






















Big Data Ingestion Using Hadoop - Capstone Presentation
- 1. Big Data Ingestion Using Hadoop : 1038-A 1 Faculty Advisor and Sponsor: Dr. Rohit Aggarwal
- 2. Team Members and Roles Software Developer and Reporting Analyst 2 Data Engineer
- 3. Agenda • Data Scenario today • Why this project and Objective • Business Questions to be answered • Project Infrastructure • Project Workflow • Learnings and Conclusion 3
- 4. Data Scenario today • According to IBM, 80% of data generated today is unstructured • Need to process unstructured data to structured data Outsourcing Data Video Streaming Data Social Media Data Logs Data 4
- 5. Why this Project ? • To learn and implement big data technologies which are used to process log data • Clickstream Log Data as the data source • What is Clickstream data? Clickstream Data is user navigation data on any website 5
- 6. • Big data world comprises of many technologies • Focus of this project is to learn and implement Apache Hadoop ecosystem • Hadoop is primarily used for Data Engineering by many companies notably Amazon, eBay, Walmart 6
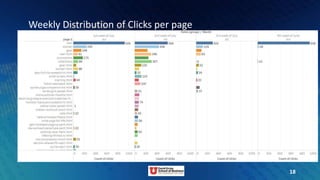
- 7. Business Questions to be answered • Most popular browsing time • Most popular product category • Weekly Distribution of Clicks per page • Customer Conversion Rate 7
- 8. Project Infrastructure Major components of infrastructure • eCommerce Website Setup: Magento eCommerce platform, goDaddy cPanel hosting • Apache Hadoop Setup: Multi Node Cloudera Hadoop cluster on aws EC2 • Data Collection Server: Divolte.js setup on aws EC2 to track custom events from website 8
- 9. Project Workflow • Primarily three stages • Performed several iterations of the below workflow 9
- 10. Stage 1 : Data Collection 10
- 11. Stage 2: Data Ingestion and Engineering • The process of accessing and importing data for immediate usage or storage in a database is called as Data Ingestion • Build Data Pipeline • Transfer files from local Filesystem to HDFS (Hadoop File System) E.g. Apache Sqoop is a popular tool used in big data ecosystem to transfer bulk data 11
- 12. • Data engineering is a process of converting unstructured data to meaningful relational data using set of sophisticated tools or procedures ELT Process (Extract Load Transform) Focus on data transformation using Map Reduce E.g. Components used in this project: • Apache Hive • Apache Pig • Python 12
- 13. Apache Hive • It provides a SQL like interface to query data stored in various databases and file system Application in our project: Avro File (Data Source) Before Run Script After 13
- 14. Apache Pig and Python • It is a high level platform for creating programs on Hadoop. The language used is called as Pig Latin Application in our project: Web Server Log File (Data Source) Before Run Script After 14
- 15. Sample of Python Script 15
- 16. Stage 3: Data Visualization • Final stage of the process • Structured Data exported from Hadoop to csv format • Use of Business Intelligence tools such as Tableau and Power BI 16
- 17. Sample Reports Website Browsing Hour Distribution Customer Conversion Rate 17
- 18. 18 Weekly Distribution of Clicks per page
- 19. 19 Most Popular Product Category
- 20. Challenges Faced • eCommerce Website Setup • Multi-node cluster creation on Amazon Ec2 • Cloudera Hadoop Installation on cluster • Parsing links to get detailed information about Product Category and sub-category 20
- 21. Learnings and Conclusion • Implementation of an end to end project • Technology Stack worked on: 21
- 22. Special Thanks • Thanks to our entire Capstone Faculty team and Sponsor for timely guidance • Bi-weekly progress reports helped us to get a reality check of the project • Great learning experience 22
- 24. Thank You!!! 24
Editor's Notes
- #5: https://www.ibm.com/blogs/watson/2016/05/biggest-data-challenges-might-not-even-know/
- #6: http://searchcrm.techtarget.com/definition/clickstream-analysis
- #12: http://whatis.techtarget.com/definition/data-ingestion http://sqoop.apache.org/
- #13: https://blog.insightdatascience.com/data-science-vs-data-engineering-62da7678adaa
- #14: https://hive.apache.org/
- #15: https://pig.apache.org/
- #16: Python used for parsing text data.
- #21: Multi-node: Elastic IP, VPC, Security Groups. Parsing Links: extracting information from hyperlinks.