Building a SIMD Supported Vectorized Native Engine for Spark SQL
3 likes898 views

The document discusses the development of a vectorized native SQL engine for Spark, highlighting issues with the current row-based Spark SQL engine, such as challenges with SIMD optimizations and high GC overhead. It proposes a columnar-based design utilizing Arrow format, optimizing performance through native code execution and LLVM code generation. Key features include native memory management, efficient columnar data processing, and integration with various data sources, emphasizing ongoing development and open-source availability.













![ColumnarCondProjection
Columnar Projector & Filter
▪ LLVM IR based execution w/ AVX optimized
code
▪ Based on Arrow Gandiva, extended with
more functions
▪ Combined filter & projection into
CondProjector
▪ ColumnarBatch based execution
Scan B
Filter
ColumnarExchange
Projection
Example:
If (Field_A + Field_B + Field_C) as Field_new > Field_D
output [Field_new, Field_A, Field_B, Field_C, Field_D]
LLVM
IR
One call](https://image.slidesharecdn.com/116zhouxue-201129183615/85/Building-a-SIMD-Supported-Vectorized-Native-Engine-for-Spark-SQL-15-320.jpg)






![Memory Management
SparkTaskMemoryManager ArrowAllocationManager
Native MemoryDirect MemoryJVM Memory
[java] Spark.TaskMemoryManager [Java] arrow.AllocationManager [cpp] arrow::MemoryPool
register
grant
spill
Data
Source
Column
Project
Column
Sort
Column
Shuffle
Column
Reader
Native
Memory
Native
Memory
Direct
Memory
Direct
Memory
Direct
Memory
Column
To Row
JVM
Memory
Row
TakeOrdered
AndProject
JVM
Memory
Column
BHJ
Native
Memory
release release release release release release
Data
retain hashMap](https://image.slidesharecdn.com/116zhouxue-201129183615/85/Building-a-SIMD-Supported-Vectorized-Native-Engine-for-Spark-SQL-22-320.jpg)






Building a SIMD Supported Vectorized Native Engine for Spark SQL
- 1. Building a SIMD supported vectorized native engine for Spark SQL Chendi Xue([email protected]), Software Engineer Yuan Zhou([email protected]), Software Engineer Intel Corp
- 2. Agenda ▪ Native SQL Engine Introduction ▪ Native SQL Engine Design ▪ Columnar Data Source ▪ Columnar Shuffle ▪ Columnar Compute ▪ Memory Management ▪ Summary
- 3. Motivations for Native SQL Engine • Issue of current Spark SQL Engine: ▪ Internal row based, difficult to use SIMD optimizations ▪ High GC Overhead under low memory ▪ JIT code quality relies on JVM, hard to tune ▪ High overhead of integration with other native library
- 4. Proposed Solution Issue of current Spark SQL Engine: ▪ Internal row based, not possible to use SIMD → Columnar-based Arrow Format ▪ High GC Overhead under low memory → native codes for core compute instead of java ▪ JIT code quality relies on JVM, hard to tune → cpp / llvm / assembly code generation ▪ High overhead of integration with other native library → Lightweighted JNI based call framework Source: https://www.slideshare.net/dremio/apache-arrow-an-overview
- 5. Native SQL Engine Layers Physical Plan Execution Columnar PluginJVM SQL Engine Row Column Conversion Operator strategy (Cost / Support ) Spark Application SQL Python APP Java/Scala APP R APP Native Arrow Data Source ColumnarCompute Memory Management UDF Cache Scheduler DAOS / HDFS / S3 / KUDU / LOCALFS / … Parquet / ORC / CSV / JASON / … Query Plan Optimization ColumnarRules ColumnarCollapseRules ColumnarAQERules WSCG join/sort/aggr/proj/… PUSHDOWN Native Compute JNI WRAPPER Native Shuffle LLVM Gandiva CPP Code Generator pre- compiled kernels Spark Compatible Partition Streamer / Compressed Serialization Optimal Batch Memory Manage / Register • A standard columnar data format as basic data format • Data keeps on off-heap, data operations offload to highly optimized native library
- 6. Data Format Row RDD Column RDD Optimal Column RDD iter iter next() iter • Auto split and coalesce • Tunable batch size next() next() next()
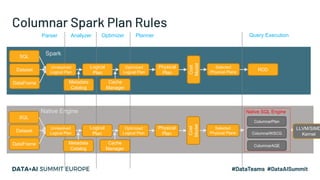
