

































![Common Transformations and Actions
Basic RDDs
We will begin by describing what transformations and actions we can perform on all
RDDs regardless of the data.
Element-wise transformations
• The two most common transformations you will likely be using are map() and filter() .
• The map() transformation takes in a function and applies it to each element in the
RDD with the result of the function being the new value of each element in the
resulting RDD.
• The filter() transformation takes in a function and returns an RDD that only has
elements that pass the filter() function.
• We can use map() to do any number of things, from fetching the website associated
with each URL in our collection to just squaring the numbers.
• It is useful to note that map()’s return type does not have to be the same as its input
type, so if we had an RDD String and our map() function were to parse the strings and
return a Double, our input RDD type would be RDD[String] and the resulting RDD type
would be RDD[Double].](https://image.slidesharecdn.com/module-4session1-240219154640-9a27f2d5/85/Big_data_analytics_NoSql_Module-4_Session-35-320.jpg)



Big_data_analytics_NoSql_Module-4_Session
- 1. MODULE - 4
- 2. Introduction to Data Analysis with Spark • Apache Spark is an open-source cluster computing framework for real-time processing. • It is of the most successful projects in the Apache Software Foundation. • On the speed side, Spark extends the popular MapReduce model to efficiently support more types of computations, including interactive queries and stream processing. • Speed is important in processing large datasets, as it means the difference between exploring data interactively and waiting minutes or hours. • One of the main features Spark offers for speed is the ability to run computations in memory, but the system is also more efficient than MapReduce for complex applications running on disk.
- 3. Why Spark when Hadoop is already there? • Hadoop is based on the concept of batch processing where the processing happens of blocks of data that have already been stored over a period of time. • At the time, Hadoop broke all the expectations with the revolutionary MapReduce framework in 2005. • Hadoop MapReduce is the best framework for processing data in batches. • This went on until 2014, till Spark overtook Hadoop. • The USP for Spark was that it could process data in real time and was about 100 times faster than Hadoop MapReduce in batch processing large data sets.
- 5. • In Spark, processing can take place in real-time. This real-time processing power in Spark helps us to solve the use cases of Real Time Analytics • Alongside this, Spark is also able to do batch processing 100 times faster than that of Hadoop MapReduce (Processing framework in Apache Hadoop). • Apache Spark works well for smaller data sets that can all fit into a server's RAM. • Hadoop is more cost effective processing massive data sets.
- 6. Apache Spark Vs Hadoop SL NO Hadoop Apache Spark 1 Hadoop is an open source framework which uses a MapReduce algorithm. Spark is lightning fast cluster computing technology, which extends the MapReduce model to efficiently use with more type of computations 2 Hadoop’s MapReduce model reads and writes from a disk, thus slow down the processing speed. Spark reduces the number of read/write cycles to disk and store intermediate data in-memory, hence faster- processing speed. 3 Hadoop is designed to handle batch processing efficiently Spark is designed to handle real-time data efficiently. 4 Hadoop is a high latency computing framework, which does not have an interactive mode. Spark is a low latency computing and can process data interactively. 5 With Hadoop MapReduce, a developer can only process data in batch mode only Spark can process real-time data, from real time events like twitter, facebook 6 Hadoop is a cheaper option available while comparing it in terms of cost. Spark requires a lot of RAM to run in- memory, thus increasing the cluster and hence cost. 7 Written in Java Written in Scala
- 8. Spark Core • Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. • Spark Core is also home to the API that defines resilient distributed datasets (RDDs), which are Spark’s main programming abstraction. • RDDs represent a collection of items distributed across many compute nodes that can be manipulated in parallel. • Spark Core provides many APIs for building and manipulating these collections
- 9. Spark SQL • Spark SQL is Spark’s package for working with structured data. • It allows querying datavia SQL as well as the Apache Hive variant of SQL — called the Hive Query Language(HQL) — and it supports many sources of data, including Hive tables, Parquet, and JSON. • Beyond providing a SQL interface to Spark, Spark SQL allows developers to intermix SQL queries with the programmatic data manipulations supported by RDDs in Python,Java, and Scala, all within a single application, thus combining SQL with complex analytics
- 10. Spark Streaming • Spark Streaming is a Spark component that enables processing of live streams of data. • Examples of data streams include logfiles generated by production web servers, or queuesof messages containing status updates posted by users of a web service.
- 11. MLlib • Spark comes with a library containing common machine learning (ML) functionality, called MLlib. • MLlib provides multiple types of machine learning algorithms, including classification, regression, clustering, and collaborative filtering, as well as supporting functionality such as model evaluation and data import.
- 12. GraphX • GraphX is a library for manipulating graphs (e.g., a social network’s friend graph) and performing graph-parallel computations. • Like Spark Streaming and Spark SQL, GraphX extends the Spark RDD API, allowing us to create a directed graph with arbitrary properties attached to each vertex and edge. • GraphX also provides various operators for manipulating graphs (e.g., subgraph and mapVertices) and a library of common graph algorithms (e.g., PageRank and triangle counting).
