Big Data Analytics and Ubiquitous computing
1 like351 views

Big Data Analytics and Ubiquitous Computing is a document that discusses big data analytics using Apache Spark and ubiquitous computing concepts. It provides an overview of Spark, including Resilient Distributed Datasets (RDDs), and libraries for SQL, machine learning, graph processing, and streaming. It also discusses parallel FP-Growth (PFP) for recommendation and ubiquitous computing approaches like edge computing, cloudlets, fog computing, and virtualization. Virtual conferencing using tools like Google Meet, Skype and Microsoft Teams is also summarized.





















![PFP: Parallel FP-Growth
FP-Growth implementation takes the following (hyper-)parameters
minSupport: the minimum support for an itemset to be identified as
frequent e.g., if an item appears 3 out of 5 transactions, it has a support of
3/5=0.6.
minConfidence: minimum confidence for generatingAssociation Rule e.g., if
in the transactions itemset X appears 4 times, X andY co-occur only 2 times,
the confidence for the rule X =>Y is then 2/4 = 0.5.
numPartitions: the number of partitions used to distribute the work.
FP-Growth model provides:
freqItemsets: frequent itemsets in the format of DataFrame(“items”[Array],
“freq”[Long])
associationRules: association rules generated with confidence above
minConfidence, in the format of DataFrame(“antecedent”[Array],
“consequent”[Array], “confidence”[Double]).](https://image.slidesharecdn.com/5-201202070026/85/Big-Data-Analytics-and-Ubiquitous-computing-22-320.jpg)







































Big Data Analytics and Ubiquitous computing
- 1. Big Data Analytics and Ubiquitous Computing by Dr.Animesh Chaturvedi Assistant Professor: LNMIIT Jaipur Post Doctorate: King’s College London &TheAlanTuring Institute PhD: IIT Indore
- 2. Big Data Analytics Big Data Analytics 1. Big Data 2. Spark: Big Data Analytics 3. Resilient Distributed Datasets (RDD) 4. Spark libraries (SQL, DataFrames, MLlib for machine learning, GraphX, and Streaming) 5. PFP: Parallel FP-Growth Ubiquitous Computing
- 3. Big Data Big data can be described by the following characteristics: Volume: size large than terabytes and petabytes Variety: type and nature, structured, semi-structured or unstructured Velocity: speed of generation and processing to meet the demands Veracity: the data quality and the data value Value: Useful or not useful The main components and ecosystem of Big Data DataAnalytics: data mining, machine learning and natural language processing Technologies: Business Intelligence, Cloud computing & Databases Visualization: Charts, Graphs etc.
- 4. Apache Spark Unified analytics engine for large-scale data processing. Speed: Run workloads 100x faster. Both batch and streaming data, using DirectedAcyclic Graph (DAG) scheduler, a query optimizer, and a physical execution engine. Ease of Use:Write applications quickly in Java, Scala, Python, R, and SQL. Spark offers 80+ high-level operators to build parallel apps. https://spark.apache.org/
- 5. Spark: Unified Big Data Analytics New applications of Big data workloads on Unified Engine of Streaming, Batch, and Interactive. Composability in programming libraries for big data and encourages development of interoperable libraries Combining the SQL, machine learning, and streaming libraries in Spark Zaharia, Matei, et al. "Apache spark: a unified engine for big data processing." Communications of the ACM 59.11 (2016): 56-65.
- 6. Spark: Unified Big Data Analytics Spark has MapReduce programming model with extended data-sharing abstraction called “Resilient Distributed Datasets,” or RDDs. Zaharia, Matei, et al. "Apache spark: a unified engine for big data processing." Communications of the ACM 59.11 (2016): 56-65.