- 7. Columnar Spark Plan Rules Parser Analyzer Optimizer Planner Query Execution SQL Dataset DataFrame Unresolved Logical Plan Logical Plan Optimized Logical Plan Physical Plan Selected Physical Plans RDD Cost Model Metadata Catalog Cache Manager Spark Native Engine SQL Dataset DataFrame Unresolved Logical Plan Logical Plan Optimized Logical Plan Physical Plan Selected Physical Plans Cost Model Metadata Catalog Cache Manager ColumnarAQE Native SQL Engine ColumnarPlan ColumnarWSCG LLVM/SIMD Kernel
- 8. Columnar Whole Stage Codegen JVM Native Stage1 Evaluate Parquet Read Filter Columnar Shuffle Columnar Exchange operator Columnar Shuffle Stage2 Evaluate Parquet Read Hash Join Aggregate Columnar Exchange operator Columnar Aggregate Aggregate JVM Native Stage1 Evaluate Parquet Read Gandiva Filter Columnar Shuffle Columnar Exchange operator HashJoin Aggregate Columnar Shuffle Stage2 Evaluate Parquet Read Columnar Exchange operator Columnar Aggregate Aggregate
- 9. Native SQL Engine Design ▪ Columnar Data Source ▪ Columnar Shuffle ▪ Columnar Compute ▪ Memory Management
- 10. Spark Internal Format UnsafeRow Columnar Data Source Columnized Format (parquet, orc) Column to Row? Spark used a virtual way to treat column data as row, while memory is not adjacent Row-based Data Source Arrow based Data Source Arrow Format MetaData Parquet orc csv kudu cassandra HBase RowBased Format (csv, …) Unify and fastJSON V.S.
- 11. Columnar Data Source 11 Spark Arrow DataSource (pyspark, thriftserver, sparksql,…) Arrow Java Datasets API (Zero data copy, memory reference only) Arrow C++ Datasets API (HDFS, localFS, S3A) (Parquet, ORC, CSV, ..)
- 12. ▪ Features ▪ Fast / Parallel / Auth supported Native Libraries for HDFS / S3A / Local FS ▪ PushDown supported Pre-executed statistics/metadata filters ▪ Partitioned File and DPP enabled Columnar Data Source 0 <= ID < 5000 5000 <= ID < 10000 unread ID = 7500 ID = 7500 Truncated Files
- 13. Columnar Shuffle • Hash-based partitioning(split) with LLVM optimized execution • Ser/de-ser based on arrow record batch • Efficient data compression for different data format • Coalesce batches during shuffle read • Supports Adaptive Query Execution(AQE) ColumnarExchange Mapper ColumnarExchange Reducer compressed file compressed file compressed file compressed file CoalesceBatches Hash based partition
- 14. Supported SQL Operators Overview Operators WindowExec UnionExec ExpandExec SortExec ScalarSubquery ProjectExec ShuffledHashJoin BroadcastJoinExec FilterExec ShuffleExchangeExec BroadcastExchangeExec datasources.v2.BatchScanExec datasources.v1.FileScanExec HashAggregateExec ….. Expression NormalizeNaNAndZero Subtract Substring ShiftRight Round PromotePrecision Multiply Literal LessThanOrEqual LessThan KnownFloatingPointNormalized IsNull And Add …. Expression IsNotNull GreaterThanOrEqual GreaterThan EqualTo ExtractYear Divide Concat Coalesce CheckOverflow Cast CaseWhen BitwiseAnd AttributeReference Alias …. Automatically fallback to row-based execution if there are unsupported operators/expressions
- 15. ColumnarCondProjection Columnar Projector & Filter ▪ LLVM IR based execution w/ AVX optimized code ▪ Based on Arrow Gandiva, extended with more functions ▪ Combined filter & projection into CondProjector ▪ ColumnarBatch based execution Scan B Filter ColumnarExchange Projection Example: If (Field_A + Field_B + Field_C) as Field_new > Field_D output [Field_new, Field_A, Field_B, Field_C, Field_D] LLVM IR One call
- 16. Native Hashmap ▪ Faster Hashmap building and lookup w/ AVX optimizations ▪ Compatible with Spark’s murmurhash if configured ▪ Performance benefits for HashAggregation and HashJoins Scan A Scan B Filter BoradcastHashJoin HashAggregate BoradcastExchange ShuffleExchange HashAggregate
- 17. Stage ColumnarExchange Stage Columnar BroadcastExchange Stage ColumnarShuffleReader ColumnarBroadcastHashJoin Broadcast data consists of 1. HashMap (key -> indices) 2. Arrow RecordBatch using ColumnarBroadcastExchange, data size is reduced by 80% Stage ColumnarBroadcastJoin ColumnarExchange … … ColumnarShuffleReader hash payload 0x8198 <0, 0>, key1 0x7723 <0, 1>,key2 … … 0x6388 <10240, 1076> Key1076 0x9944 <10240, 1077> Key1077 0x8761 <10240, 1078> key1078 +
