Building a Unified Data Pipeline with Apache Spark and XGBoost with Nan Zhu
20 likes7,337 views

Nan Zhu discusses the integration of XGBoost and Apache Spark to create a unified machine learning pipeline, providing insights into the functionality and advantages of XGBoost as a gradient boost decision tree framework. The document outlines the collaborative efforts of the Distributed Machine Learning Community (DMLC) and highlights the design aspects of XGBoost-Spark, aimed at simplifying the machine learning process within the Spark ecosystem. Additionally, it emphasizes the importance of efficient communication between XGBoost and Spark for enhanced performance in distributed training scenarios.





















![Painpoint in Productionalizing
XGBoost
XGBoost
[1] D. Sculley, et al., Hidden Technical Debt in Machine Learning Systems, NIPS 2015
“a mature system might end up being (at most) 5% machine learning
code and (at least) 95% glue code”[1]
“Glue code is costly in the long term because it tends to freeze a
system to the peculiarities of a specific system”[1]](https://image.slidesharecdn.com/033nanzhu-170614011107/85/Building-a-Unified-Data-Pipeline-with-Apache-Spark-and-XGBoost-with-Nan-Zhu-23-320.jpg)



![“Apache Spark is an open-source Cluster-computing
framework…centered on a data structure called
Resilient Distributed Dataset (RDD)”[1]
[1] https://en.wikipedia.org/wiki/Apache_Spark
Mission 1: Make XGBoost and Spark
Communicate in Execution and Memory Layer](https://image.slidesharecdn.com/033nanzhu-170614011107/85/Building-a-Unified-Data-Pipeline-with-Apache-Spark-and-XGBoost-with-Nan-Zhu-27-320.jpg)





![MLlib …make practical machine learning
scalable and easy…ML Algorithms…
Featurization…Pipelines…
Persistence…Utilities…[2]
Mission 2: Integrate with Spark ML
Framework
[2] http://spark.apache.org/docs/latest/ml-guide.html](https://image.slidesharecdn.com/033nanzhu-170614011107/85/Building-a-Unified-Data-Pipeline-with-Apache-Spark-and-XGBoost-with-Nan-Zhu-33-320.jpg)



![Building a Unified Pipeline with
XGBoost and Spark
val paramGrid = new ParamGridBuilder()
.addGrid(xgbEstimator.eta, Utils.fromConfigToParamGrid(conf)(xgbEstimator.eta.name))
.addGrid(xgbEstimator.maxDepth,
Utils.fromConfigToParamGrid(conf)(xgbEstimator.maxDepth.name).
map(_.toInt))
.addGrid(xgbEstimator.gamma, Utils.fromConfigToParamGrid(conf)(xgbEstimator.gamma.name))
.addGrid(xgbEstimator.lambda, Utils.fromConfigToParamGrid(conf)(xgbEstimator.lambda.name))
.addGrid(xgbEstimator.colSampleByTree, Utils.fromConfigToParamGrid(conf)(
xgbEstimator.colSampleByTree.name))
.addGrid(xgbEstimator.subSample, Utils.fromConfigToParamGrid(conf)(
xgbEstimator.subSample.name))
.build()
val cv = new CrossValidator()
.setEstimator(xgbEstimator)
.setEvaluator(new BinaryClassificationEvaluator().
setRawPredictionCol("probabilities").setLabelCol("label"))
.setEstimatorParamMaps(paramGrid)
.setNumFolds(5)
val cvModel = cv.fit(trainingSet)
cvModel.bestModel.asInstanceOf[XGBoostModel]
val pipeline = new Pipeline().setStages(
Array(monthIndexer, daysOfMonthIndexer, daysOfWeekIndexer,
uniqueCarrierIndexer, originIndexer, destIndexer, monthEncoder, daysOfMonthEncoder,
daysOfWeekEncoder, uniqueCarrierEncoder, originEncoder, destEncoder, vectorAssembler))
pipeline.fit(trainingSet).transform(trainingSet).selectExpr(
"features", "case when dep_delayed_15min = true then 1.0 else 0.0 end as label")
Setting
Preprocessing
Stages
Searching
Optimal
Parameters of
XGBoost with
CrossValidation](https://image.slidesharecdn.com/033nanzhu-170614011107/85/Building-a-Unified-Data-Pipeline-with-Apache-Spark-and-XGBoost-with-Nan-Zhu-37-320.jpg)






Building a Unified Data Pipeline with Apache Spark and XGBoost with Nan Zhu
- 1. Nan Zhu Distributed Machine Learning Community (DMLC) & Microsoft Building a Unified Machine Learning Pipeline with XGBoost and Spark
- 2. About Me • Nan Zhu – Software Engineer in Microsoft • Spark Streaming, Structured Streaming integration with Azure Event Hubs (a talk at 5:00 p.m. today) • Spark Workload Performance Test/Monitoring/Optimization – Committee member of Apache MxNet (incubator) and DMLC, Contributor of Apache Spark
- 3. About Distributed Machine Learning Community (DMLC) • DMLC is a group of researchers and engineers collaborating on open-source machine learning projects • What we are building – XGBoost (https://github.com/dmlc/xgboost ) – MxNet (https://github.com/dmlc/mxnet ) – Etc.
