Be A Hero: Transforming GoPro Analytics Data Pipeline
Download as PPTX, PDF5 likes755 views

The document discusses GoPro's transition to a new data platform architecture. The old architecture had several clusters for different workloads which caused operational overhead and lack of elasticity. The new architecture separates storage and computing, uses S3 for storage and ephemeral instances as compute clusters. It also introduces a centralized Hive metastore and uses dynamic DDL to flexibly ingest and aggregate both batch and streaming data while allowing the schema to change on the fly. This improves cost, scalability and enables more advanced analytics capabilities.























![DYNAMIC DDL – CREATE TABLE
// manually create table due to Spark bug
def createTable(sqlContext: SQLContext, columns: Seq[(String, String)],
destInfo: OutputInfo, partitionColumns: Array[(ColumnDef, Column)]): DataFrame = {
val partitionClause = if (partitionColumns.length == 0) "" else {
s"""PARTITIONED BY (${partitionColumns.map(f => s"${f._1.name} ${f._1.`type`}").mkString(", ")})"""
}
val sqlStmt =
s"""CREATE TABLE IF NOT EXISTS ${destInfo.tableName()} ( columns.map(f => s"${f._1} ${f._2}").mkString(", "))
$partitionClause
STORED AS ${destInfo.destFormat.split('.').last}
""".stripMargin
//spark 2.x doesn't know create if not exists syntax,
// still log AlreadyExistsException message. but no exception
sqlContext.sql(sqlStmt)
}](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-25-320.jpg)
![DYNAMIC DDL – ALTER TABLE ADD COLUMNS
//first find existing fields, then add new fields
val tableDf = sqlContext.table(dbTableName)
val exisingFields : Seq[StructField] = …
val newFields: Seq[StructField] = …
if (newFields.nonEmpty) {
// spark 2.x bug https://issues.apache.org/jira/browse/SPARK-19261
val sqlStmt: String = s"""ALTER TABLE $dbTableName ADD COLUMNS ( ${newFields.map ( f =>
s"${f.name} ${f.dataType.typeName}” ).mkString(", ")}. )"""
}](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-26-320.jpg)
![DYNAMIC DDL – ALTER TABLE ADD COLUMNS (SPARK 2.0)
//Hack for Spark 2.0, Spark 2.1
if (newFields.nonEmpty) {
// spark 2.x bug https://issues.apache.org/jira/browse/SPARK-19261
alterTable(sqlContext, dbTableName, newFields)
}
def alterTable(sqlContext: SQLContext,
tableName: String,
newColumns: Seq[StructField]): Unit = {
alterTable(sqlContext, getTableIdentifier(tableName), newColumns)
}
private[spark] class HiveExternalCatalog(conf: SparkConf, hadoopConf: Configuration)
extends ExternalCatalog with Logging {
….
}](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-27-320.jpg)


![DYNAMIC DDL – BATCH SPECIFIC ISSUES
• Solution:
• Find DataFrame with max number of columns, use it as base, and reorder
columns against this DataFrame
val newDfs : Option[ParSeq[DataFrame]] = maxLengthDF.map{ baseDf =>
dfs.map { df =>
df.select(baseDf.schema.fieldNames.map(f => if (df.columns.contains(f)) col(f) else
lit(null).as(f)): _*)
}
}](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-30-320.jpg)
![DYNAMIC DDL – BATCH SPECIFIC ISSUES
• Issue2 : Too many log files -- performance
• Solution: We consolidate several data log files Data Frame into chunks, each
chunk with all Data Frames union together.
