Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark
4 likes2,721 views

The presentation by Tim Hunter at the Databricks Spark Meetup discusses deep learning at scale using Apache Spark, highlighting its potential and current limitations in industry adoption. It introduces Deep Learning Pipelines, an open-source library designed for ease of use and integration with Spark, catering primarily to Python users while aiming to simplify the deep learning workflow from data loading to model evaluation. Future developments include support for more backends and improved functionalities such as distributed training and text featurization.






























![Transfer Learning as a Pipeline
31put your #assignedhashtag here by setting the
featurizer = DeepImageFeaturizer(inputCol="image",
outputCol="features",
modelName="InceptionV3")
lr = LogisticRegression(labelCol="label")
p = Pipeline(stages=[featurizer, lr])
p_model = p.fit(train_df)](https://image.slidesharecdn.com/18-03-14meetupdeeplearningpipelines-180316185245/85/Build-Scale-and-Deploy-Deep-Learning-Pipelines-Using-Apache-Spark-31-320.jpg)






![39
Keras Estimator in Model Selection
estimator = KerasImageFileEstimator(
kerasOptimizer=“adam“,
kerasLoss=“categorical_crossentropy“)
paramGrid = ( ParamGridBuilder()
.addGrid(kerasFitParams=[{“batch_size“:100}, {“batch_size“:200}])
.addGrid(modelFile=[model1, model2]) )
cv = CrossValidator(estimator=estimator,
estimatorParamMaps=paramGrid,
evaluator=BinaryClassificationEvaluator(),
numFolds=3)
best_model = cv.fit(train_df)](https://image.slidesharecdn.com/18-03-14meetupdeeplearningpipelines-180316185245/85/Build-Scale-and-Deploy-Deep-Learning-Pipelines-Using-Apache-Spark-39-320.jpg)











Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark
- 1. Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark Tim Hunter, Databricks Spark Meetup London, March 2018
- 2. About Me Tim Hunter • Software engineer @ Databricks • Ph.D. from UC Berkeley in Machine Learning • Very early Spark user (Spark 0.0.2) • Co-creator of GraphFrames, TensorFrames, Joint work with Sue Ann Hong
- 3. TEAM About Databricks Started Spark project (now Apache Spark) at UC Berkeley in 2009 PRODUCT Unified Analytics Platform MISSION Making Big Data Simple Try for free today. databricks.com
- 4. This talk • Deep Learning at scale: current state • Deep Learning Pipelines: the vision • End-to-end workflow with DL Pipelines • Future
- 5. Deep Learning at Scale : current state 5put your #assignedhashtag here by setting the
- 6. What is Deep Learning? • A set of machine learning techniques that use layers that transform numerical inputs • Classification • Regression • Arbitrary mapping • Popular in the 80’s as Neural Networks • Recently came back thanks to advances in data collection, computation techniques, and hardware. t
- 7. Success of Deep Learning Tremendous success for applications with complex data • AlphaGo • Image interpretation • Automatic translation • Speech recognition
- 8. But requires a lot of effort • No exact science around deep learning • Success requires many engineer-hours • Low level APIs with steep learning curve • Not well integrated with other enterprise tools • Tedious to distribute computations
- 9. What does Spark offer? Very little in Apache Spark MLlib itself (multilayer perceptron) Many Spark packages Integrations with existing DL libraries • Deep Learning Pipelines (from Databricks) • Caffe (CaffeOnSpark) • Keras (Elephas) • mxnet • Paddle • TensorFlow (TensorFlow on Spark, TensorFrames) • CNTK (mmlspark) Implementations of DL on Spark • BigDL • DeepDist • DeepLearning4J • MLlib • SparkCL • SparkNet
- 10. Deep Learning in industry • Currently limited adoption • Huge potential beyond the industrial giants • How do we accelerate the road to massive availability?
- 12. Deep Learning Pipelines: Deep Learning with Simplicity • Open-source Databricks library • Focuses on ease of use and integration • without sacrificing performance • Primary language: Python • Uses Apache Spark for scaling out common tasks • Integrates with MLlib Pipelines to capture the ML workflow concisely s
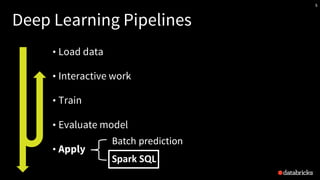
- 13. A typical Deep Learning workflow • Load data (images, text, time series, …) • Interactive work • Train • Select an architecture for a neural network • Optimize the weights of the NN • Evaluate results, potentially re-train • Apply: • Pass the data through the NN to produce new features or output Load data Interactive work Train Evaluate Apply
- 14. A typical Deep Learning workflow Load data Interactive work Train Evaluate Apply • Image loading in Spark • Distributed batch prediction • Deploying models in SQL • Transfer learning • Distributed tuning • Pre-trained models
- 15. End-to-End Workflow with Deep Learning Pipelines 15put your #assignedhashtag here by setting the
- 16. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply t
- 17. Built-in support in Spark • In Spark 2.3 • Collaboration with Microsoft • ImageSchema, reader, conversion functions to/from numpy arrays • Most of the tools we’ll describe work on ImageSchema columns images = spark.readImages(img_dir, recursive = True, sampleRatio = 0.1)
- 18. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply
- 19. Applying popular models • Popular pre-trained models accessible through MLlib Transformers predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels", modelName="InceptionV3") predictions_df = predictor.transform(image_df)
- 20. Applying popular models predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels", modelName="InceptionV3") predictions_df = predictor.transform(image_df)
- 21. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Hyperparameter tuning Transfer learning s
- 22. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Hyperparameter tuning Transfer learning
- 23. Transfer learning • Pre-trained models may not be directly applicable • New domain, e.g. shoes • Training from scratch requires • Enormous amounts of data • A lot of compute resources & time • Idea: intermediate representations learned for one task may be useful for other related tasks
- 24. Transfer Learning SoftMax GIANT PANDA 0.9 RACCOON 0.05 RED PANDA 0.01 …
- 28. MLlib Pipelines primer • MLlib: the machine learning library included with Spark • Transformer • Takes in a Spark dataframe • Returns a Spark dataframe with new column(s) containing “transformed” data • e.g. a Model is a Transformer • Estimator • A learning algorithm, e.g. lr = LogisticRegression() • Produces a Model via lr.fit() • Pipeline: a sequence of Transformers and Estimators
- 29. Transfer Learning as a Pipeline ClassifierDeepImageFeaturizer Rose / Daisy
- 30. Transfer Learning as a Pipeline DeepImageFeaturizer Image Loading Preprocessing Logistic Regression MLlib Pipeline
- 31. Transfer Learning as a Pipeline 31put your #assignedhashtag here by setting the featurizer = DeepImageFeaturizer(inputCol="image", outputCol="features", modelName="InceptionV3") lr = LogisticRegression(labelCol="label") p = Pipeline(stages=[featurizer, lr]) p_model = p.fit(train_df)
- 32. Transfer Learning • Usually for classification tasks • Similar task, new domain • But other forms of learning leveraging learned representations can be loosely considered transfer learning
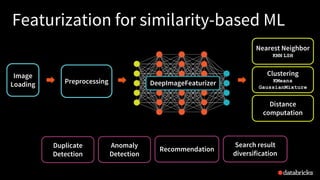
- 34. Featurization for similarity-based ML DeepImageFeaturizer Image Loading Preprocessing Logistic Regression
- 35. Featurization for similarity-based ML DeepImageFeaturizer Image Loading Preprocessing Clustering KMeans GaussianMixture Nearest Neighbor KNN LSH Distance computation
- 36. Featurization for similarity-based ML DeepImageFeaturizer Image Loading Preprocessing Clustering KMeans GaussianMixture Nearest Neighbor KNN LSH Distance computation Duplicate Detection Recommendation Anomaly Detection Search result diversification
- 37. Keras 37 model = Sequential() model.add(Dense(32, input_dim=784)) model.add(Activation('relu')) • A popular, declarative interface to build DL models • High level, expressive API in python • Executes on TensorFlow, Theano, CNTK
- 38. model = Sequential() model.add(...) model.save(model_filename) estimator = KerasImageFileEstimator( kerasOptimizer=“adam“, kerasLoss=“categorical_crossentropy“, kerasFitParams={“batch_size“:100}, modelFile=model_filename) model = model.fit(dataframe) 38 Keras Estimator
- 39. 39 Keras Estimator in Model Selection estimator = KerasImageFileEstimator( kerasOptimizer=“adam“, kerasLoss=“categorical_crossentropy“) paramGrid = ( ParamGridBuilder() .addGrid(kerasFitParams=[{“batch_size“:100}, {“batch_size“:200}]) .addGrid(modelFile=[model1, model2]) ) cv = CrossValidator(estimator=estimator, estimatorParamMaps=paramGrid, evaluator=BinaryClassificationEvaluator(), numFolds=3) best_model = cv.fit(train_df)
- 40. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply
- 41. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Spark SQL Batch prediction s
- 42. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Spark SQL Batch prediction
- 43. Batch prediction as an MLlib Transformer • Recall a model is a Transformer in MLlib predictor = XXTransformer(inputCol="image", outputCol=”predictions", modelSpecification={…}) predictions = predictor.transform(test_df)
- 44. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Spark SQL Batch prediction s
- 45. Shipping predictors in SQL Take a trained model / Pipeline, register a SQL UDF usable by anyone in the organization In Spark SQL: registerKerasUDF(”my_object_recognition_function", keras_model_file="/mymodels/007model.h5") select image, my_object_recognition_function(image) as objects from traffic_imgs This means you can apply deep learning models in streaming!
- 46. Deep Learning Pipelines : Future In progress • Scala API for DeepImageFeaturizer • Text featurization (embeddings) • TFTransformer for arbitrary vectors Future • Distributed training • Support for more backends, e.g. MXNet, PyTorch, BigDL
- 47. Deep Learning without Deep Pockets • Simple API for Deep Learning, integrated with MLlib • Scales common tasks with transformers and estimators • Embeds Deep Learning models in MLlib and SparkSQL • Check out https://github.com/databricks/spark-deep- learning !
- 48. Resources Blog posts & webinars (http://databricks.com/blog) • Deep Learning Pipelines • GPU acceleration in Databricks • BigDL on Databricks • Deep Learning and Apache Spark Docs for Deep Learning on Databricks (http://docs.databricks.com) • Getting started • Deep Learning Pipelines Example • Spark integration
- 49. 49 WWW.DATABRICKS.COM/SPARKAISUMMIT DATE: June 4-6, 2018 LOCATION: San Francisco - Moscone TRACKS: Artificial Intelligence, Spark Use Cases, Enterprise, Productionizing ML, Deep Learning, Hardware in the Cloud ATTENDEES: 4000+ Data Scientists, Data Engineers, Analysts, & VP/CxOs
- 51. Thank You! Questions? Happy Sparking & Deep Learning!