added
- 15. Speeding up Replays with Snapshots 12 Shopping Cart (id = 1345) user_id= 4762 created_on= 7/10/2015… Cart Created item_id= 7621 quantity= 1 price= 19.99 Item Added item_id= 9134 quantity= 2 price= 16.99 Item Added { event_id: 3, cart_id: 1345, user_id: 4762 created_on: "7/10/2015", items: [ { item_id: 7621, quantity: 1, price: 19.99 }, { item_id: 9134, quantity: 2, price: 16.99 } ] } Take Snapshot
- 16. Speeding up Replays with Snapshots 12 Shopping Cart (id = 1345) user_id= 4762 created_on= 7/10/2015… Cart Created item_id= 7621 quantity= 1 price= 19.99 Item Added item_id= 9134 quantity= 2 price= 16.99 Item Added Item Removed item_id= 7621 Qty Changed item_id= 9134 quantity= 1 { event_id: 3, cart_id: 1345, user_id: 4762 created_on: "7/10/2015", items: [ { item_id: 7621, quantity: 1, price: 19.99 }, { item_id: 9134, quantity: 2, price: 16.99 } ] }
- 17. Speeding up Replays with Snapshots 12 Shopping Cart (id = 1345) user_id= 4762 created_on= 7/10/2015… Cart Created item_id= 7621 quantity= 1 price= 19.99 Item Added item_id= 9134 quantity= 2 price= 16.99 Item Added Item Removed item_id= 7621 Qty Changed item_id= 9134 quantity= 1 { event_id: 3, cart_id: 1345, user_id: 4762 created_on: "7/10/2015", items: [ { item_id: 7621, quantity: 1, price: 19.99 }, { item_id: 9134, quantity: 2, price: 16.99 } ] } Load Snapshot
- 18. Event Sourcing in Practice • Typically two kinds of storage: – Event Journal Store – Snapshot Store • A history of how we got to the current state can be useful • We've also got a lot more data to store than we did before 18 Shopping Cart (id = 1345) user_id= 4762 created_on= 7/10/2015… Cart Created item_id= 7621 quantity= 1 price= 19.99 Item Added item_id= 9134 quantity= 2 price= 16.99 Item Added Item Removed item_id= 7621 Qty Changed item_id= 9134 quantity= 1
- 19. Why Cassandra? • Lots of Persistence implementations available – Akka: Cassandra, JDBC, Kafka, MongoDB, etc. – Akka.NET: Cassandra, MS SQL, Postgres • Cassandra is really easy to scale out as you need to store more events for more actors • Workload and Data Shape are great fits for C* – Transactional, Write-Heavy workload – Sequentially written, immutable events (looks a lot like time series data) 19
- 20. The Async Journal API 20 Task ReplayMessagesAsync( string persistenceId, long fromSequenceNr, long toSequenceNr, long max, Action<IPersistentRepr> replayCallback); Task<long> ReadHighestSequenceNrAsync( string persistenceId, long fromSequenceNr); Task WriteMessagesAsync( IEnumerable<IPersistentRepr> messages); Task DeleteMessagesToAsync( string persistenceId, long toSequenceNr, bool isPermanent); def asyncReplayMessages( persistenceId: String, fromSequenceNr: Long, toSequenceNr: Long, max: Long) (replayCallback: PersistentRepr => Unit) : Future[Unit] def asyncReadHighestSequenceNr( persistenceId: String, fromSequenceNr: Long) : Future[Long] def asyncWriteMessages( messages: immutable.Seq[PersistentRepr]) : Future[Unit] def asyncDeleteMessagesTo( persistenceId: String, toSequenceNr: Long, permanent: Boolean) : Future[Unit]
- 21. The Journal API Summary • Write Method – For a given actor, write a group of messages • Delete Method – For a given actor, permanently or logically delete all messages up to a given sequence number • Read Methods – For a given actor, read back all the messages between two sequence numbers – For a given actor, read the highest sequence number that's been written 21
- 22. An Event Journal in Cassandra Data Modeling for Reads and Writes 22
- 23. A Simple First Attempt • Use persistence_id as partition key – all messages for a given persistence Id together • Use sequence_number as clustering column – order messages by sequence number inside a partition • Read all messages between two sequence numbers • Read the highest sequence number 23 CREATE TABLE messages ( persistence_id text, sequence_number bigint, message blob, PRIMARY KEY ( persistence_id, sequence_number) ); SELECT * FROM messages WHERE persistence_id = ? AND sequence_number >= ? AND sequence_number <= ?; SELECT sequence_number FROM messages WHERE persistence_id = ? ORDER BY sequence_number DESC LIMIT 1;
- 24. A Simple First Attempt • Write a group of messages • Use a Cassandra Batch statement to ensure all messages (success) or no messages (failure) get written • What's the problem with this data model (ignoring implementing deletes for now)? 24 CREATE TABLE messages ( persistence_id text, sequence_number bigint, message blob, PRIMARY KEY ( persistence_id, sequence_number) ); BEGIN BATCH INSERT INTO messages ... ; INSERT INTO messages ... ; INSERT INTO messages ... ; APPLY BATCH;
- 26. Cassandra Data Modeling Anti-Pattern #1 Unbounded Partition Growth • Cassandra has a hard limit of 2 billion cells in a partition • But there's also a practical limit – Depends on row/cell data size, but likely not more than millions of rows 26 Journal INSERT INTO messages ... persistence_id= '57ab...' seq_nr= 1 seq_nr= 2 message= 0x00... message= 0x00... ∞?