- 4. Agenda • Introduction to XGBoost and XGBoost-Spark – Will not go into algorithm details and formula derivations(http://www.kdd.org/kdd2016/papers/files/rfp0697- chenAemb.pdf) • Why Integrating XGBoost and Spark? • Design of XGBoost-Spark • What we can learn from XGBoost-Spark
- 5. Disclaimer: Personal Contribution to XGBoost Project
- 7. XGBoost & XGBoost-Spark (1) • XGBoost – A Gradient Boost Tree System – Created by Tianqi Chen (PhD student in UW) in 2014 – Today: Python, R, Java, Scala, C++ bindings. Runs on single machine, Hadoop, Spark, Flink and GPU. • XGBoost-Spark – Integrating XGBoost and Apache Spark – Idea generated during NIPS 2015 in the discussion between Tianqi and me. – First Generation (RDD) in March of 2016 – Second Generation (DataFrame + ML Framework) in September of 2016
- 8. XGBoost & XGBoost-Spark (2) • More than half of the winning solutions in machine learning challenges hosted at Kaggle adopt XGBoost • XGBoost-Spark Users’ Affiliations: – Airbnb, Alibaba, eBay, Microsoft, Snapshots,Tencent, Uber, etc. • XGBoost Developers – University of Washington, Microsoft, Uptake, etc.
- 9. XGBoost: Gradient Boost Decision Tree A B C
- 10. Decision Tree in XGBoost • CART: Classification and Regression Tree NOTE: A lot of games are not tailored to girls’ interests which need more improvements !!!
- 11. What is Decision Tree Boosting? • Tree Boosting with CARTs Ensemble Learning: Use multiple weaker Learners to achieve better performance than anyone alone
- 12. Learning Trees with XGBoost Iteration N L? M? Y N Y N … Wn3 Wn2Wn1 Iteration 1 Use Computer Daily? Y N Y? Y N W11 W12 W13 Iteration 0 Age < 15 Is Male? Y N X? Y NY N W01 W02 W03 W04 How: what is gradient boost tree?
- 13. Supervised Learning Basics 𝑂𝑏𝑗 𝜃 = 𝐿 𝜃 + Ω(𝜃) 𝐿 𝜃 - Training Loss: measures how well model fit on training data Ω(𝜃) - Regularization: measures complexity of model (we do not want to get a model only fitting with already-seen, i.e. training, data)
- 14. Objective Function in XGBoost 𝑂𝑏𝑗, 𝜃 = ∑ 𝐿(𝑦/, 𝑦/ ,12 + 3 /42 𝑓,(𝑥/)) + Ω(𝑓,) 𝑦/ - ground truth of data point i 𝑦/ ,12 - prediction for data point i in iteration t -1 𝑓, – tree with the optimal structure to be added in iteration t
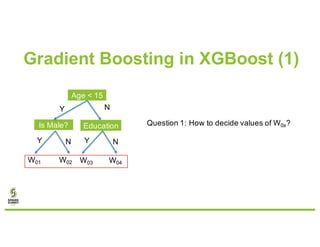
- 15. Gradient Boosting in XGBoost (1) Age < 15 Is Male? Y N Education Y NY N W01 W02 W03 W04 Question 1: How to decide values of W0x?