- 7. Spark Architecture Spark works on the popular Master-Slave architecture. Cluster works with a single master and multiple slaves. The Spark architecture depends upon two abstractions: Resilient Distributed Dataset (RDD) Directed Acyclic Graph (DAG) https://spark.apache.org/docs/latest/cluster-overview.html
- 8. Resilient Distributed Datasets (RDD) A distributed memory abstraction: perform in-memory computations on large clusters Keeping data in memory can improve performance Spark runtime: Driver program launches multiple workers that read data blocks from a distributed file system and can persist computed RDD partitions in memory. Zaharia, Matei, et al. "Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing." Presented as part of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12). 2012.
- 9. Resilient Distributed Datasets (RDD) Zaharia, Matei, et al. "Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing." Presented as part of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12). 2012. Each box is an RDD, with partitions as shaded rectangles. narrow dependencies, where each partition of the parent RDD is used by at most one partition of the child RDD, wide dependencies, where multiple child partitions may depend on it.
- 10. Resilient Distributed Datasets (RDD) Direct Acyclic Graph (DAG) to perform a sequence of computations Each node is an RDD partition, Run an action (e.g.,count or save) on an RDD, the scheduler examines that RDD’s lineage graph to build a DAG of stages to execute. Zaharia, Matei, et al. "Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing." Presented as part of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12). 2012. Each stage contains with narrow dependencies The boundaries of the stages are the shuffle operations required for wide dependencies. Scheduler computes missing partitions until it computed RDD.
- 11. Apache Spark Combine SQL, streaming, and complex analytics. Spark libraries SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. Spark runs on Hadoop,Apache Mesos, Kubernetes, standalone, or in the cloud. Run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS,Alluxio,Apache Cassandra,Apache HBase,Apache Hive, and hundreds of other data sources. https://spark.apache.org/
- 12. Spark Code Example Word Count Pi Estimation
- 13. Spark SQL Working with structured data. Integrated: SQL queries with Spark programs. results = spark.sql("SELECT * FROM people") names = results.map(lambda p: p.name) Apply functions to results of SQL queries. Uniform DataAccess: Connect to data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. spark.read.json("s3n://...").registerTempTable("json") results = spark.sql("""SELECT * FROM people JOIN json ...""") Query and join different data sources Hive Integration Spark HiveQL Standard Connectivity: Connect through JDBC or ODBC. Business intelligence tools to query big data. https://spark.apache.org/sql/
- 14. DataFrame API Examples Collection of data organized into named columns Use DataFrame API to perform various relational operations Automatically optimized by Spark’s built-in optimizer
- 15. Spark Streaming Build scalable fault-tolerant streaming applications. Write streaming jobs -- SameWay --Write batch jobs Counting tweets on a sliding window TwitterUtils.createStream(...) .filter(_.getText.contains("Spark")) .countByWindow(Seconds(5)) Reuse the same code for batch processing Find words with higher frequency than historic data: stream.join(historicCounts).filter { case (word, (curCount, oldCount)) => curCount > oldCount } https://spark.apache.org/streaming/
- 16. Spark GraphX Spark'sAPI for graphs and graph-parallel computation graph = Graph(vertices, edges) messages = spark.textFile("hdfs://...") graph2 = graph.joinVertices(messages) { (id, vertex, msg) => ... } Fast Speed for graph algorithms GraphX graph algorithms PageRank Connected components Label propagation SVD++ Strongly connected components Triangle count https://spark.apache.org/graphx/
- 17. Spark MLlib Spark's scalable machine learning library Spark MLlib algorithms Classification: logistic regression, naive Bayes,... Regression: generalized linear regression, survival regression,... Decision trees, Random forests, and Gradient-boosted trees Recommendation:Alternating Least Squares (ALS) Clustering: K-means, Gaussian mixtures (GMMs),... Topic modeling: Latent Dirichlet Allocation (LDA) Frequent itemsets,Association rules, and Sequential pattern mining https://spark.apache.org/graphx/
- 18. FP-Growth for recommendation “FP” stands for Frequent Pattern in a Dataset of transactions 1. calculate item frequencies and identify frequent items, 2. a suffix tree (FP-tree) structure to encode transactions, and 3. frequent itemsets can be extracted from the FP-tree. Input:Transaction database Intermediate Output: FP-Tree Output: {f, c, a a, m p}, {f, c, a b, m} Han Jiawei, Jian Pei, and YiwenYin. "Mining frequent patterns without candidate generation." ACM SIGMOD Record 29.2 (2000): 1-12.