- 27. Fixing the Unbounded Partition Growth Problem • General strategy: add a column to the partition key – Compound partition key • Can be data that's already part of the model, or a "synthetic" column • Allow users to configure a partition size in the plugin – Partition Size = number of rows per partition – This should not be changeable once messages have been written • Partition number for a given sequence number is then easy to calculate – (seqNr – 1) / partitionSize (100 – 1) / 100 = partition 0 (101 – 1) / 100 = partition 1 27 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, message blob, PRIMARY KEY ( (persistence_id, partition_number), sequence_number) );
- 28. Fixing the Unbounded Partition Growth Problem • Read all messages between two sequence numbers • Read the highest sequence number 28 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, message blob, PRIMARY KEY ( (persistence_id, partition_number), sequence_number) ); SELECT * FROM messages WHERE persistence_id = ? AND partition_number = ? AND sequence_number >= ? AND sequence_number <= ?; SELECT sequence_number FROM messages WHERE persistence_id = ? AND partition_number = ? ORDER BY sequence_number DESC LIMIT 1; (repeat until we reach sequence number or run out of partitions) (repeat until we run out of partitions)
- 29. Fixing the Unbounded Partition Growth Problem • Write a group of messages • A Cassandra Batch statement might now write to multiple partitions (if the sequence numbers cross a partition boundary) • Is that a problem? 29 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, message blob, PRIMARY KEY ( (persistence_id, partition_number), sequence_number) ); BEGIN BATCH INSERT INTO messages ... ; INSERT INTO messages ... ; INSERT INTO messages ... ; APPLY BATCH;
- 30. RTFM: Cassandra Batches Edition 30 "Batches are atomic by default. In the context of a Cassandra batch operation, atomic means that if any of the batch succeeds, all of it will." - DataStax CQL Docs http://docs.datastax.com/en/cql/3.1/cql/cql_reference/batch_r.html "Although an atomic batch guarantees that if any part of the batch succeeds, all of it will, no other transactional enforcement is done at the batch level. For example, there is no batch isolation. Clients are able to read the first updated rows from the batch, while other rows are still being updated on the server." - DataStax CQL Docs http://docs.datastax.com/en/cql/3.1/cql/cql_reference/batch_r.html Atomic? That's kind of a loaded word.
- 31. Multiple Partition Batch Failure Scenario 29 Journal BEGIN BATCH ... APPLY BATCH; CL = QUORUM RF = 3
- 32. Multiple Partition Batch Failure Scenario 29 Journal BEGIN BATCH ... APPLY BATCH; Batch Log Batch Log Batch Log CL = QUORUM RF = 3
- 33. Multiple Partition Batch Failure Scenario • Once written to the Batch Log successfully, we know all the writes in the batch will succeed eventually (atomic?) 29 Journal BEGIN BATCH ... APPLY BATCH; CL = QUORUM RF = 3
- 34. Multiple Partition Batch Failure Scenario • Once written to the Batch Log successfully, we know all the writes in the batch will succeed eventually (atomic?) 29 Journal BEGIN BATCH ... APPLY BATCH; CL = QUORUM RF = 3
- 35. Multiple Partition Batch Failure Scenario • Once written to the Batch Log successfully, we know all the writes in the batch will succeed eventually (atomic?) • Batch has been partially applied 29 Journal BEGIN BATCH ... APPLY BATCH; CL = QUORUM RF = 3
- 36. Multiple Partition Batch Failure Scenario • Once written to the Batch Log successfully, we know all the writes in the batch will succeed eventually (atomic?) • Batch has been partially applied • Possible to read a partially applied batch since there is no batch isolation 29 Journal BEGIN BATCH ... APPLY BATCH; CL = QUORUM RF = 3 WriteTimeout - writeType = BATCH
- 37. Reading Partially Applied Batches 37
- 38. RTFM: Cassandra Batches Edition Part 2 38 "For example, there is no batch isolation. Clients are able to read the first updated rows from the batch, while other rows are still being updated on the server. However, transactional row updates within a partition key are isolated: clients cannot read a partial update." - DataStax CQL Docs http://docs.datastax.com/en/cql/3.1/cql/cql_reference/batch_r.html What we really need is Isolation. When writing a group of messages, ensure that we write the group to a single partition.
