Big SQL: Powerful SQL Optimization - Re-Imagined for open source
3 likes1,230 views

IBM Big SQL is a powerful SQL optimizer designed for open source environments, enabling high performance, concurrency, and scalability for analytical SQL workloads on Hadoop. The system integrates with various components like Hive and Spark, allowing for seamless data access and manipulation while maintaining an open-source foundation without vendor lock-in. The document outlines its architecture, features, and performance enhancements, highlighting its ability to run complex queries efficiently.





































































Big SQL: Powerful SQL Optimization - Re-Imagined for open source
- 1. © 2017 IBM Corporation Big SQL: Powerful SQL Optimizer Re-Imagined for open source Paul Yip ([email protected]) WW Product Strategy – Hadoop & Spark Hebert Pereyra ([email protected]) Chief Architect, IBM Big SQL
- 2. © 2017 IBM Corporation Acknowledgements and Disclaimers Availability. References in this presentation to IBM products, programs, or services do not imply that they will be available in all countries in which IBM operates. The workshops, sessions and materials have been prepared by IBM or the session speakers and reflect their own views. They are provided for informational purposes only, and are neither intended to, nor shall have the effect of being, legal or other guidance or advice to any participant. While efforts were made to verify the completeness and accuracy of the information contained in this presentation, it is provided AS-IS without warranty of any kind, express or implied. IBM shall not be responsible for any damages arising out of the use of, or otherwise related to, this presentation or any other materials. Nothing contained in this presentation is intended to, nor shall have the effect of, creating any warranties or representations from IBM or its suppliers or licensors, or altering the terms and conditions of the applicable license agreement governing the use of IBM software. All customer examples described are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual environmental costs and performance characteristics may vary by customer. Nothing contained in these materials is intended to, nor shall have the effect of, stating or implying that any activities undertaken by you will result in any specific sales, revenue growth or other results. © Copyright IBM Corporation 2017. All rights reserved. U.S. Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. IBM, the IBM logo, ibm.com, BigInsights, and Big SQL are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information with a trademark symbol (® or TM), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at “Copyright and trademark information” at www.ibm.com/legal/copytrade.shtml TPC Benchmark, TPC-DS, and QphDS are trademarks of Transaction Processing Performance Council Cloudera, the Cloudera logo, Cloudera Impala are trademarks of Cloudera. Hortonworks, the Hortonworks logo and other Hortonworks trademarks are trademarks of Hortonworks Inc. in the United States and other countries. Other company, product, or service names may be trademarks or service marks of others.
- 3. © 2017 IBM Corporation Abstract Let's be honest - there are some pretty amazing capabilities locked in proprietary SQL engines which have had decades of R&D baked into them. At this session, learn how IBM, working with the Apache community, has unlocked the value of their SQL optimizer for Hive, HBase, ObjectStore, and Spark - helping customers avoid lock-in while providing best performance, concurrency and scalability for complex, analytical SQL workloads. You'll also learn how the SQL engine was extended and integrated with Ambari, Ranger and YARN/Slider. We share the results of this project which has enabled running all 99 TPC-DS queries at world record breaking 100TB scale factor.