- 18. Native Sort ▪ Faster sort implementation w/ AVX optimizations ▪ Most powerful algorithms used for different data structures ▪ Performance benefits for sort and sort merge joins Scan A Scan B CondProjection SortMergeJoin Exchange CondProjection Exchange Sort Sort Exchange Sort
- 19. Stage ColumnarSortMergeJoin ColumnarExchange … … Stage ColumnarSort Stage Columnarsort Stage ColumnarShuffleReader ColumnarSort and ColumnarSortMergeJoin 3 implementation of sort 1. One column data sort(used by semi or anti) -> inplace radix sort (AVX optimizable) 2. One column of key with multiple columns of payload -> radix sort to indices (AVX optimizable) -> lazy materialization 3. Multiple columns of keys with payloads -> codegened quick sort to indices(AVX optimizable) -> lazy materialization AVX optimized project { chain key_0 in left table #1 apply project compare key_0 and key_1 in right table #2 apply condition materialize one line to arrow }
- 20. Stage ColumnarExchange Stage ColumnarBroadcastExchange Stage ColumnarBroadcastExchange Stage ColumnarExchange Stage ColumnarShuffleReader Stage ColumnarShuffleReader ColumnarShuffledHashJoin ColumnarProject ColumnarBroadcastJoin ColumnarFilter ColumnarBroadcastJoin ColumnarExchange Columnar WholeStageCodeGen WSCG Code generated Cpp codes 1. Build HashRelation #0 2. Build HashRelation #1 3. Build HashRelation #2 Loop keys_arrays { probe key_0 in HashRelation #0 apply Project probe key_1 in HashRelation #1 apply condition probe key_2 in HashRelation #2 materialize one line to arrow } AVX optimized { probe key_0 in HashRelation #0 apply project probe key_1 in HashRelation #1 apply condition probe key_2 in HashRelation #2 materialize one line to arrow } g++ compilation
- 21. Native SQL engine call flow Spark Context Executor Oap-native-sql executeColumnar().mapPartitions JniWrapper Expression Tree RecordBatch Gandiva Native SQL Engine CPPCodeGenerator RecordBatch Expression Input Output Precompiled kernels
- 22. Memory Management SparkTaskMemoryManager ArrowAllocationManager Native MemoryDirect MemoryJVM Memory [java] Spark.TaskMemoryManager [Java] arrow.AllocationManager [cpp] arrow::MemoryPool register grant spill Data Source Column Project Column Sort Column Shuffle Column Reader Native Memory Native Memory Direct Memory Direct Memory Direct Memory Column To Row JVM Memory Row TakeOrdered AndProject JVM Memory Column BHJ Native Memory release release release release release release Data retain hashMap
- 23. Example run of TPCH-Q4
- 24. Summary ▪ AVX instructions can greatly improve performance on SQL workloads ▪ Native SQL is open sourced. For more details please visit: https://github.com/Intel-bigdata/OAP ▪ Native SQL engine is under heavy development, works for TPC- H/TPC-DS now
- 25. Q&A
- 26. Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.
- 27. Legal Information: Benchmark and Performance Disclaimers ▪ Performance results are based on testing as of Feb. 2019 & Aug 2020 and may not reflect all publicly available security updates. See configuration disclosure for details. No product can be absolutely secure. ▪ Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information, see Performance Benchmark Test Disclosure. ▪ Configurations: see performance benchmark test configurations.
- 28. Notices and Disclaimers ▪ No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. ▪ Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. ▪ This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps. ▪ The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request. ▪ Intel, the Intel logo, Xeon, Optane, Optane Persistent Memory are trademarks of Intel Corporation in the U.S. and/or other countries. ▪ *Other names and brands may be claimed as the property of others ▪ © Intel Corporation.