- 39. Logic Changes to Ensure Batch Isolation • Still use configurable Partition Size – not a "hard limit" but a "best attempt" • On write, see if messages will all fit in the current partition • If not, roll over to the next partition early • Reading is slightly more complicated – For a given sequence number it might be in partition n or (n+1) 39 seq_nr = 97 seq_nr = 98 seq_nr = 1 99 100 101 partition_nr = 1 partition_nr = 2 PartitionSize=100
- 41. Implementing Logical Deletes, Option 1 • Add an is_deleted column to our messages table • Read all messages between two sequence numbers 41 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, message blob, is_deleted bool, PRIMARY KEY ( (persistence_id, partition_number), sequence_number) ); SELECT * FROM messages WHERE persistence_id = ? AND partition_number = ? AND sequence_number >= ? AND sequence_number <= ?; (repeat until we reach sequence number or run out of partitions) ... sequence_number message is_deleted ... 1 0x00 true ... 2 0x00 true ... 3 0x00 false ... 4 0x00 false
- 42. Implementing Logical Deletes, Option 1 • Pros: – On replay, easy to check if a message has been deleted (comes included in message query's data) • Cons: – Messages not immutable any more – Issue lots of UPDATEs to mark each message as deleted – Have to scan through a lot of rows to find max deleted sequence number if we want to avoid issuing unnecessary UPDATEs 42 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, message blob, is_deleted bool, PRIMARY KEY ( (persistence_id, partition_number), sequence_number) );
- 43. Implementing Logical Deletes, Option 2 • Add a marker column and make it a clustering column – Messages written with 'A' – Deletes get written with 'D' • Read all messages between two sequence numbers 43 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, marker text, message blob, PRIMARY KEY ( (persistence_id, partition_number), sequence_number, marker) ); SELECT * FROM messages WHERE persistence_id = ? AND partition_number = ? AND sequence_number >= ? AND sequence_number <= ?; (repeat until we reach sequence number or run out of partitions) ... sequence_number marker message ... 1 A 0x00 ... 1 D null ... 2 A 0x00 ... 3 A 0x00
- 44. Implementing Logical Deletes, Option 2 • Pros – On replay, easy to peek at next row to check if deleted (comes included in message query's data) – Message data stays immutable • Cons – Issue lots of INSERTs to mark each message as deleted – Have to scan through a lot of rows to find max deleted sequence number if we want to avoid issuing unnecessary INSERTs – Potentially twice as many rows to store 44 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, marker text, message blob, PRIMARY KEY ( (persistence_id, partition_number), sequence_number, marker) );
- 45. Looking at Physical Deletes • Physically delete messages to a given sequence number • Still probably want to scan through rows to see what's already been deleted first 45 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, marker text, message blob, PRIMARY KEY ( (persistence_id, partition_number), sequence_number, marker) ); BEGIN BATCH DELETE FROM messages WHERE persistence_id = ? AND partition_number = ? AND marker = 'A' AND sequence_number = ?; ... APPLY BATCH; • Can't range delete, so we have to do lots of individual DELETEs
- 46. Looking at Physical Deletes • Read all messages between two sequence numbers • With how DELETEs work in Cassandra, is there a potential problem with this query? 46 CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, marker text, message blob, PRIMARY KEY ( (persistence_id, partition_number), sequence_number, marker) ); SELECT * FROM messages WHERE persistence_id = ? AND partition_number = ? AND sequence_number >= ? AND sequence_number <= ?; (repeat until we reach sequence number or run out of partitions)
- 47. Tombstone Hell: Queue-like Data Sets 47
- 48. Cassandra Data Modeling Anti-Pattern #2 Queue-like Data Sets 46 Journal persistence_id '57ab...' partition_nr 1 message= 0x00... seq_nr=1 marker='A' ... Delete messages to a sequence number BEGIN BATCH DELETE FROM messages WHERE persistence_id = '57ab...' AND partition_nr = 1 AND marker = 'A' AND sequence_nr = 1; ... APPLY BATCH; message= 0x00... seq_nr=2 marker='A'