- 4. © 2017 IBM Corporation APACHE HIVE FOUNDATION What is Big SQL? Well, it builds on a
- 5. © 2017 IBM Corporation Hive is Really 3 Things Open source SQL on Hadoop SQL Execution Engine Hive (Open Source) Hive Storage Model (open source) CSV Parquet ORC OthersTab Delim. Hive Metastore (open source)MapReduce/ Tez Applications
- 6. © 2017 IBM Corporation Big SQL Preserves Open Source Foundation Leverages Hive metastore and storage formats. No Lock-in. Data part of Hadoop, not Big SQL. Fall back to Open Source Hive Engine at any time. SQL Execution Engines Big SQL (IBM) Hive (Open Source) Hive Storage Model (open source) CSV Parquet ORC OthersTab Delim. Hive Metastore (open source) Applications
- 7. © 2017 IBM Corporation Big SQL Tables are Hive Tables (Here’s the proof...) https://www.youtube.com/watch?v=z7dtkQy-2Aw
- 8. © 2017 IBM Corporation What did you just see? Big SQL tables ARE Hive tables Both Big SQL and Hive see the same tables − Same data on disk − Same definition of table in the metastore Something better comes along? − Uninstall Big SQL, your data remains in open storage formats
- 9. © 2017 IBM Corporation Big SQL Architecture is Consistent with Open Source Patterns Leverages Hive metastore and storage formats. SQL Execution Engines Big SQL (IBM) Hive (Open Source) Hive Storage Model (open source) CSV Parquet ORC OthersTab Delim. Hive Metastore (open source)C/C++ MPP Engine Applications Spark SQL (Open Source) Impala (Open Source)
- 10. © 2017 IBM Corporation The Truth about SQL and Data Warehousing on Hadoop
- 11. © 2017 IBM Corporation What We’re Hearing in the Industry Hive / Hadoop is decent, but I need something better for business intelligence and enterprise reporting workloads I’m having trouble supporting my most complex SQL. These are really difficult or impossible to rewrite. So many options for SQL-on-Hadoop! Where to start?
- 12. © 2017 IBM Corporation 16+ SQL Engines for Hadoop (Alphabetical Ordering) Big SQL (IBM) Drill HAWQ Hive Impala InfiniDB JethroData MemSQL Phoenix Presto Spark SQL Splice Machine Transwarp Trifodion Vertica on Hadoop ( and I’m sure we’re missing a few ) All claim to have advantages over Hive Why can’t we all just agree on one?
- 13. © 2017 IBM Corporation We need to recognize that SQL is Language - Not a Workload Fewer Users Ad Hoc Queries & Discovery Transactional Fast Lookups Operational Data Store Ad Hoc Data Preparation EL-T and Simpler Large Scale Queries Complex SQL, Many Users, Warehousing
- 14. © 2017 IBM Corporation Fewer Users Ad Hoc Queries & Discovery Transactional Fast Lookups Operational Data Store Ad Hoc Data Preparation EL-T and Simpler Large Scale Queries Hive Complex SQL, Many Users, Warehousing Spark SQL Drill Splice-Machine Phoenix + HBase Splice-Machine ??? Every SQL Engines for Hadoop has a “Sweet Spot”
- 15. © 2017 IBM Corporation OUR JOURNEY It started with a crazy idea,..
- 16. © 2017 IBM Corporation Evolving a traditional RDBMS for Hadoop
- 17. © 2017 IBM Corporation DB2 Warehouse (DPF) drives all nodes to read table partitioned across multiple nodes SELECT SUM ( ) FROM some_table DB2 Coordinator node 1 node 2 node 3 node 4 node n Sum(..) Sum(..) Sum(..) Sum(..) Sum(..)
- 18. © 2017 IBM Corporation DB2 Warehouse (DPF) drives all nodes to read table partitioned across multiple nodes Query Result DB2 Coordinator node 1 node 2 node 3 node 4 node n Sum(..) Sum(..) Sum(..) Sum(..) Sum(..)
- 19. © 2017 IBM Corporation Let’s extend the MPP processing concept now to Hadoop Database Client Big SQL (head) node 1 node 2 node 3 node 4 node n HDFS A A A B B B A + BComplete Table = Big SQL Scheduler NameNode
- 20. © 2017 IBM Corporation Big SQL Query Execution Database Client Big SQL (head) node 1 node 2 node 3 node 4 node n HDFS A A A B B B A + BComplete Table = Big SQL Scheduler NameNode
- 21. © 2017 IBM Corporation Big SQL Head Node Big SQL Scheduler Query compilation
- 22. © 2017 IBM Corporation Head Node Client applications The Life of a Big SQL statement User Data Worker Big SQL Catalog Compiler/ Optimizer Runtime Coordinator thread Execution plan generation Plan execution BIG_SQL Data node worker thread Result set flown back over network Parallelized SQL execution per data node Projection Predicate Scan Row Row Row Transform Scanners Read HDFS Readers HDFS TEMPorary Tables BIG_SQL Runtime execution Hive MetaStore
- 23. © 2017 IBM Corporation Management Node Big SQL Master Node Management Node Big SQL Scheduler Big SQL Worker Node Java I/O Native I/O HDFS Data HDFS Data HDFS Data Temp Data Compute Node Database Service Hive Metastore Hive Server Big SQL Worker Node Java I/O Native I/O HDFS Data HDFS Data HDFS Data Temp Data Compute Node Big SQL Worker Node Java I/O Native I/O HDFS Data HDFS Data HDFS Data Temp Data Compute Node So what happens when you bring it all together?
