




![Hadoop Interface
[training@localhost ~]$ hdfs dfsadmin -report
Configured Capacity: 15118729216 (14.08 GB)
Present Capacity: 10163642368 (9.47 GB)
DFS Remaining: 9228095488 (8.59 GB)
DFS Used: 935546880 (892.21 MB)
DFS Used%: 9.2%
Under replicated blocks: 3
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 1 (1 total, 0 dead)
Live datanodes:
Name: 127.0.0.1:50010 (localhost.localdomain)
Hostname: localhost.localdomain
Decommission Status : Normal
Configured Capacity: 15118729216 (14.08 GB)
DFS Used: 935546880 (892.21 MB)
Non DFS Used: 4955086848 (4.61 GB)
DFS Remaining: 9228095488 (8.59 GB)
DFS Used%: 6.19%
DFS Remaining%: 61.04%
Last contact: Mon Jan 18 14:05:48 EST 2016](https://image.slidesharecdn.com/hadoop-160127225411/85/BIG-DATA-Apache-Hadoop-6-320.jpg)
![Hadoop Interface
[training@localhost ~]$ hadoop fs -help get
-get [-ignoreCrc] [-crc] <src> ... <localdst>: Copy files that match the file pattern <src>
to the local name. <src> is kept. When copying multiple,
files, the destination must be a directory.
hadoop fs –ls
hadoop fs -put purchases.txt
hadoop fs -put access_log
hadoop fs -ls
hadoop fs -tail purchases.txt
hadoop fs get filename
hs {mapper script} {reducer script} {input_file} {output directory}
hs mapper.py reducer.py myinput joboutput](https://image.slidesharecdn.com/hadoop-160127225411/85/BIG-DATA-Apache-Hadoop-7-320.jpg)












![Hadoop MapReduce
Usage: $HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar [options]
Options:
-input <path> DFS input file(s) for the Map step
-output <path> DFS output directory for the Reduce step
-mapper <cmd|JavaClassName> The streaming command to run
-combiner <cmd|JavaClassName> The streaming command to run
-reducer <cmd|JavaClassName> The streaming command to run
-file <file> File/dir to be shipped in the Job jar file
-inputformat TextInputFormat(default)|SequenceFileAsTextInputFormat|JavaClassName Optional.
-outputformat TextOutputFormat(default)|JavaClassName Optional.
-partitioner JavaClassName Optional.
-numReduceTasks <num> Optional.
-inputreader <spec> Optional.
-cmdenv <n>=<v> Optional. Pass env.var to streaming commands
-mapdebug <path> Optional. To run this script when a map task fails
-reducedebug <path> Optional. To run this script when a reduce task fails
-io <identifier> Optional.
-verbose
hs {mapper script} {reducer script} {input_file} {output directory}
hs mapper.py reducer.py myinput joboutput](https://image.slidesharecdn.com/hadoop-160127225411/85/BIG-DATA-Apache-Hadoop-21-320.jpg)








