Blosc: Sending Data from Memory to CPU (and back) Faster than Memcpy by Francesc Alted
2 likes3,200 views

Blosc is a library that can compress and decompress data faster than memcpy by taking advantage of the large performance gap between CPU and memory. It works by dividing data into blocks that fit CPU caches, using multithreading, and SIMD instructions. Real-world tests show Blosc can compress genomics data 15-40x smaller with similar access speeds. Blosc is used in libraries like Bloscpack and BLZ to provide efficient compressed containers for large NumPy and other datasets while maintaining close to uncompressed performance.




































Blosc: Sending Data from Memory to CPU (and back) Faster than Memcpy by Francesc Alted
- 1. Blosc Sending data from memory to CPU (and back) faster than memcpy() Francesc Alted Software Architect PyData London 2014 February 22, 2014
- 2. About Me • I am the creator of tools like PyTables, Blosc, BLZ and maintainer of Numexpr. • I learnt the hard way that ‘premature optimization is the root of all evil’. • Now I only humbly try to optimize if I really need to and I just hope that Blosc is not an example of ‘premature optimization’.
- 3. About Continuum Analytics • Develop new ways on how data is stored, computed, and visualized. • Provide open technologies for data integration on a massive scale. • Provide software tools, training, and integration/consulting services to corporate, government, and educational clients worldwide.
- 4. Overview • Compressing faster than memcpy(). Really? • How that can be? (The ‘Starving CPU’ problem) • How Blosc works. • Being faster than memcpy() means that my programs would actually run faster?
- 6. Interactive Session Starts • If you want to experiment with Blosc in your own machine: http://www.blosc.org/materials/PyData- London-2014.tar.gz • blosc (blz too for later on) is required (both are included in conda repository).
- 7. Open Questions We have seen that, sometimes, Blosc can actually be faster than memcpy(). Now: 1. If compression takes way more CPU than memcpy(), why Blosc can beat it? 2. Does this mean that Blosc can actually accelerate computations in real scenarios?
- 8. The Starving CPU Problem “Across the industry, today’s chips are largely able to execute code faster than we can feed them with instructions and data.” ! – Richard Sites, after his article “It’sThe Memory, Stupid!”, Microprocessor Report, 10(10),1996
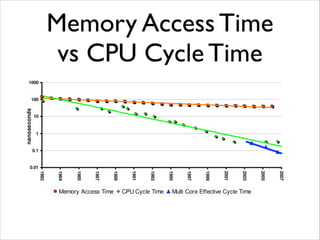
- 9. Memory Access Time vs CPU Cycle Time
- 10. Book in 2009
- 11. The Status of CPU Starvation in 2014 • Memory latency (~10 ns) is much slower (between 100x and 250x) than processors. • Memory bandwidth (~15 GB/s) is improving at a better rate than memory latency, but it is also slower than processors (between 30x and 100x).
- 13. Blosc: (de)compressing faster than memcpy() Transmission + decompression faster than direct transfer?
- 14. Taking Advantage of Memory-CPU Gap • Blosc is meant to discover redundancy in data as fast as possible. • It comes with a series of fast compressors: BloscLZ, LZ4, Snappy, LZ4HC and Zlib • Blosc is meant for speed, not for high compression ratios.
- 15. Blosc Is All About Efficiency • Uses data blocks that fit in L1 or L2 caches (better speed, less compression ratios). • Uses multithreading by default. • The shuffle filter uses SSE2 instructions in modern Intel and AMD processors.
- 17. Suffling: Improving the Compression Ratio The shuffling algorithm does not actually compress the data; it rather changes the byte order in the data stream:
- 18. Shuffling Caveat • Shuffling usually produces better compression ratios with numerical data, except when it does not. • If you mind about the compression ratio, it is worth to deactivate it and check (it is active by default). • Will see an example on real data later on.