- 49. Cassandra Data Modeling Anti-Pattern #2 Queue-like Data Sets 46 Journal persistence_id '57ab...' partition_nr 1 message= 0x00... seq_nr=1 marker='A' seq_nr=1 marker='A' Tombstone NO DATA HERE ... Delete messages to a sequence number BEGIN BATCH DELETE FROM messages WHERE persistence_id = '57ab...' AND partition_nr = 1 AND marker = 'A' AND sequence_nr = 1; ... APPLY BATCH; message= 0x00... seq_nr=2 marker='A' seq_nr=2 marker='A' Tombstone NO DATA HERE
- 50. Cassandra Data Modeling Anti-Pattern #2 Queue-like Data Sets • At some point compaction runs and we don't have two versions any more, but tombstones don't go away immediately – Tombstones remain for gc_grace_seconds – Default is 10 days 46 Journal persistence_id '57ab...' partition_nr 1 seq_nr=1 marker='A' Tombstone NO DATA HERE ... seq_nr=2 marker='A' Tombstone NO DATA HERE
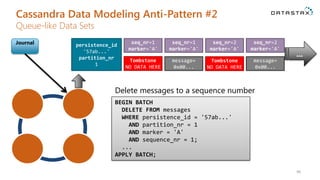
- 51. Cassandra Data Modeling Anti-Pattern #2 Queue-like Data Sets 51 Journal persistence_id '57ab...' partition_nr 1 seq_nr=1 marker='A' Tombstone NO DATA HERE ... Read all messages between 2 sequence numbers SELECT * FROM messages WHERE persistence_id = '57ab...' AND partition_number = 1 AND sequence_number >= 1 AND sequence_number <= [max value]; seq_nr=2 marker='A' Tombstone NO DATA HERE seq_nr=3 marker='A' Tombstone NO DATA HERE seq_nr=4 marker='A' Tombstone NO DATA HERE
- 52. Avoid Tombstone Hell 52 We need a way to avoid reading tombstones when replaying messages. SELECT * FROM messages WHERE persistence_id = ? AND partition_number = ? AND sequence_number >= ? AND sequence_number <= ?; AND sequence_number >= ? If we know what sequence number we've already deleted to before we query, we could make that lower bound smarter.
- 53. A Third Option for Deletes • Use marker as a clustering column, but change the clustering order – Messages still 'A', Deletes 'D' • Read all messages between two sequence numbers 53 CREATE TABLE messages ( persistence_id text, partition_number bigint, marker text, sequence_number bigint, message blob, PRIMARY KEY ( (persistence_id, partition_number), marker, sequence_number) ); SELECT * FROM messages WHERE persistence_id = ? AND partition_number = ? AND marker = 'A' AND sequence_number >= ? AND sequence_number <= ?; (repeat until we reach sequence number or run out of partitions) ... sequence_number marker message ... 1 A 0x00 ... 2 A 0x00 ... 3 A 0x00
- 54. A Third Option for Deletes • Messages data no longer has deleted information, so how do we know what's already been deleted? • Get max deleted sequence number • Can avoid tombstones if done before getting message data 54 CREATE TABLE messages ( persistence_id text, partition_number bigint, marker text, sequence_number bigint, message blob, PRIMARY KEY ( (persistence_id, partition_number), marker, sequence_number) ); SELECT sequence_number FROM messages WHERE persistence_id = ? AND partition_number = ? AND marker = 'D' ORDER BY marker DESC, sequence_number DESC LIMIT 1;
- 55. A Third Option for Deletes • Pros – Message data stays immutable – Issue a single INSERT when deleting to a sequence number – Read a single row to find out what's been deleted (no more scanning) – Can avoid reading tombstones created by physical deletes • Cons – Requires a separate query to find out what's been deleted before getting message data 55 CREATE TABLE messages ( persistence_id text, partition_number bigint, marker text, sequence_number bigint, message blob, PRIMARY KEY ( (persistence_id, partition_number), marker, sequence_number) );
- 56. Final Schema in Akka and Akka.NET 56 CREATE TABLE messages ( persistence_id text, partition_number bigint, marker text, sequence_number bigint, message blob, PRIMARY KEY ( (persistence_id, partition_number), marker, sequence_number) ); CREATE TABLE messages ( persistence_id text, partition_number bigint, sequence_number bigint, marker text, message blob, PRIMARY KEY ( (persistence_id, partition_number), sequence_number, marker) ); https://github.com/krasserm/akka-persistence-cassandra https://github.com/akkadotnet/Akka.Persistence.Cassandra
- 58. Summary • Seemingly simple data models can get a lot more complicated • Avoid unbounded partition growth – Add data to your partition key • Be aware of how Cassandra Logged Batches work – If you need isolation, only write to a single partition • Avoid queue-like data sets and be aware of how tombstones might impact your queries – Try to query with ranges that avoid tombstones 58
- 59. Promo Codes 50% off Priority Passes: LukeT50 25% off Training and Certification: LukeTCert