BIG DATA: Apache Hadoop
- 1. A part of the Nordic IT group EVRY Infopulse Oleksiy Krotov (Expert Oracle DBA) 19.01.2016 BIG DATA: Apache Hadoop
- 2. BIG DATA: Apache Hadoop 2 Apache Hadoop HADOOP ARCHITECTURE HADOOP INTERFACE HADOOP DISTRIBUTED FILE SYSTEM (HDFS) HADOOP MAPREDUCE ORACLE BIG DATA RESOURCES
- 3. Hadoop Architecture Apache Hadoop is an open-source framework for distributed storage and distributed processing of very large data sets storage part known as Hadoop Distributed File System (HDFS) processing part called MapReduce. Hadoop splits files into large blocks and distributes them across nodes in a cluster. To process data, Hadoop transfers packaged code for nodes to process in parallel based on the data that needs to be processed.
- 4. Hadoop Architecture Biggest Hadoop cluster: Yahoo! has more than 100,000 CPUs in over 40,000 servers running Hadoop, with its biggest Hadoop cluster running 4,500 nodes with 455 PetaBytes of data in Hadoop (2014) More than half of the Fortune 50 companies run open source Apache Hadoop based on Cloudera. (2012) The HDFS file system is not restricted to MapReduce jobs. It can be used for other applications, many of which are under development at Apache. The list includes the HBase database, the Apache Mahout machine learning system, and the Apache Hive Data Warehouse system. Hadoop can in theory be used for any sort of work that is batch-oriented rather than real-time, is very data-intensive, and benefits from parallel processing of data.
- 5. Hadoop Architecture NameNode hosts metadata (file system index of files and blocks) DataNode hosts the data (blocks) JobTracker is a master which creates and runs the job
- 6. Hadoop Interface [training@localhost ~]$ hdfs dfsadmin -report Configured Capacity: 15118729216 (14.08 GB) Present Capacity: 10163642368 (9.47 GB) DFS Remaining: 9228095488 (8.59 GB) DFS Used: 935546880 (892.21 MB) DFS Used%: 9.2% Under replicated blocks: 3 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 1 (1 total, 0 dead) Live datanodes: Name: 127.0.0.1:50010 (localhost.localdomain) Hostname: localhost.localdomain Decommission Status : Normal Configured Capacity: 15118729216 (14.08 GB) DFS Used: 935546880 (892.21 MB) Non DFS Used: 4955086848 (4.61 GB) DFS Remaining: 9228095488 (8.59 GB) DFS Used%: 6.19% DFS Remaining%: 61.04% Last contact: Mon Jan 18 14:05:48 EST 2016
- 7. Hadoop Interface [training@localhost ~]$ hadoop fs -help get -get [-ignoreCrc] [-crc] <src> ... <localdst>: Copy files that match the file pattern <src> to the local name. <src> is kept. When copying multiple, files, the destination must be a directory. hadoop fs –ls hadoop fs -put purchases.txt hadoop fs -put access_log hadoop fs -ls hadoop fs -tail purchases.txt hadoop fs get filename hs {mapper script} {reducer script} {input_file} {output directory} hs mapper.py reducer.py myinput joboutput
- 10. Hadoop Distributed File System (HDFS) HDFS is a Java-based file system that provides scalable and reliable data storage, and it was designed to span large clusters of commodity servers. HDFS is a scalable, fault-tolerant, distributed storage system that works closely with a wide variety of concurrent data access applications
- 11. Hadoop Distributed File System (HDFS)
- 12. Hadoop Distributed File System (HDFS)
- 13. Hadoop Distributed File System (HDFS) Default replication value 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high Apache Hadoop can work with additional file systems: FTP, Amazon S3, Windows Azure Storage Blobs (WASB)
- 14. Hadoop MapReduce Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner. A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks.
- 15. Hadoop MapReduce
- 16. Hadoop MapReduce
- 17. Hadoop MapReduce
- 18. Hadoop MapReduce
- 19. Hadoop MapReduce
- 20. Hadoop MapReduce
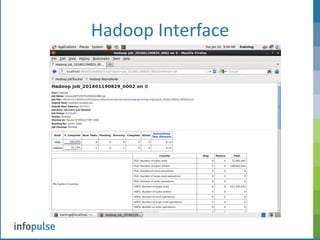
- 21. Hadoop MapReduce Usage: $HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar [options] Options: -input <path> DFS input file(s) for the Map step -output <path> DFS output directory for the Reduce step -mapper <cmd|JavaClassName> The streaming command to run -combiner <cmd|JavaClassName> The streaming command to run -reducer <cmd|JavaClassName> The streaming command to run -file <file> File/dir to be shipped in the Job jar file -inputformat TextInputFormat(default)|SequenceFileAsTextInputFormat|JavaClassName Optional. -outputformat TextOutputFormat(default)|JavaClassName Optional. -partitioner JavaClassName Optional. -numReduceTasks <num> Optional. -inputreader <spec> Optional. -cmdenv <n>=<v> Optional. Pass env.var to streaming commands -mapdebug <path> Optional. To run this script when a map task fails -reducedebug <path> Optional. To run this script when a reduce task fails -io <identifier> Optional. -verbose hs {mapper script} {reducer script} {input_file} {output directory} hs mapper.py reducer.py myinput joboutput
- 22. Oracle Big Data Connectors Load Data into the Database Oracle Loader for Hadoop – Map Reduce job transforms data on Hadoop into Oracle-ready data types – Use more Hadoop compute resources Oracle SQL Connector for HDFS – Oracle SQL access to data on Hadoop via external tables – Use more database compute resources – Includes option to query in-place
- 23. Oracle Big Data Connectors Load Data into the Database Oracle Loader for Hadoop – Map Reduce job transforms data on Hadoop into Oracle-ready data types – Use more Hadoop compute resources Oracle SQL Connector for HDFS – Oracle SQL access to data on Hadoop via external tables – Use more database compute resources – Includes option to query in-place
- 24. Oracle Big Data Connectors
- 25. Oracle Big Data Appliance X5-2 Enterprise-class security for Hadoop through Oracle Big Data SQL, which also provides the ability to use a simple SQL query to quickly explore data across Hadoop, SQL, and relational databases.
- 27. Thank you for attention! BIG DATA: Apache Hadoop 27
- 28. BIG DATA: Apache Hadoop 28
- 29. Contact us! Address: 03056, 24, Polyova Str., Kyiv, Ukraine Phone: +38 044 457-88-56 Email: [email protected] Contact us! Address: 03056, 24, Polyova Str., Kyiv, Ukraine Phone: +38 044 457-88-56 Email: [email protected] BIG DATA: Apache Hadoop 29