val ys: Seq[Seq[DataFrame]] = destTableDFs.seq.grouped(mergeChunkSize).toSeq
val dfs: ParSeq[DataFrame] = ys.par.map(p => p.foldLeft(emptyDF) { (z, a) => z.unionAll(a) })
dfs.foreach(saveDataFrame(info, _))](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-31-320.jpg)



Be A Hero: Transforming GoPro Analytics Data Pipeline
- 1. Be A Hero: Transforming GoPro Analytics Data Pipeline Machine Learning Innovation Summit , 2017 Chester Chen
- 2. ABOUT SPEAKER • Head of Data Science & Engineering • Prev. Director of Engineering, Alpine Data Labs • Start to play with Spark since Spark 0.6 version. • Spoke at Hadoop Summit, Big Data Scala, IEEE Big Data Conferences • Organizer of SF Big Analytics meetup (6800+ members)
- 3. AGENDA • Business Use Cases • Data Platform Architecture • Old Data Platforms: Pro & Cons and Challenges • New Data Platform Architeture and Initiatives • Adding Data Schema During Ingestion (Dynamic DDL)
- 5. GROWING DATA NEEDS FROM GOPRO ECOSYSTEM
- 6. GROWING DATA NEEDS FROM GOPRO ECOSYSTEM DATA Analytics Platform Consumer Devices GoPro Apps E-Commerce Social Media/OTT 3rd party data Product Insight CRM/Marketing/ Personalization User segmentation
- 9. OLD DATA PLATFORM ARCHITECTURE ETL Cluster •File dumps (Json, CSV) • Spark Jobs •Hive Secure Data Mart •End User Query •Impala / Sentry •Parquet Analytics Apps •HUE •Tableau Real Time Cluster • Log file streaming • Kafka • Spark • HBase Induction Framework • Batch Ingestion • Pre-processing • Scheduled download Rest API, FTP S3 sync Streaming ingestion Batch Ingestion
- 10. STREAMING PIPELINE Streaming Cluster ELBHTTP Pipeline for processing of streaming logs To Batch ETL Cluster
- 12. OLD BATCH DATA PIPELINE ETL Cluster HDFS HIVE Metastore To SDM Cluster From Streaming Pipeline Pull distcp Hard-code Hive SQL based predefined schema to load Json transform parquet and load to Hive Map-Reduce Jobs tend to fail Map-Reduce Jobs tend to fail HDFS HIVE Metastore distcp Aggregation Hard-coded SQL
- 13. OLD ANALYTICS CLUSTER HDFS HIVE Metastore BI Reporting SDM From Batch Cluster Exploratory Analytics with Hue: Impala/Hive: SQL Kerberos distcp 3rd Party Service
- 14. PROS AND CONS OF OLD ARCHITECTURE • Isolation of workloads • Fast ingest • Loosely coupled clusters • Secure analytics cluster • Multiple copies of data • Tightly coupled storage and compute • Lack of elasticity • Operational overhead of multiple clusters • Hard-coded batch Hive SQL not flexible to change • Multiple Hive meta stores • distcp across clusters can take a long time with increase of data volume PROS CONS
- 15. PROS AND CONS OF OLD ARCHITECTURE • Not easy to scale • Storage and compute cost • Only have SQL interface, no predictive analytics tool • Not easy to adapt data schema changes CONS
- 17. KEY INITIATIVES: INFRASTRUCTURE • Separate Compute and Storage • Move storage to S3 • Centralize Hive Metadata • Use ephemeral instance as compute cluster • Simplify the ETL ingestion process and eliminate the distcp • Elasticity • auto-scale compute cluster (expand & shrink based on demand) • Enhance Analytics Capabilities • introducing Notebook • Scala, Python, R etc. • AWS Cost Reduction • Reduce EBS storage cost • Dynamic DDL • add schema on the fly
- 18. DATA PLATFORM ARCHITECTURE Real Time Cluster •Log file streaming •Kafka •Spark Batch Ingestion Framework •Batch Ingestion •Pre-processing Streaming ingestion Batch Ingestion S3 CLUSTERS HIVE METASTORE PLOT.LY SERVER TABLEAU SERVER EXTERNAL SERFVICE Notebook Rest API, FTP S3 sync,etc Parquet + DDL State Sync OLAP Aggregation
- 19. NEW DYNAMIC DDL ARCHITECTURE Streaming Pipeline ELBHTTP Pipeline for processing of streaming logs S3 HIVE METASTORE transition Centralized Hive Meta Store
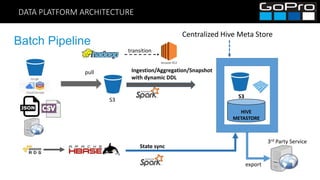
- 20. DATA PLATFORM ARCHITECTURE Batch Pipeline pull S3 3rd Party Service export Centralized Hive Meta Store S3 HIVE METASTORE Ingestion/Aggregation/Snapshot with dynamic DDL State sync transition
- 21. ANALYTICS ARCHITECTURE – IN PROGRESS BI Reporting/Visualization Exploratory/Predictive Analytics Spark SQL/Scala/python/R Hive Metastore DSE SELF- SERVICE PORTAL OLAP Aggregation
- 22. Dynamic DDL: Adding Schema to Data on the fly
- 23. WHAT IS DYNAMIC DDL? • Dynamically alter table and add column { { “userId”, “123”} {“eventId”, “abc”} } Flattened Columns record_userId, record_eventN Updated Table X A B C userId erventId a b c 123 abc A B C a b c Existing Table X
- 24. WHY USE DYNAMIC DDL? • Reduce development time • Traditionally, adding new Event/Attribute/Column requires of a lot time among teams • Many Hive ETL SQL needs to be changed to every column changes. • One way to solve this problem is to use key-value pair table • Ingestion is easy, no changes needed for newly added event/attribute/column • Hard for Analytics, tabulated data are much easier to work with • Dynamical DDL • Automatically flatten attributes (for json data) • Turn data into columns