- 16. Gradient Boosting in XGBoost (2) 𝑂𝑏𝑗, 𝜃 = ∑ 𝐿(𝑦/, 𝑦/ ,12 + 3 /42 𝑓,(𝑥/)) + Ω(𝑓,) 𝑓, 𝑥/ : a vector of scores of leave nodes, and a function maps data points to leaves, 𝑤9(𝑥) Ω 𝑓, : number of leaf nodes, T, and sum of squared score of leaf nodes = I 𝐿(𝑦/, 𝑦/ ,12 + 3 /42 𝑤9(𝑥)) + γ𝑇 + 1 2 λ I 𝑤O P Q O42
- 17. Gradient Boosting in XGBoost (3) where Finally (http://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf)
- 18. Finding Optimal Splitting Point in XGBoost Age < 15 Is Male? Y N X Y NY N W01 W02 W03 W04 Question 2: How to decide splitting point, e.g. 15? (http://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf)
- 19. Approximate Algorithm to Find Best Splits For each feature k: (1) Find candidate splitting points (Sk1, …, Skl), (transforming continuous feature values to discrete buckets pursuing even distribution) (2) Split with the maximum loss reduction corresponding splitting points (http://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf) Avoid Enumerating every feature value in a node, as they might be continuous
- 20. Other optimizations in XGBoost • Parallel Tree Construction • Sparsity-aware Split Finding – Learning default direction for missing values from data • Cache-aware Access – Memory prefetching – Cache-friendly thread working memory size • Out-of-core computation – Scale to data size larger than physical memory • Distributed Training
- 21. XGBoost is so good! Let’s build a machine learning Pipeline based on XGBoost!!!
- 22. First Version (Separate XGBoost) Raw Data Sources Data Clean Data Storage Machine Learning Core System Serving Various Supporting Infrastructure Glue Code Glue Code
- 23. Painpoint in Productionalizing XGBoost XGBoost [1] D. Sculley, et al., Hidden Technical Debt in Machine Learning Systems, NIPS 2015 “a mature system might end up being (at most) 5% machine learning code and (at least) 95% glue code”[1] “Glue code is costly in the long term because it tends to freeze a system to the peculiarities of a specific system”[1]
- 24. Raw Data Sources Data Clean Data Storage Machine Learning Core System Serving Biggest Advantage of Spark MLLIB Various Supporting Infrastructure Logistic Regression Decision Tree Naïve Bayes No Additional Glue Code: run in Spark cluster, use standard Data Source API of Spark SQL and existing tuning/feature engineering utils Spark SQL based Interface
- 25. Raw Data Sources Data Clean Data Storage Machine Learning Core System Serving Ideal Version of Pipeline Various Supporting Infrastructure Logistic Regression Decision Tree Naïve Bayes Take XGBoost as one of the algorithms in Spark ML Spark SQL based Interface
- 26. How?
- 27. “Apache Spark is an open-source Cluster-computing framework…centered on a data structure called Resilient Distributed Dataset (RDD)”[1] [1] https://en.wikipedia.org/wiki/Apache_Spark Mission 1: Make XGBoost and Spark Communicate in Execution and Memory Layer
- 28. Distributed Training with XGBoost (per Iteration) Training Data Partition 1 Training Data Partition 0 Training Data Partition 2 Statistics Based on Partition 1 Statistics Based on Partition 0 Statistics Based on Partition 2 Grow trees based on Synced Statistics Grow trees based on Synced StatisticsGrow trees based on Synced Statistics XGBoost Worker 1 XGBoost Worker 0 XGBoost Worker 2 Tracker Stats Sync with Allreduce
- 29. Integrate XGBoost and Spark in Execution Layer Executor Task 1 Driver Tracker XGBoost Worker Executor Task 0 Task 2 Integrate Distributed Communication: AllReduce Layer (Bypassing shuffle/broadcast) Integrating Execution Model: Call native libraries through JNI Scala Code Start Tracker with Forked Process
- 30. Integrate XGBoost and Spark In Memory Layer Executor Task 1 Driver Tracker XGBoost Worker 1 Executor Task 0 Task 2 RDD Memory Space Native Memory Space Connect Memory Layer: Memory copy through JNI
- 31. Memory Layout Facilitating Batching Copy To avoid call JNI for every data point in training dataset … … … … … … Offsets Labels Batch Size Indices Values Copy to Native Memory in Batch, interpret by native code
- 32. Wrap Internals with APIs val trainDF = sparkSession.read.format("libsvm").load(inputT rainPath) val paramMap = Map( "eta" -> 0.1f, "max_depth" -> 2, "objective" -> "binary:logistic") val xgboostModel = XGBoost.trainWithDataFrame( trainDF, paramMap, numRound, nWorkers = args(1).toInt, useExternalMemory = true) Load Training Data with Spark SQL API Configure XGBoost Call XGBoost-Spark API to train