- 13. Cluster Managers • Under the hood, Spark is designed to efficiently scale up from one to many thousands of compute nodes. • To achieve this while maximizing flexibility, Spark can run over a variety of cluster managers, including Hadoop YARN, Apache Mesos, and a simple cluster manager included in Spark itself called the Standalone Scheduler.
- 14. Who Uses Spark, and for What? • Since Spark is a general-purpose framework for cluster computing, it is used for a diverse range of applications. • Two groups of users- data scientists and engineers. • -Data Science Tasks -Data Processing Applications
- 15. A Brief History of Spark Spark is an open source project that has been built and is maintained by a thriving and diverse community of developers. If you or your organization are trying Spark for the first time, you might be interested in the history of the project. Spark started in 2009 as a research project in the UC Berkeley RAD Lab, later to become the AMPLab. The researchers in the lab had previously been working on Hadoop MapReduce, and observed that MapReduce was inefficient for iterative and interactive computing jobs. Thus, from the beginning, Spark was designed to be fast for interactive queries and iterative algorithms, bringing in ideas like support for in-memory storage and efficient fault recovery. 15
- 16. Spark Versions and Releases • Since its creation, Spark has been a very active project and community, with the number of contributors growing with each release. • Spark 1.0 had over 100 individual contributors. Though the level of activity has rapidly grown, the community continues to release updated versions of Spark on a regular schedule. • Spark-versions
- 17. Storage Layers for Spark • Spark can create distributed datasets from any file stored in the Hadoop distributed filesystem (HDFS) or other storage systems supported by the Hadoop APIs (including your local filesystem, Amazon S3, Cassandra, Hive, HBase, etc.). • It’s important to remember that Spark does not require Hadoop; it simply has support for storage systems implementing the Hadoop APIs. Spark supports text files, Sequence Files, Avro, Parquet, and any other Hadoop InputFormat.
- 18. Programming with RDDs • An RDD is simply a distributed collection of elements. • In Spark all work is expressed as either creating new RDDs, transforming existing RDDs, or calling operations on RDDs to compute a result. • Under the hood, Spark automatically distributes the data contained in RDDs across your cluster and parallelizes the operations you perform on them.
- 20. RDD Basics • An RDD in Spark is simply an immutable distributed collection of objects. • Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes. • Users create RDDs in two ways: by loading an external dataset, or by distributing a collection of objects (e.g., a list or set) in their driver program.
- 21. RDD Basics • Once created, RDDs offer two types of operations: transformations and actions. • Transformations construct a new RDD from a previous one. • For example, one common transformation is filtering data that matches a predicate. • In our text file example, we can use this to create a new RDD holding just the strings that contain the word Python, as shown in Example 3-2. • Actions, on the other hand, compute a result based on an RDD, and either return it to the driver program or save it to an external storage system (e.g., HDFS). • One example of an action we called earlier is first(), which returns the first element in an RDD and is demonstrated in Example 3-3.
- 22. RDD Basics • Transformations and actions are different because of the way Spark computes RDDs. • Although you can define new RDDs any time, Spark computes them only in a lazy fashion — that is, the first time they are used in an action. • This approach makes a lot of sense when you are working with Big Data. • For instance, in Example 3-2 and Example 3-3, we defined a text file and then filtered the lines that include Python. • If Spark were to load and store all the lines in the file as soon as we wrote lines = sc.textFile(…), it would waste a lot of storage space, given that we then immediately filter out many lines. • Instead, once Spark sees the whole chain of transformations, it can compute just the data needed for its result. • In fact, for the first() action, Spark scans the file only until it finds the first matching line; it doesn’t even read the whole file • Spark’s RDDs are by default recomputed each time you run an action on them.
- 23. RDD Basics • If you would like to reuse an RDD in multiple actions, you can ask Spark to persist it using RDD.persist(). • In practice, we will often use persist() to load a subset of your data into memory and query it repeatedly. • For example, if we knew that we wanted to compute multiple results about the README lines that contain Python, we could write the script as shown below. • The behavior of not persisting by default makes a lot of sense for big datasets: if you will not reuse the RDD, there’s no reason to waste storage space when Spark could instead stream through the data once and just compute the result.
- 24. RDD Basics To summarize, every Spark program and shell session will work as follows: 1. Create some input RDDs from external data. 2. Transform them to define new RDDs using transformations like filter(). 3. Ask Spark to persist() any intermediate RDDs that will need to be reused. 4. Launch actions such as count() and first() to kick off a parallel computation, which is then optimized and executed by Spark.
- 25. Creating RDDs • Spark provides two ways to create RDDs: loading an external dataset and parallelizing a collection in your driver program. • The simplest way to create RDDs is to take an existing collection in your program and pass it to SparkContext’s parallelize() method, as shown in Examples 3-5 through 3-7.