- 24. © 2017 IBM Corporation • The Event Handler (BIEventListener Class) • The Event Consumer (HCAT-AUTOSYNC-OBJECTS Stored Procedure) Augmented metastore synchronization
- 25. © 2017 IBM Corporation Our Journey on Statistics Collection (#1 factor for good performance out-of-box) Version 1 – Map Reduce Jobs to Gather Stats Version 2 – MPP Implementation Up to 11X faster than V.1 Version 3 – what if it was Spark? Analyze: rocket fuel for our SQL optimizer Ability to specify with ALL COLUMNS or some columns Cumulative Statistics • If statistics already exist for columns c1,c3, and c4 and then analyze is executed on columns c7, and c9 the statistics are merged SYSTEM SAMPLING so that you can only scan a % of the table instead of the entire table, default is 10% Auto Analyze: runs autonomically Tunables
- 26. © 2017 IBM Corporation What about HBase, Object Store, etc .? So that was Hive storage .
- 27. © 2017 IBM Corporation Using Big SQL to create and query HBase tables HBase being a columnar key-value store excels at accessing single row or small batches of rows from large datasets. What it lacks is an appropriate SQL interface. ENCODING clause which indicates how to encode the data before storing into HBase. Default for Big SQL is its built-in binary encoding. You get maximum pushdown and numeric collation. DELIMITED encoding is actually a string encoding which makes the data in HBase readable and the USING SERDE encoding is one where a user can specify a SerDe class to encode/decode the data.
- 28. © 2017 IBM Corporation Kafka & Flume Connector(s) for Big SQL (HBase Tables) HBaseHive Table Table Kafka Connector Kafka Connector Big SQL Binary encoding Salting Column mapping options HBaseHive Table Table flumeflume flumeflume flumeflume Big SQL Binary encoding Salting Column mapping options
- 29. © 2017 IBM Corporation Big SQL Tables over Object Store Protocols Supported: S3 Create Tables over Data residing in Object Store directly (no copy required into Hadoop) Once configured, Object Store tables work like any other table in Big SQL Benefits: − No need to copy data into Hadoop first! Query data where it resides. − Partitioning supported! Tradeoff: − Reduced performance relative to local HDFS tables CREATE HADOOP TABLE staff ( ) LOCATION 's3a://s3atables/staff'; LOAD FROMLOAD FROM Object Store also supported!
- 30. © 2017 IBM Corporation Big SQL Tables over WebHDFS (Technical Preview) Transparently access data on any platform implementing WebHDFS − Examples: Microsoft Azure Data Lake Once setup, WebHDFS tables work like any other table in Big SQL Technical Preview Limitations: − WebHDFS via Knox not supported − Reduce performance expected. Big SQLBig SQL Local Hadoop Cluster Remote Hadoop Cluster or WebHDFS enabled Storage CREATE HADOOP TABLE staff ( ) PARTITIONED BY (JOB VARCHAR(5)) LOCATION 'webhdfs://namenode.acme.com:50070/path/to/table/staff'; LOAD FROM WebHDFS also supported!