- 33. MLlib …make practical machine learning scalable and easy…ML Algorithms… Featurization…Pipelines… Persistence…Utilities…[2] Mission 2: Integrate with Spark ML Framework [2] http://spark.apache.org/docs/latest/ml-guide.html
- 34. A Machine Learning Pipeline Built with Spark ML Framework https://dzone.com/articles/distingish-pop-music-from-heavy-metal-using-apache Raw DataFrame Transformer 1 (StringIndexer) Transformer 2 (OneHotEnco der) Estimator Transformer 3 (Model) Prediction Result Training Prediction Tuning
- 35. Fit XGBoost into Spark ML framework Make XGBoost train as a native Spark ML Algorithm XGBoostEstimator Extends ML’s Estimator triggering distributed XGBoost Workers over training DataFrame Make XGBoost predict as a native Spark ML Model XGBoostModel Extends ML’s Transformer Make XGBoost be tunable as a native Spark ML Algorithm XGBoostParams Extends ML’s Parameters system
- 36. Fitting into Spark ML framework CrossValidationSplit XGBoost Estimator Evaluator ParamGrid StringIndexer vectorAssembler XGBoostModel A Full Pipeline with XGBoost and Spark ML Utils XGBoostEstimator Extends ML’s Estimator triggering distributed XGBoost Workers over training DataFrame XGBoostModelExtends ML’s Transformer XGBoostParamsExtends ML’s Parameters system
- 37. Building a Unified Pipeline with XGBoost and Spark val paramGrid = new ParamGridBuilder() .addGrid(xgbEstimator.eta, Utils.fromConfigToParamGrid(conf)(xgbEstimator.eta.name)) .addGrid(xgbEstimator.maxDepth, Utils.fromConfigToParamGrid(conf)(xgbEstimator.maxDepth.name). map(_.toInt)) .addGrid(xgbEstimator.gamma, Utils.fromConfigToParamGrid(conf)(xgbEstimator.gamma.name)) .addGrid(xgbEstimator.lambda, Utils.fromConfigToParamGrid(conf)(xgbEstimator.lambda.name)) .addGrid(xgbEstimator.colSampleByTree, Utils.fromConfigToParamGrid(conf)( xgbEstimator.colSampleByTree.name)) .addGrid(xgbEstimator.subSample, Utils.fromConfigToParamGrid(conf)( xgbEstimator.subSample.name)) .build() val cv = new CrossValidator() .setEstimator(xgbEstimator) .setEvaluator(new BinaryClassificationEvaluator(). setRawPredictionCol("probabilities").setLabelCol("label")) .setEstimatorParamMaps(paramGrid) .setNumFolds(5) val cvModel = cv.fit(trainingSet) cvModel.bestModel.asInstanceOf[XGBoostModel] val pipeline = new Pipeline().setStages( Array(monthIndexer, daysOfMonthIndexer, daysOfWeekIndexer, uniqueCarrierIndexer, originIndexer, destIndexer, monthEncoder, daysOfMonthEncoder, daysOfWeekEncoder, uniqueCarrierEncoder, originEncoder, destEncoder, vectorAssembler)) pipeline.fit(trainingSet).transform(trainingSet).selectExpr( "features", "case when dep_delayed_15min = true then 1.0 else 0.0 end as label") Setting Preprocessing Stages Searching Optimal Parameters of XGBoost with CrossValidation
- 38. Performance Evaluation 0 2 4 6 8 10 12 XGBoost-Spark Spark GBT Classifier PerIterationTrainingTime(sec) Per Iteration Training Time Airline Dataset (22M examples), 48 Workers in XGBoost/Tasks in Spark Hardware: 6 D4V2 VMs on Azure serving Spark Executors
- 39. Future Work • Unified Memory Space Executor Driver Tracker Task 1 XGBoost Worker 1 Executor Task 0 RDD Memory Space Task 2 Native Memory Space Apache Arrow https://arrow.apache.org/
- 40. What we can learn from the design of XGBoost-Spark • Spark ML framework facilitates us to implement something like XGBoost-Spark • Beyond the current Spark ML… – More pain points in ML pipelines, e.g. entanglement (record system behavior), data dependencies (versioning training dataset), …
- 41. Summary • Introduction to XGBoost & XGBoost Spark • Machine Learning algorithm is only a very small part of the complete data processing/analytic pipeline – Embed XGBoost to Apache Spark ML Pipeline (XGBoost-Spark) to resolve your headaches • A new view to Spark/Spark ML
- 42. Acknowledgement • Special thanks to Tianqi Chen, who created XGBoost project and offered strong support when I built XGBoost-Spark • Thanks to XGBoost Committers/Contributors/Users who keep working on improving the project • Thanks to McGill University which supports me working on the project