- 26. RDD Operations • As we’ve discussed, RDDs support two types of operations: transformations and actions. • Transformations are operations on RDDs that return a new RDD, such as map() and filter(). • Actions are operations that return a result to the driver program or write it to storage, and kick off a computation, such as count() and first(). • Spark treats transformations and actions very differently, so understanding which type of operation you are performing will be important. • If you are ever confused whether a given function is a transformation or an action, you can look at its return type: transformations return RDDs, whereas actions return some other data type.
- 27. Transformations • Transformations are operations on RDDs that return a new RDD. • As discussed in “Lazy Evaluation”, transformed RDDs are computed lazily, only when you use them in an action. • Many transformations are element-wise; that is, they work on one element at a time; but this is not true for all transformations. • As an example, suppose that we have a logfile, log.txt, with a number of messages, and we want to select only the error messages. We can use the filter() transformation seen before.
- 28. Transformations • The filter() operation does not mutate the existing input RDD. • Instead, it returns a pointer to an entirely new RDD. • inputRDD can still be reused later in the program — for instance, to search for other words. • Let’s use inputRDD again to search for lines with the word warning in them. • Then, we’ll use another transformation, union(), to print out the number of lines that contained either error or warning. • union() is a bit different than filter(), in that it operates on two RDDs instead of one. • Transformations can actually operate on any number of input RDDs.
- 29. Transformations • As you derive new RDDs from each other using transformations, Spark keeps track of the set of dependencies between different RDDs, called the lineage graph. • It uses this information to compute each RDD on demand and to recover lost data if part of a persistent RDD is lost
- 30. Actions • Actions are the second type of RDD operation. • They are the operations that return a final value to the driver program or write data to an external storage system. • Actions force the evaluation of the transformations required for the RDD they were called on, since they need to actually produce output.
- 31. Actions • In this example, we used take() to retrieve a small number of elements in the RDD at the driver program. • We then iterate over them locally to print out information at the driver. • RDDs also have a collect() function to retrieve the entire RDD. • This can be useful if your program filters RDDs down to a very small size and you’d like to deal with it locally. • Entire dataset must fit in memory on a single machine to use collect() on it, so collect() shouldn’t be used on large datasets. • In most cases RDDs can’t just be collect()ed to the driver because they are too large. • In these cases, it’s common to write data out to a distributed storage system such as HDFS or Amazon S3. • You can save the contents of an RDD using the saveAsTextFile() action, saveAsSequenceFile(), or any of a number of actions for various built-in formats.
- 32. Passing Functions to Spark • Most of Spark’s transformations, and some of its actions, depend on passing in functions that are used by Spark to compute data. In Python, we have three options for passing functions into Spark. • For shorter functions, we can pass in lambda expressions. Alternatively, we can pass in top-level functions, or locally defined functions. Example 3-18. Passing functions in Python word = rdd.filter(lambda s: “error” in s) def containsError(s): return “error” in s word = rdd.filter(containsError)
- 33. Passing Functions to Spark • One issue to watch out for when passing functions is inadvertently serializing the object containing the function. • When you pass a function that is the member of an object, or contains references to fields in an object (e.g., self.field), Spark sends the entire object to worker nodes, which can be much larger than the bit of information you need (see Example 3-19). • Sometimes this can also cause your program to fail, if your class contains objects that Python can’t figure out how to pickle.
- 34. Passing Functions to Spark • Instead, just extract the fields you need from your object into a local variable and pass that in
- 35. Common Transformations and Actions Basic RDDs We will begin by describing what transformations and actions we can perform on all RDDs regardless of the data. Element-wise transformations • The two most common transformations you will likely be using are map() and filter() . • The map() transformation takes in a function and applies it to each element in the RDD with the result of the function being the new value of each element in the resulting RDD. • The filter() transformation takes in a function and returns an RDD that only has elements that pass the filter() function. • We can use map() to do any number of things, from fetching the website associated with each URL in our collection to just squaring the numbers. • It is useful to note that map()’s return type does not have to be the same as its input type, so if we had an RDD String and our map() function were to parse the strings and return a Double, our input RDD type would be RDD[String] and the resulting RDD type would be RDD[Double].
- 36. Common Transformations and Actions
- 37. Common Transformations and Actions
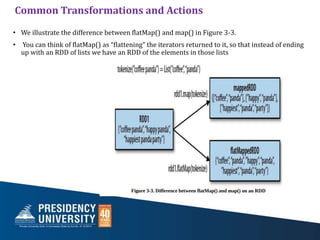
- 38. Common Transformations and Actions • Sometimes we want to produce multiple output elements for each input element. • The operation to do this is called flatMap(). As with map(), the function we provide to flatMap() is called individually for each element in our input RDD. • Instead of returning a single element, we return an iterator with our return values. • Rather than producing an RDD of iterators, we get back an RDD that consists of the elements from all of the iterators. A simple usage of flatMap() is splitting up an input string into words, as shown in Examples 3-29 through 3-31.
- 39. • We illustrate the difference between flatMap() and map() in Figure 3-3. • You can think of flatMap() as “flattening” the iterators returned to it, so that instead of ending up with an RDD of lists we have an RDD of the elements in those lists Common Transformations and Actions