- 19. PFP: Parallel FP-Growth In Spark ML-Library (MLLib), a parallel version of FP- growth called PFP: Parallel FP-Growth PFP distributes the work of growing FP-trees based on the suffixes of transactions. More scalable than a single-machine implementation. PFP partitions computation, where each machine executes an independent group of mining tasks Li, Haoyuan, et al. "PFP: Parallel FP-Growth for query recommendation." Proceedings of the 2008 ACM Conference on Recommender systems. 2008.
- 20. PFP: Parallel FP-Growth Example of MapReduce FP-Growth: Five transactions composed of lower-case alphabets representing items Li, Haoyuan, et al. "PFP: Parallel FP-Growth for query recommendation." Proceedings of the 2008 ACM Conference on Recommender systems. 2008.
- 21. Sharding: Divide DB into successive parts and storing the parts (as a Shard) on P different computers. Parallel Counting: MapReduce counts the support of all items that appear in DB. Each mapper inputs one shard of DB. The result is stored in F-list. Grouping Items: Dividing all the items on F-List into Q groups of a list (G-list). Parallel FP-Growth: A MapReduce - Mapper: Each mapper uses a Shard. It reads a transaction in the G-list and outputs one or more key-value pairs, where each key is a group-id and value is a group-dependent transaction. - For each group-id, the MapReduce groups all group-dependent transactions into a shard. - Reducer: Each reducer processes one or more group-dependent Shard. For each shard, a reducer builds a local FP-Tree and discover patterns. Aggregating: Aggregate the results generated as final result. Li, Haoyuan, et al. "PFP: Parallel FP-Growth for query recommendation." ACM Conf.on Recommender systems. 2008.
- 22. PFP: Parallel FP-Growth FP-Growth implementation takes the following (hyper-)parameters minSupport: the minimum support for an itemset to be identified as frequent e.g., if an item appears 3 out of 5 transactions, it has a support of 3/5=0.6. minConfidence: minimum confidence for generatingAssociation Rule e.g., if in the transactions itemset X appears 4 times, X andY co-occur only 2 times, the confidence for the rule X =>Y is then 2/4 = 0.5. numPartitions: the number of partitions used to distribute the work. FP-Growth model provides: freqItemsets: frequent itemsets in the format of DataFrame(“items”[Array], “freq”[Long]) associationRules: association rules generated with confidence above minConfidence, in the format of DataFrame(“antecedent”[Array], “consequent”[Array], “confidence”[Double]).
- 24. Ubiquitous Computing Big DataAnalytics (Apache Spark (SQL, Mllib, GraphX)) Ubiquitous Computing 1. Edge Computing 2. Cloudlet 3. Fog computing 4. Internet ofThings (IoT) 5. Virtualization 6. Virtual Conferencing 7. Virtual Events (2D, 3D, and Hybrid)
- 25. Ubiquitous computing MarkWeiser:Three basic ubiquitous computing devices: Tabs: a wearable device that is approx in centimeters Pads: a hand-held device that is approximately a decimeter in size Boards: an interactive larger display device that is approximately a meter in size computing is made to appear anytime and everywhere any device, in any location, and in any format Weiser, Mark. "The computer for the 21st century." ACM SIGMOBILE mobile computing and communications review 3.3 (1999): 3-11. https://en.wikipedia.org/wiki/Ubiquitous_computing
- 26. Edge computing Distributed computing paradigm Computation and data storage closer to the user location Improve response times and save bandwidth Cloud computing operates on big data, whereas Edge computing operates on “instant data” Content Delivery Network or Content Distribution Network (CDN) (Refer to Unit 4) Akamai CDN (Refer to Unit 4) Akamai-Facebook’s Photo-Serving Stack (Refer to Unit 4) https://en.wikipedia.org/wiki/Edge_computing
