Big data and Hadoop
Download as PPTX, PDF42 likes84,434 views

This document provides an overview of big data and Hadoop. It discusses why Hadoop is useful for extremely large datasets that are difficult to manage in relational databases. It then summarizes what Hadoop is, including its core components like HDFS, MapReduce, HBase, Pig, Hive, Chukwa, and ZooKeeper. The document also outlines Hadoop's design principles and provides examples of how some of its components like MapReduce and Hive work.

















Big data and Hadoop
- 1. Big Data and HadoopRahul Agarwalirahul.com
- 10. What is Hadoop
- 11. HDFS
- 12. MapReduce
- 13. HBase
- 14. PIG
- 15. HIVE
- 16. Chukwa
- 17. ZooKeeper
- 18. Q&AAgenda
- 19. Why?
- 20. Extremely large datasets that are hard to deal with using Relational DatabasesStorage/CostSearch/PerformanceAnalytics and VisualizationNeed for parallel processing on hundreds of machinesETL cannot complete within a reasonable timeBeyond 24hrs – never catch upBig Data
- 21. System shall manage and heal itselfAutomatically and transparently route around failureSpeculatively execute redundant tasks if certain nodes are detected to be slowPerformance shall scale linearlyProportional change in capacity with resource changeCompute should move to dataLower latency, lower bandwidthSimple core, modular and extensibleHadoop design principles
- 22. A scalablefault-tolerantgrid operating system for data storage and processingCommodity hardwareHDFS: Fault-tolerant high-bandwidth clustered storageMapReduce: Distributed data processingWorks with structured and unstructured dataOpen source, Apache licenseMaster (named-node) – Slave architectureWhat is Hadoop
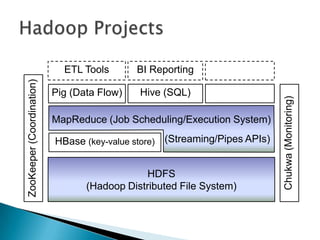
- 23. Hadoop ProjectsBI ReportingETL ToolsHive (SQL)Pig (Data Flow)MapReduce (Job Scheduling/Execution System)ZooKeeper (Coordination)(Streaming/Pipes APIs)HBase (key-value store)Chukwa (Monitoring)HDFS(Hadoop Distributed File System)
- 24. HDFS: Hadoop Distributed FSBlock Size = 64MBReplication Factor = 3
- 25. Patented Google frameworkDistributed processing of large datasetsmap (in_key, in_value) -> list(out_key, intermediate_value)reduce (out_key, list(intermediate_value)) -> list(out_value)MapReduce
- 26. Example: count word occurences
- 27. “Project's goal is the hosting of very large tables - billions of rows X millions of columns - atop clusters of commodity hardware”Hadoop database, open-source version of Google BigTableColumn-orientedRandom access, realtime read/write“Random access performance on par with open source relational databases such as MySQL” HBase
- 28. High level language (Pig Latin) for expressing data analysis programsCompiled into a series of MapReduce jobsEasier to programOptimization opportunitiesgrunt> A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, gpa:float);grunt> B = FOREACH A GENERATE name;PIG
- 29. Managing and querying structured dataMapReduce for executionSQL like syntaxExtensible with types, functions, scriptsMetadata stored in a RDBMS (MySQL)Joins, Group By, NestingOptimizer for number of MapReduce requiredhive> SELECT a.foo FROM invites a WHERE a.ds='<DATE>';HIVE
- 30. A highly available, scalable, distributed, configuration, consensus, group membership, leader election, naming, and coordination serviceCluster ManagementLoad balancingJMX monitoringZooKeeper
- 31. Data collection system for monitoring distributed systems
- 32. Agents to collect and process logs
- 34. Hadoop Infrastructure Care CenterChukwa
- 35. Data Flow at Facebook
- 36. Choose the right toolHadoop
- 42. ACID
- 43. Structured data
Editor's Notes
- #5: Analyzing large amounts of data is the top predicted skill required!
- #10: Pool commodity servers in a single hierarchical namespace.Designed for large files that are written once and read many times.Example here shows what happens with a replication factor of 3, each data block is present in at least 3 separate data nodes.Typical Hadoop node is eight cores with 16GB ram and four 1TB SATA disks.Default block size is 64MB, though most folks now set it to 128MB
- #18: Example flow as at Facebook
- #19: Aircraft is refined, very fast, and has a lot of addons/features. But it is pricey on a per bit basis and is expensive to maintainCargo train is rough, missing a lot of “luxury”, slow to accelerate, but it can carry almost anything and once it gets going it can move a lot of stuff very economically