- 31. © 2017 IBM Corporation “Deep” integration with Spark Head Node Big SQL Head Spark Driver Worker Node Big SQL Worker Spark Executor Worker Node Big SQL Worker Spark Executor Big SQL Worker Spark Executor HDFS Job Data Data Data • BigSQL runs Spark jobs on a “slave” Spark application that is co- located with Big SQL engine • Job result flows in parallel, with local data transfer at the nodes => high throughput data flow control flow across engines control/data flow within engine
- 32. © 2017 IBM Corporation Exploit Spark from Big SQL Example: Spark Schema Discovery for JSON SELECT doc.* FROM TABLE( SYSHADOOP.EXECSPARK( class => 'DataSource', load => 'hdfs://host.port.com:8020/user/bigsql/demo.json') ) AS doc WHERE doc.language = 'English'; Structure of JSON document determined at run time Bring the best of Spark into Big SQL! − Spark-based ELT − In-Database Machine Learning − Custom analytics (ML, graph, user-defined) invoked from SELECT statement − Extend SQL with custom operations (joins, aggregates etc.) − SQL using schema on read − Cache remote tables (Spark has rich library of connectors)
- 33. © 2017 IBM Corporation Integration Aspects 1. API Integration − Invoke Spark jobs from SQL application • Polymorphic UDTFs − Query Big SQL from Spark application • Let Big SQL (as opposed to SparkSQL) process the SQL 2. Data movement − Low latency • Long running Spark application (as opposed to starting a new per job) − High throughput • Co-located workers allow us to move data locally and in-parallel
- 34. © 2017 IBM Corporation Integration with Hadoop Eco-system
- 35. © 2017 IBM Corporation Ambari Install
- 36. © 2017 IBM Corporation Customize Parameters
- 37. © 2017 IBM Corporation Installation in progress
- 38. © 2017 IBM Corporation Ambari Integration
- 39. © 2017 IBM Corporation Apache Ranger Integration Setup ACLs for access to Big SQL tables: − create, alter, analyze, load, truncate, drop, insert, select, update, and delete. Supports Ranger Audit − Big SQL access audit records written to HDFS and/or Solr
- 40. © 2017 IBM Corporation Apache Slider Apache Slider − Enables long running services (e.g. Big SQL) to integrate with YARN (similar to HBase) − Provides: • Implementation of Application Master • Monitoring of deployed applications • Component failure detection and restart capabilities • Flex API for adding/removing instances of components of already running Apache Slider does not yet have a GUI nor Ambari integration. − Big SQL operations for Slider can be executed through two methods: • Big SQL Service Actions in Ambari • Command line scripts
- 41. © 2017 IBM Corporation Big SQL + YARN Integration Dynamic Allocation / Release of Resources Big SQL Head NMNM NMNM NMNM NMNM NMNM NMNM HDFSHDFS Slider ClientSlider Client YARN Resource Manager & Scheduler YARN Resource Manager & Scheduler Big SQL AM Big SQL AM Big SQL Worker Big SQL Worker Big SQL Worker ContainerContainer YARN components YARN components Slider Components Slider Components Big SQL Components Big SQL Components Users Big SQL Worker Big SQL Worker Big SQL Worker Stopped workers release memory to YARN for other jobs Stopped workers release memory to YARN for other jobs Stopped workers release memory to YARN for other jobs Big SQL Slider package implements Slider Client APIs