- 25. DYNAMIC DDL – CREATE TABLE // manually create table due to Spark bug def createTable(sqlContext: SQLContext, columns: Seq[(String, String)], destInfo: OutputInfo, partitionColumns: Array[(ColumnDef, Column)]): DataFrame = { val partitionClause = if (partitionColumns.length == 0) "" else { s"""PARTITIONED BY (${partitionColumns.map(f => s"${f._1.name} ${f._1.`type`}").mkString(", ")})""" } val sqlStmt = s"""CREATE TABLE IF NOT EXISTS ${destInfo.tableName()} ( columns.map(f => s"${f._1} ${f._2}").mkString(", ")) $partitionClause STORED AS ${destInfo.destFormat.split('.').last} """.stripMargin //spark 2.x doesn't know create if not exists syntax, // still log AlreadyExistsException message. but no exception sqlContext.sql(sqlStmt) }
- 26. DYNAMIC DDL – ALTER TABLE ADD COLUMNS //first find existing fields, then add new fields val tableDf = sqlContext.table(dbTableName) val exisingFields : Seq[StructField] = … val newFields: Seq[StructField] = … if (newFields.nonEmpty) { // spark 2.x bug https://issues.apache.org/jira/browse/SPARK-19261 val sqlStmt: String = s"""ALTER TABLE $dbTableName ADD COLUMNS ( ${newFields.map ( f => s"${f.name} ${f.dataType.typeName}” ).mkString(", ")}. )""" }
- 27. DYNAMIC DDL – ALTER TABLE ADD COLUMNS (SPARK 2.0) //Hack for Spark 2.0, Spark 2.1 if (newFields.nonEmpty) { // spark 2.x bug https://issues.apache.org/jira/browse/SPARK-19261 alterTable(sqlContext, dbTableName, newFields) } def alterTable(sqlContext: SQLContext, tableName: String, newColumns: Seq[StructField]): Unit = { alterTable(sqlContext, getTableIdentifier(tableName), newColumns) } private[spark] class HiveExternalCatalog(conf: SparkConf, hadoopConf: Configuration) extends ExternalCatalog with Logging { …. }
- 28. DYNAMIC DDL – PREPARE DATAFRAME // Reorder the columns in the incoming data frame to match the order in the destination table. Project all columns from the table modifiedDF = modifiedDF.select(tableDf.schema.fieldNames.map( f => { if (modifiedDF.columns.contains(f)) col(f) else lit(null).as(f) }): _*) // Coalesce the data frame into the desired number of partitions (files). // avoid too many partitions modifiedDF.coalesce(ioInfo.outputInfo.numberOfPartition)
- 29. DYNAMIC DDL – BATCH SPECIFIC ISSUES • Issue 1 : Several log files are mapped into same table, and not all columns are present CSV file 1 A B A B C CSV file 2 A X Y Destination Table Table Writer B C
- 30. DYNAMIC DDL – BATCH SPECIFIC ISSUES • Solution: • Find DataFrame with max number of columns, use it as base, and reorder columns against this DataFrame val newDfs : Option[ParSeq[DataFrame]] = maxLengthDF.map{ baseDf => dfs.map { df => df.select(baseDf.schema.fieldNames.map(f => if (df.columns.contains(f)) col(f) else lit(null).as(f)): _*) } }
- 31. DYNAMIC DDL – BATCH SPECIFIC ISSUES • Issue2 : Too many log files -- performance • Solution: We consolidate several data log files Data Frame into chunks, each chunk with all Data Frames union together. val ys: Seq[Seq[DataFrame]] = destTableDFs.seq.grouped(mergeChunkSize).toSeq val dfs: ParSeq[DataFrame] = ys.par.map(p => p.foldLeft(emptyDF) { (z, a) => z.unionAll(a) }) dfs.foreach(saveDataFrame(info, _))
- 32. SUMMARY
- 33. SUMMARY •GoPro Data Platform is in transition and we just get started •Central Hive Meta store + S3 separate storage + computing, reduce cost •Introducing cloud computing for elasticity and reduce operation complexity •Leverage dynamic DDL for flexible ingestion, aggregation and snapshot for both batch and streaming
- 34. PG # RC Playbook: Your guide to success at GoPro Questions?
Editor's Notes
- #7: Variety of Data Software – Mobile, Desktop and Cloud Apps Hardware – Camera, Drone, Drone Controller, VR, Accessories, Developer Program 3rd Party data – CRM, Social Media, OTT, E-Commerce etc. Variety of data Ingestion mechanism Real-Time Streaming pipeline Batch pipeline -- pushed or pulled data Complex data transformation Data often stored as binary to conserve space in camera Special logics for pair events and flight time correction Heterogeneous data format (json, csv, binary) Seamless data aggregation Combine data from both hardware and software Building data structures of both event-based and state-based
- #8: Scalability Challenges Increase number of data sources and services requests Quick visibility of the data Infrastructure scalability Data Quality Tools and infrastructure for QA process Hadoop DevOp Challenges Manage Hadoop hardware (disk, security, service, dev and staging clusters) Monitoring Data Pipeline Monitoring metrics and infrastructure Enable Predictive Analytics Tools for Machine Learning and exploratory analytics Cost management AWS (storage & computing) as well as License costs
- #24: .