

















![Methodology - Train&Inference
1 9
Training Batch Normalization Network Find E[x], Var[x] and inference](https://image.slidesharecdn.com/batchnormalization-240318060431-7a70035a/85/Batch-normalization-Accelerating-Deep-Network-Training-by-Reducing-Internal-Covariate-Shift-19-320.jpg)
![Methodology - Train&Inference
2 0
Training Batch Normalization Network Find E[x], Var[x] and inference](https://image.slidesharecdn.com/batchnormalization-240318060431-7a70035a/85/Batch-normalization-Accelerating-Deep-Network-Training-by-Reducing-Internal-Covariate-Shift-20-320.jpg)
![Methodology - Train&Inference
2 1
Training Batch Normalization Network Find E[x], Var[x] and inference](https://image.slidesharecdn.com/batchnormalization-240318060431-7a70035a/85/Batch-normalization-Accelerating-Deep-Network-Training-by-Reducing-Internal-Covariate-Shift-21-320.jpg)
![Methodology - Train&Inference
2 2
Training Batch Normalization Network Find E[x], Var[x] and inference](https://image.slidesharecdn.com/batchnormalization-240318060431-7a70035a/85/Batch-normalization-Accelerating-Deep-Network-Training-by-Reducing-Internal-Covariate-Shift-22-320.jpg)




























Batch normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- 1. Batch normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift H O K U N L I N 2 0 2 3 / 8 / 3 1
- 3. Introduction Sergey Ioffe, Christian Szegedy from Google Reserch, 2015 ICML It's hard to train deep neural networks 3 SGD is simple but require careful tunning The inputs to each layer are affected by all preceding layers Needs to continuously adapt to new distribution
- 5. Introduction 5 Gradient vanishing slow down the convergence. Changing distribution of input will likely move x into saturated regime
- 6. Introduction Use Batch Normalization fix means and variances of layer inputs Reduce the dependence of initial values of SGD Reduce the need for Dropout 6 Match SOTA model on ImageNet using only 7% of training steps
- 8. Related Works Normalizing the Inputs Covariate shift Input distribution to a system changes 8 Internal Covatiate Shift Input distribution to a network changes due to training
- 10. Methodology Fix the distribution of the layer inputs 1 0 Normalize each scalar feature independently Since fill whitening is costly Normalization via mini-batch Since we often use mini-batch in SGD
- 11. Methodology - BN Transform 1 1 Consider a mini-batch with size m,
- 12. Methodology - BN Transform 1 2 Consider a mini-batch with size m,
- 13. Methodology - BN Transform 1 3 Consider a mini-batch with size m, Add learnable parameters gamma and beta
- 16. Methodology - Train&Inference 1 6 Output depends on data in mini-batch!
- 17. Methodology - Train&Inference 1 7 Training Inferencing
- 18. Methodology - Train&Inference 1 8 Training Inferencing
- 19. Methodology - Train&Inference 1 9 Training Batch Normalization Network Find E[x], Var[x] and inference
- 20. Methodology - Train&Inference 2 0 Training Batch Normalization Network Find E[x], Var[x] and inference
- 21. Methodology - Train&Inference 2 1 Training Batch Normalization Network Find E[x], Var[x] and inference
- 22. Methodology - Train&Inference 2 2 Training Batch Normalization Network Find E[x], Var[x] and inference
- 23. Methodology - CNN Put BN before nonlinearities Also include learnable gamma and beta 2 3 reset mini-batch size to m times spatial size to obtain convolution properties
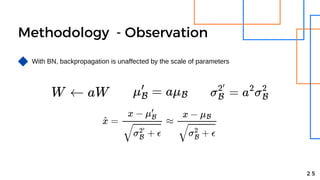
- 24. Methodology - Observation With BN, backpropagation is unaffected by the scale of parameters 2 4
- 25. Methodology - Observation With BN, backpropagation is unaffected by the scale of parameters 2 5
- 26. Methodology - Observation With BN, backpropagation is unaffected by the scale of parameters 2 6
