





























Big data architecture on cloud computing infrastructure
- 1. Big Data Architecture on Cloud Computing Infrastructure Reza Bakhshayeshi
- 2. About me • Reza Bakhshayeshi • MSc. Information Technology – Computer Networks • 7 years of experience in Cloud Computing research • 3 years of experience in industry • Email: [email protected] 2
- 3. Agenda • Cloud Computing • Introduction to OpenStack • Why OpenStack • What is Sahara? • Sahara Architecture • Lab Session 3
- 5. Five Essential Characteristics • Based on NIST: 5
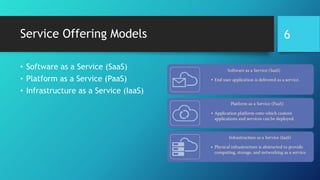
- 6. Service Offering Models • Software as a Service (SaaS) • Platform as a Service (PaaS) • Infrastructure as a Service (IaaS) 6
- 7. Introduction to OpenStack • OpenStack began in 2010 as a joint project of Rackspace Hosting and NASA. • OpenStack is a free and open-source software platform for cloud computing, mostly deployed as an infrastructure-as-a-service (IaaS) 7
- 8. Why OpenStack? • OpenStack elevates your business to the cloud. OpenStack is a scalable, open sourced cloud computing platform. • Comprised of modular, scalable, and flexible set of utilities; provides clients with value, efficiency, and agility. 8
- 9. Why OpenStack? • Open-source; the technology is supported by a large community of developers. • Tried and tested by large businesses. • Interoperability and open-source APIs allow admins to manage hybrid IT environments without the additional overhead layer 9
- 10. OpenStack By Numbers 10
- 11. 11
- 12. 12
- 13. 13
- 14. What size organizations use OpenStack? 14
- 15. Increase Maturity in Deployments 15
- 17. 17
- 18. What is Sahara? • Basic Idea comes from Amazon Elastic MapReduce (EMR) • Sahara’s mission is to provide a scalable data processing stack and associated management interfaces. • Provision and operate data processing clusters • Schedule and operate data processing jobs • Data Processing ~ Hadoop, Spark, Storm, etc. 18
- 19. What is Sahara? • Sahara aims to provide users with a simple means to provision Hadoop, Spark, and Storm clusters by specifying several parameters such as the: oVersion oCluster topology oHardware node details and more. 19
- 20. Use Cases • Fast provisioning of data processing clusters on OpenStack for development and quality assurance(QA). • Utilization of unused compute power from a general purpose OpenStack IaaS cloud. • “Analytics as a Service” for ad-hoc or bursty analytic workloads (similar to AWS EMR). 20
- 21. Key Features • Designed as an OpenStack component. • Managed through a REST API with a user interface(UI) available as part of OpenStack Dashboard. • Predefined configuration templates with the ability to modify parameters. 21
- 22. Key Features • Support for a variety of data processing frameworks: omultiple Hadoop vendor distributions. oApache Spark and Storm. opluggable system of Hadoop installation engines. ointegration with vendor specific management tools, such as Apache Ambari and Cloudera Management Console. 22
- 23. Key Features - Provision Cluster • Create/Terminate Cluster • Heat API/Nova Direct API • Neutron/Nova Network • Floating IP Management • Anti-affinity • Cluster Scaling • Add Node/Remove Node • Support Plugins • Vanilla/Hortonworks Data Platform/Cloudera/Spark/MapR 23
- 24. Key Features - Elastic Data Processing • Support Job Type • Hive/Pig/MapReduce/MapReduce Streaming/Java/Spark/Shell/HBase • Support Data Locality • Rack/Hypervisor/Swift • Data Source • Internal: Ephemeral Disk/Cinder • External: Swift • Run Job in Transient Cluster 24
- 25. Sahara and OpenStack 25
- 26. Distros • Vanilla Apache Hadoop: 2.6.0, 2.7.1 • Hotonworks Data Platform (HDP): 2.2, 2.3 • Cloudera (CDH): 5.3.x, 5.4.x • MapR: 4.0.x, 5.0.x • Vanilla Apache Spark: 1.0.0, 1.3.1 • Vanilla Apache Storm: 0.9.2 26
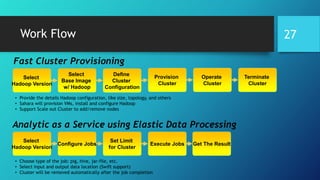
- 27. Fast Cluster Provisioning Select Hadoop Version Select Base Image w/ Hadoop Define Cluster Configuration Provision Cluster Operate Cluster Terminate Cluster Analytic as a Service using Elastic Data Processing Select Hadoop Version Configure Jobs Set Limit for Cluster Execute Jobs Get The Result • Choose type of the job: pig, hive, jar-file, etc. • Select input and output data location (Swift support) • Cluster will be removed automatically after the job completion • Provide the details Hadoop configuration, like size, topology, and others • Sahara will provision VMs, install and configure Hadoop • Support Scale out Cluster to add/remove nodes Work Flow 27
- 28. Swift OpenStack Virtual Clusters OpenStack Virtual Clusters HDFS Collector Agent Data Stream Pattern 2: External - SwiftPattern 1: Internal - HDFS Only Collector Agent Collecting Data Collecting Data OpenStack use Swift as a data source to store input and output data. The benefit is to process the data directly and persist the data via Swift. OpenStack support to create HDFS on Cinder or Ephemeral Disk. This method can provide a better data processing performance via Ephemeral Disk or to persist the data via Cinder with lower performance. Cinder Ephemeral Disk MapReduce MapReduce 28
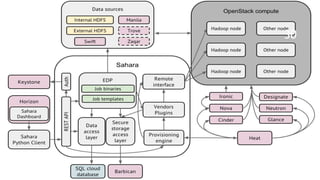
- 29. Architecture 29
- 30. 30
- 31. OpenStack + Sahara notes • CPU: • Estimated virtualization overhead (KVM): < 10% • Isolated networks on OpenStack nodes • Scheduler hints passed by Sahara – place VMs on the same hosts 31
- 32. Lab Session 32
- 33. Questions? 33