- 19. Blosc Performance: Laptop back in 2005
- 20. Blosc Performance: Desktop Computer in 2012
- 21. First Answer for Open Questions • Blosc data blocking optimizes the cache behavior during memory access. • Additionally, it uses multithreading and SIMD instructions. • Add these to the Starved CPU problem and you have a good hint now on why Blosc can beat memcpy().
- 22. How Compression Works With Real Data?
- 23. The Need for Compression • Compression allows to store more data using the same storage capacity. • Sure, it uses more CPU time to compress/ decompress data. • But, that actually means using more wall clock time?
- 24. The Need for a Compressed Container • A compressed container is meant to store data in compressed state and transparently deliver it uncompressed. • That means that the user only perceives that her dataset takes less memory. • Only less space? What about data access speed?
- 25. Source: Howison, M. High-throughput compression of FASTQ data with SeqDB. IEEE Transactions on Computational Biology and Bioinformatics. Example of How Blosc Accelerates Genomics I/O: SeqDB (backed by Blosc)
- 26. Bloscpack (I) • Command line interface and serialization format for Blosc: ! $ blpk c data.dat # compress $ blpk d data.dat.blp # decompress
- 27. Bloscpack (II) • Very convenient for easily serializing your in-memory NumPy datasets: >>> a = np.linspace(0, 1, 3e8) >>> print a.size, a.dtype 300000000 float64 >>> bp.pack_ndarray_file(a, 'a.blp') >>> b = bp.unpack_ndarray_file('a.blp') >>> (a == b).all() True
- 28. Yet Another Example: BLZ • BLZ is a both a format and library that has been designed as an efficient data container for Big Data. • Blosc and Bloscpack are at the heart of it in order to achieve high-speed compression/ decompression. • BLZ is one of the backends supported by our nascent Blaze library.
- 29. Appending Data in Large NumPy Objects Copy! New memory allocation array to be enlarged final array object new data to append • Normally a realloc() syscall will not succeed • Both memory areas have to exist simultaneously
- 30. Contiguous vs Chunked NumPy container Contiguous memory BLZ container chunk 1 chunk 2 Discontiguous memory chunk N ...
- 31. Appending data in BLZ compress new chunk array to be enlarged final array object new data to append Only a small amount of data has to be compressed X chunk 1 chunk 2 chunk 1 chunk 2
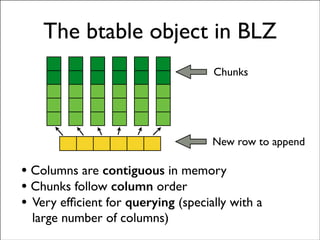
- 32. The btable object in BLZ New row to append • Columns are contiguous in memory • Chunks follow column order • Very efficient for querying (specially with a large number of columns) Chunks
- 33. Second Interactive Session: BLZ and Blosc on a Real Dataset
- 34. Second Hint for Open Questions Blosc usage in BLZ means not only less storage usage (~15x-40x reduction for the real life data shown), but almost the same access time to the data (~2x-10x slowdown). (Still need to address implementation details for getting better performance)
- 35. Summary • Blosc, being able to transfer data faster than memcpy(), has enormous implications on data management. • It is well suited not only for saving memory, but for allowing close performance to typical uncompressed data containers. • It works well not only for synthetic data, but also for real-life datasets.
- 36. References • Blosc: http://www.blosc.org • Bloscpack: https://github.com/Blosc/bloscpack • BLZ: http://blz.pydata.org
- 37. “Across the industry, today’s chips are largely able to execute code faster than we can feed them with instructions and data. There are no longer performance bottlenecks in the floating-point multiplier or in having only a single integer unit. The real design action is in memory subsystems— caches, buses, bandwidth, and latency.” ! “Over the coming decade, memory subsystem design will be the only important design issue for microprocessors.” ! – Richard Sites, after his article “It’sThe Memory, Stupid!”, Microprocessor Report, 10(10),1996 “Over this decade (2010-2020), memory subsystem optimization will be (almost) the only important design issue for improving performance.” – Me :)
- 38. Thank you!