- 27. Methodology - Observation With BN, backpropagation is unaffected by the scale of parameters 2 7 BN will stablize the parameter growth
- 28. Methodology - observation With BN, backpropagation is unaffected by the scale of parameters 2 8 BN will stablize the parameter growth BN enables higher learning rates
- 30. MNIST dataset Handwritten digits dataset 28 x 28 pixel monochrome images 60K training images 3 0 10K testing images 10 labels Verify internal covariate shift here
- 31. MNIST dataset - NN Setup 28 x 28 binary image input 3 FC hidden layers with 100 sigmoid nonlinearities each 1 FC hidden layer with 10 activations with cross-entropy loss 3 1 Train for 50K steps, 60 examples per mini-batch BN add in each hidden layers W initialized to small random Gaussian values
- 32. MNIST dataset - Result x represent epoch y represent test accuracy 3 2 NN with BN has higher test accuracy
- 33. MNIST dataset - Result x represent epoch y represent output value 3 3 Lines represent {15, 50, 85}th percentiles Distribution in NN without BN is unstable Distribution in NN with BN is stable
- 34. ImageNet Train with ILSVRC 2012 dataset 1000 labels 150K test and validation images 3 4 1.2M train images
- 35. ImageNet - Inception Model 3 5 GoogLeNet is one of the instance of Inception Won 2014 ImageNet SOTA model as baseline
- 36. ImageNet - Inception Setup 3 6
- 37. ImageNet - Inception Setup 3 7
- 38. ImageNet - Inception Setup 3 8 5x5 conv. layers to two 3x3 conv. layers
- 39. ImageNet - Inception Setup 3 9 28x28 inception modules from 2 to 3
- 40. ImageNet - Inception Setup 4 0 Use average, max-pooling during training
- 41. ImageNet - Inception Setup 4 1 Remove board pooling layers between any two incepetion modules
- 42. ImageNet - Inception Setup 4 2 Add stride-2 conv./pooling layers before filter in 3c, 4e
- 43. ImageNet - BN Setup 4 3 Increase learning rate Remove Dropout Reduce the L2 Regularization by a factor of 5 Lower learning rate 6 times faster Remove Local Response Normalization Shuffle training examples more thoroughly Reduce the photometric distortions
- 44. ImageNet - BN Setup 4 4 BN-Baseline Inception + BN before each nonlinearity
- 45. ImageNet - BN Setup 4 5 BN-Baseline Inception + BN before each nonlinearity BN-x5 / BN-x30 BN-Baseline with learning rate increase by a factor of 5 / 30 (0.0075, 0.045)
- 46. ImageNet - BN Setup 4 6 BN-Baseline Inception + BN before each nonlinearity BN-x5 / BN-x30 BN-Baseline with learning rate increase by a factor of 5 / 30 (0.0075, 0.045) BN-x30-Sigmoid BN-x30 with Sigmoid instead of ReLU
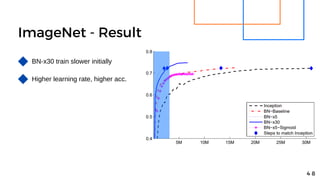
- 47. ImageNet - Result 4 7 x represent epoch y represent validation accuracy Same acc. in fewer steps with BN Inception+Sigmoid has acc. < 1/1000
- 48. ImageNet - Result 4 8 BN-x30 train slower initially Higher learning rate, higher acc.
- 49. ImageNet - Result 4 9 BN reach 72.2% less than half steps BN-x5 only needs 14 times fewer steps Same acc. in fewer steps with BN Inception+Sigmoid has acc. < 1/1000 Doesn't need Dropout and Local Response Normalization
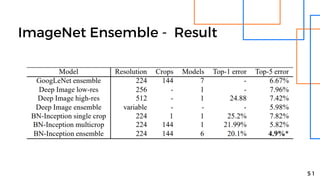
- 50. ImageNet Ensemble - Setup 5 0 6 BN-x30 form BN-Inception ensemble Increase initial weights in conv. layers Using Dropout with probability 5% or 10% Using non-convolutional, per-activation BN in last hidden layer Predict base on on the arithmetic average
- 51. ImageNet Ensemble - Result 5 1
- 53. Conclusion Reduce internal covariate shift speed up training Add BN to SOTA model yields a substantial speedup in training Preserve model expressivity 5 3 Allows higher learning rate Reduce the need for dropout and careful parameter initialization Beat SOTA model in ImageNet classfication
- 54. THANK YOU 5 4