- 27. Cloudlet First coined by Mahadev Satyanarayanan (Satya),Victor Bahl, Ramón Cáceres, and Nigel Davie It is a mobility-enhanced small-scale cloud datacenter that is located at the edge of the Internet. It work as a data center in a box which brings the cloud closer. Support resource-intensive and interactive mobile applications by providing powerful computing resources to mobile devices with lower latency. https://en.wikipedia.org/wiki/Cloudlet
- 28. Fog computing Architecture that distributes computing, storage, control and networking functions closer to the users along a cloud-to-thing. Fog computing is often erroneously called edge computing, but there are key differences. Fog works with the cloud, whereas edge is defined by the exclusion of cloud. Fog is hierarchical where edge tends to be limited to a small number of layers. Cloud computing deal with Big Data, whereas Fog computing deals with real-time data generated by sensors or users. 1 IEEE StandardAssociation. "IEEE 1934-2018-IEEE Standard for adoption of OpenFog reference architecture for fog computing." (2018). https://en.wikipedia.org/wiki/Fog_computing
- 29. Internet of Things (IoT) The network of physical objects —“things”— embedded with sensors, software, and other technologies for the purpose of connecting and exchanging data with other devices and systems over the Internet. Example: “Smart Home” devices and appliances, “Smart city” equipment and facilities, Real-Time Data Analytics Information explosion or Data Deluge due to data flood or information flood ever-increasing amount of electronic data exchanged per time unit unmanageable amounts of data growthV/S power of data processing https://en.wikipedia.org/wiki/Internet_of_things
- 30. Virtualization Virtual computer hardware platforms, storage devices, and computer network resources. Hardware virtualization or platform virtualization refers to the creation of aVirtual Machine (VM). Full virtualization – complete simulation of the actual hardware to allow software environments, guest operating system and its apps. Paravirtualization – the guest apps are executed in their own isolated domains. Application virtualization andWorkspace virtualization: isolating individual apps from the underlying OS and other apps Service virtualization: emulating the behavior ofAPI, Cloud and SOA https://en.wikipedia.org/wiki/Virtualization
- 31. Virtualization Memory virtualization: aggregating RAM resources from networked systems into a single memory pool Virtual memory: giving an app the impression that it has contiguous working memory, isolating the underlying physical memory Storage virtualization: the process of completely abstracting logical storage from physical storage Distributed file system: any file system that allows access to files from multiple hosts sharing via a computer network Virtual file system: an abstraction layer on top of a more concrete file system Storage hypervisor: combines physical storage resources into one or more flexible pools of logical storage https://en.wikipedia.org/wiki/Virtualization
- 32. Virtualization Virtual disk: emulates a disk drive such as a hard disk drive or optical disk drive Data virtualization: the presentation of data as an abstract layer, independent of underlying database systems, structures and storage Database virtualization: the decoupling of the database layer, which lies between the storage and application layers Network virtualization: creation of a virtualized network addressing space within or across network subnets Virtual private network (VPN): replaces the actual wire or other physical media in a network with an abstract layer https://en.wikipedia.org/wiki/Virtualization