- 42. © 2017 IBM Corporation Big SQL Elastic Boost – Multiple Workers per Host More Granular Elasticity Big SQL Head NMNM NMNM NMNM NMNM NMNM NMNM HDFSHDFS Slider ClientSlider Client YARN Resource Manager & Scheduler YARN Resource Manager & Scheduler Big SQL AM Big SQL AM ContainerContainer YARN components YARN components Slider Components Slider Components Big SQL Components Big SQL Components Users Big SQL Worker Big SQL Worker Big SQL Worker Big SQL Worker Big SQL Worker Big SQL Worker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker
- 43. © 2017 IBM Corporation So it’s Elastic, But Why Did We Call It Elastic Boost ? For large SMP servers (> 8 cores, 64GB memory) – multiple workers per host yields up to 50% more performance* given the same resources (memory, CPU, disk, network) − World-Record Result: Big SQL Hadoop-DS running TCP-DS queries at 100TB scale used 12 workers/host Usual constraints: − Elastic boost will result in greater memory and CPU exploitation, but bottlenecks may show up in other areas of the shared host (workers still share network, disk, etc..) − Assumes relatively balanced activation of workers across all nodes (YARN decides) − Minimum recommended worker resources (2 cores, 24GB memory) still applies. Big SQL Worker Single Worker 16 cores 96GB Memory VS. WorkerWorker WorkerWorker WorkerWorker 4 Workers @ 4 cores, 24GB Memory WorkerWorker
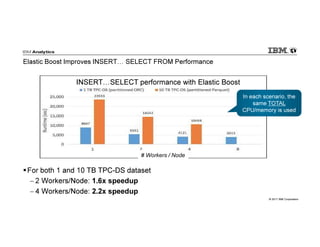
- 44. © 2017 IBM Corporation Elastic Boost Improves INSERT SELECT FROM Performance For both 1 and 10 TB TPC-DS dataset − 2 Workers/Node: 1.6x speedup − 4 Workers/Node: 2.2x speedup In each scenario, the same TOTAL CPU/memory is used In each scenario, the same TOTAL CPU/memory is used INSERT SELECT performance with Elastic Boost # Workers / Node
- 45. © 2017 IBM Corporation How do I throttle capacity for a long running service? OK, but the whole point of YARN is to share resources. There may be other Hadoop tenants running concurrently
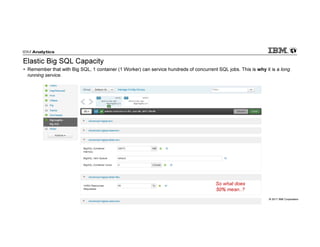
- 46. © 2017 IBM Corporation Elastic Big SQL Capacity • Remember that with Big SQL, 1 container (1 Worker) can service hundreds of concurrent SQL jobs. This is why it is a long running service. So what does 50% mean..?
- 47. © 2017 IBM Corporation What does 50% mean? YARN (not Big SQL) decides where containers/workers are started. These situations, and others, are possible. WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker Ideal WorkerWorkerWorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker Minor Skew WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker WorkerWorker Significant Skew As capacity target increases above 50%, opportunity of skew is reduced.
- 48. © 2017 IBM Corporation A Performance Study: Breaking World Records for SQL on Hadoop (Hadoop-DS) Analytics Performance
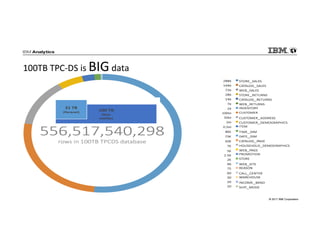
- 49. © 2017 IBM Corporation What is TPC-DS? TPC = Transaction Processing Council − Non-profit corporation (vendor independent) − Defines various industry driven database benchmarks…. DS = Decision Support − Models a multi-domain data warehouse environment for a hypothetical retailer Retail Sales Web Sales Inventory Demographics Promotions Multiple scale factors: 100GB, 300GB, 1TB, 3TB, 10TB, 30TB and 100TB 99 Pre-Defined Queries Query Classes: Reporting Ad HocIterative OLAP Data Mining
- 50. © 2017 IBM Corporation IBM First/Only to Produce Audited Benchmark Hadoop-DS (based on TPC-DS) / Oct 2014 Audited Hadoop-DS at 10TB and 30TB scale TPC Certified Auditors verified both IBM results as well as results on Cloudera Impala and Hortonworks Hive. Only IBM has ever published an audited result Prior Record Prior World Record