- 33. Virtual Conferencing Teleconference: Phone lines, Landlines or Cellular devices Video conference: Webcam, Microphone, Speaker, Internet hardware, software, devices is dedicated for this Web Conference: Internet and Cloud supported Web 2.0 Well-Known: Google Meet, Skype, and MicrosoftTeam Multi-Communications from Many sender to Many receivers Webinars ("web seminars"),Webcasts (live media presentation), Podcast (audio presentation), and web meetings Virtual Events https://en.wikipedia.org/wiki/Internet_of_things
- 34. Virtual Events An online event involves people interacting in a virtual environment on the web, instead of physical meeting. Multi-session online events often feature webinars and webcasts. Aim to create similar experience as physical meeting. Live-streaming the event online or on-demand video. Issues Echo of voice Audio andVideography logistics Network Bandwidth of conferencing server and users https://en.wikipedia.org/wiki/Virtual_event
- 35. 2D Virtual Events: Edited Collage
- 36. 2D Virtual Events: Virtual Degree
- 37. 2D Virtual Events: Virtual Address
- 38. 3D Virtual Event: Live Video Virtual HLF 2020 - Heidelberg Laureate Forum
- 39. 3D Virtual Event: Virtual HLF 2020 - Heidelberg Laureate Forum
- 40. 3D Virtual Event: Poster Sessions Virtual HLF 2020 - Heidelberg Laureate Forum
- 41. 3D Virtual Event: Poster Sessions Virtual HLF 2020 - Heidelberg Laureate Forum
- 42. 3D Virtual Event: Poster Sessions Virtual HLF 2020 - Heidelberg Laureate Forum
- 43. 3D Virtual Event: Poster Sessions Virtual HLF 2020 - Heidelberg Laureate Forum
- 44. 3D Virtual Event: Virtual Gathering Virtual HLF 2020 - Heidelberg Laureate Forum
- 45. 3D Virtual Event: Recreations Virtual HLF 2020 - Heidelberg Laureate Forum
- 46. 3D Virtual Event: Virtual Dancing Virtual HLF 2020 - Heidelberg Laureate Forum
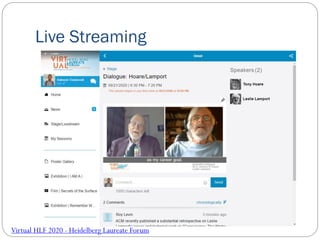
- 47. Live Streaming Virtual HLF 2020 - Heidelberg Laureate Forum
- 48. Hybrid Event Combines a “physical" in-person event with a "virtual" online component Tradeshow, Conference, Seminar,Workshop, Convocation https://en.wikipedia.org/wiki/Hybrid_event
- 49. Hybrid Event: Landing Page
- 51. Hybrid Event: Help Chat FrontEnd
- 52. Hybrid Event: Help Chat BackEnd
- 53. Hybrid Event: Mosaic Wall
- 54. Hybrid Event: Mosaic Wall
- 55. Hybrid Event: Blowing Flower Effect
- 56. Hybrid Event: Welcome WebCast
- 57. Hybrid Event: Virtual Address
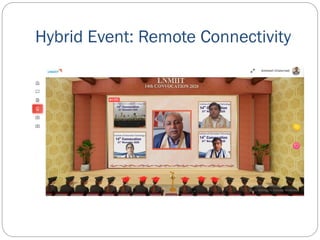
- 58. Hybrid Event: Remote Connectivity
- 59. Hybrid Event: Virtual Degree
- 60. Hybrid Event: Physical Degree
- 61. References https://spark.apache.org/ Zaharia, Matei, et al. "Apache spark: a unified engine for big data processing." Communications of theACM 59.11 (2016): 56-65. Zaharia, Matei, et al. "Resilient distributed datasets:A fault-tolerant abstraction for in- memory cluster computing." Presented as part of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12). 2012. https://spark.apache.org/docs/latest/cluster-overview.html https://spark.apache.org/ https://spark.apache.org/sql/ https://spark.apache.org/streaming/ https://spark.apache.org/graphx/ Han Jiawei, Jian Pei, and YiwenYin. "Mining frequent patterns without candidate generation." ACM SIGMOD Record 29.2 (2000): 1-12. Li, Haoyuan, et al. "PFP: Parallel FP-Growth for query recommendation." Proceedings of the 2008 ACM Conference on Recommender systems. 2008.
- 62. References Weiser, Mark. "The computer for the 21st century." ACM SIGMOBILE mobile computing and communications review 3.3 (1999): 3-11. https://en.wikipedia.org/wiki/Ubiquitous_computing https://en.wikipedia.org/wiki/Edge_computing https://en.wikipedia.org/wiki/Cloudlet IEEE StandardAssociation. "IEEE 1934-2018-IEEE Standard for adoption of OpenFog reference architecture for fog computing." (2018). https://en.wikipedia.org/wiki/Fog_computing https://en.wikipedia.org/wiki/Virtual_event Virtual HLF 2020 - Heidelberg Laureate Forum https://en.wikipedia.org/wiki/Hybrid_event