- 51. © 2017 IBM Corporation RUNS ALL 99 QUERIES Spark 2.x is one of the first open source options that
- 52. © 2017 IBM Corporation
- 53. © 2017 IBM Corporation IBM Leadership in Spark SQL and ML Major focus areas include Spark SQL and ML https://issues.apache.org/jira/secure/Dashboard.jspa?selectPageId=12326761 Statistics as of February 1, 2017
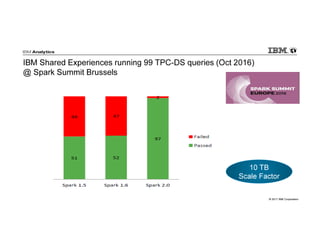
- 54. © 2017 IBM Corporation IBM Shared Experiences running 99 TPC-DS queries (Oct 2016) @ Spark Summit Brussels 10 TB Scale Factor
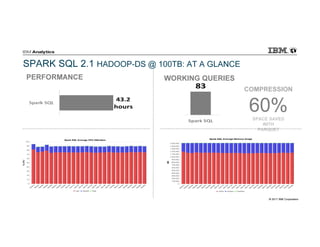
- 55. © 2017 IBM Corporation WHAT WOULD IT TAKE TO RUN 100 TB Spark 2.1 shows continued improvement . IBM delivers the most complete benchmark with 10X-100X more data
- 56. © 2017 IBM Corporation 100TB TPC-DS is BIG data
- 57. © 2017 IBM Corporation Benchmark Environment: IBM “F1” Spark SQL Cluster 28 Nodes Total (Lenovo x3640 M5) Each configured as: • 2 sockets (18 cores/socket) • 1.5 TB RAM • 8x 2TB SSD 2 Racks − 20x 2U servers per rack (42U racks) 1 Switch, 100GbE, 32 ports Mellanox SN2700
- 58. © 2017 IBM Corporation PERFORMANCE SPARK SQL 2.1 HADOOP-DS @ 100TB: AT A GLANCE WORKING QUERIES COMPRESSION 60%SPACE SAVED WITH PARQUET
- 59. © 2017 IBM Corporation WHAT CAN WE COMPARE IT TO? But is this a good result?
- 60. © 2017 IBM Corporation Big SQL also runs TPC-DS queries The following benchmark results used the same hardware as Spark SQL F1 Cluster using Big SQL v4.2.5 Technical Review
- 61. © 2017 IBM Corporation Query Compliance Through the Scale Factors SQL compliance is important because Business Intelligence tools generate standard SQL − Rewriting queries is painful and impacts productivity Spark SQL 2.1 can run all 99 TPC-DS queries but only at lower scale factors Spark SQL Failures @ 100 TB: − 12 runtime errors − 4 timeout (> 10 hours) Spark SQL Big SQL has been successfully executing all 99 queries since Oct 2014 IBM is the only vendor that has proven SQL compatibility at scale factors up to 100TB Big SQL
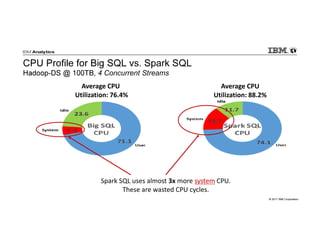
- 62. © 2017 IBM Corporation CPU Profile for Big SQL vs. Spark SQL Hadoop-DS @ 100TB, 4 Concurrent Streams Spark SQL uses almost 3x more system CPU. These are wasted CPU cycles. Average CPU Utilization: 76.4% Average CPU Utilization: 88.2%
- 63. © 2017 IBM Corporation I/O Profile for Big SQL vs. Spark SQL Hadoop-DS @ 100TB, 4 Concurrent Streams Spark SQL required 3.6X more reads 9.5X more writes Big SQL can drive peak I/O nearly 2X more
- 64. © 2017 IBM Corporation Big SQL is 3.2X faster than Spark 2.1 (4 Concurrent Streams) Big SQL @ 99 queries still outperforms Spark SQL @ 83 queries
- 65. © 2017 IBM Corporation LET’S DO THE MATH Maturity and Efficiency Matters
- 66. © 2017 IBM Corporation Maturity and Efficiency Matters – Doing the Math Spark SQL runs 3.2x longer than Big SQL – so Spark SQL actually consumes > 3x more CPU for the same workload! Spark SQL runs 3.2x longer than Big SQL – so Spark SQL actually consumes > 3x more CPU for the same workload! Average CPU Utilization: 76.4% 88.2%Average CPU Utilization: 3.2x elapsed time
- 67. © 2017 IBM Corporation Maturity and Efficiency Matters – Doing the Math Spark SQL runs 3.2x longer than Big SQL – Spark SQL is actually reading ~12x more data and writing ~30x more data. Spark SQL runs 3.2x longer than Big SQL – Spark SQL is actually reading ~12x more data and writing ~30x more data.
- 68. © 2017 IBM Corporation A LOT OF POTENTIAL And the best part, Big SQL still has
- 69. © 2017 IBM Corporation Big SQL only actively using ~ 1/3rd of memory − More memory could be assigned to bufferpools and sort space etc… − Big SQL could be even faster !!! Spark SQL is doing a better job at utilizing the available memory, but consequently has less room for improvement via tuning Big SQL Spark SQL Memory Profile for Big SQL vs. Spark SQL Hadoop-DS @ 100TB, 4 Concurrent Streams
- 70. © 2017 IBM Corporation PERFORMANCE Big SQL 3.2x faster HADOOP-DS @ 100TB: AT A GLANCE WORKING QUERIES CPU (vs Spark) Big SQL uses 3.7x less CPU I/O (vs Spark) Big SQL reads 12x less data Big SQL writes 30x less data COMPRESSION 60%SPACE SAVED WITH PARQUET AVERAGE CPU USAGE 76.4% MAX I/O THROUGHPUT: READ 4.4 GB/SEC
- 71. © 2017 IBM Corporation
- 72. © 2017 IBM Corporation “Big SQL is the Big Data Industry's best kept secret, and I'm excited that it’s now available for Hortonworks” Dr. Phil Shelley, President, DataMetica Solutions, Inc. NEW YORK, NY: September 28, 2016 – IBM today announced the availability of IBM Big SQL for the Hortonworks Data Platform (HDP). Big SQL enables high performance SQL over Hive and HBase data using rich ANSI compliant SQL. Big SQL’s advanced cost-based optimizer and MPP architecture supports high concurrency workloads by executing complex queries smarter, not harder, requiring less memory and CPU compared to other SQL solutions for Hadoop. Big SQL also eats other databases – it is the first and only SQL-on-Hadoop solution to understand commonly used SQL syntax from other products such as Oracle®, IBM DB2® and IBM Netezza®…. all at the same time – making it far easier to offload traditional data warehouse workloads. And where data can’t be moved to Hadoop, Big SQL provides federated access to popular RDBMS sources outside of Hadoop with industry-leading Fluid Query technology. All the data is then secured with role-based access control, dynamic data masking, and LDAP integrated column/row level security. The best part? All the data belongs to Hadoop. Big SQL tables are Hive tables, HBase tables, or Spark resilient distributed datasets (RDDs) and fully integrated with Hive metastore. Get more analytics out of your Hadoop cluster - Learn more at http://ibm.co/2doVifE
- 73. © 2017 IBM Corporation Put simply, IBM and Hortonworks Combined Value is Unequaled in the Market #1 Data Science Platform (Source: Gartner) #1 SQL Engine for complex, analytical workloads. Leader in On-premise and Hybrid Cloud solutions #1 Pure Open Source Hadoop Distribution 1000+ customers and 2100+ ecosystem partners Employs the original architects, developers and operators of Hadoop from Yahoo! + IBM will adopt Hortonworks Data Platform (HDP) as its core Hadoop distribution and resell HDP Hortonworks will adopt and resell IBM Data Science Experience (DSX) and IBM Big SQL
- 74. © 2017 IBM Corporation The announcement is the latest step in a partnership that began with our founding memberships in ODPi (2015). IBM and Hortonworks Co-found ODPi IBM IOP and HDP Certify for ODPi V1 IBM and Hortonworks Power partnership IBM IOP and HDP Certify for ODPi V2 201720162015 Big SQL Certified for both IOP and HDP Today’s Announcement ODPi = Open Data Platform initiative. For more information, visit odpi.org
- 75. © 2017 IBM Corporation Questions? https://developer.ibm.com/hadoop/category/bigsql/
- 76. © 2017 IBM Corporation Thank you!