Building High Performance MySQL Query Systems and Analytic Applications
Download as PPT, PDF0 likes847 views

The document discusses strategies for building high-performance MySQL query systems and analytic applications, emphasizing the importance of data management in read-intensive environments. Key recommendations include utilizing modern hardware, implementing read sharding, and leveraging column-oriented databases like Calpont's InfiniDB for superior performance. It also outlines techniques for efficient data loading, troubleshooting performance issues, and ensuring transparency in capacity expansion and failover processes.
































Building High Performance MySQL Query Systems and Analytic Applications
- 1. Building High-Performance MySQL Query Systems and Analytic Applications Robin Schumacher
- 2. Agenda The importance of query and analytic applications Core recommendations for building fast query / analytic applications Practical techniques for creating high-performance query / analytic systems Conclusions
- 3. What are we talking about? We’re talking about databases that are used – primarily – for servicing read-intensive applications These systems could be 100% devoted to query activity or a hybrid application that services both read-intensive work and traditional OLTP activities The design and performance of these systems differ greatly from traditional OLTP databases
- 4. Reporting and Business Intelligence DB’s All companies recognize the need for BI Challenges come in the forms of large data volumes, performance, and cost Staffing and lack of experience can also cause issues
- 5. Data Warehouses/Marts/Analytic DB’s OLTP Files/XML Log Files Operational Source Data Staging or ODS ETL Final ETL Reporting, BI, Notification Layer Ad-Hoc Dashboards Reports Notifications Users Staging Area Data Warehouse Warehouse Archive Purge/Archive Data Warehouse and Metadata Management
- 6. Reporting Databases OLTP Database Read Shard One Reporting Database Application Servers End Users ETL Data Archiving Link Replication
- 7. Application Sharding / Partitioning Read ‘sharding’ or partitioning becoming very popular, especially in high-traffic Web environments Basic tactic is to direct all read/query traffic to one set of databases and OLTP work to a different database Sometimes involves a fair amount of application work to ensure traffic is directed to the proper databases, but many find it not all that difficult
- 8. Read Sharding / Partitioning
- 9. What are the core rules to follow in order to avoid anxiety over building fast read-intensive, reporting, and analytic databases?
- 10. #1 Only Read the Data You Need Not as easy as it sounds in a legacy RDBMS Indexing is not always the answer (and can actually make things worse in some cases) All I/O is important – excessive logical I/O can cripple a system every bit as fast as too much physical I/O can Data ‘traffic jams’ oftentimes occur because of unnecessary I/O
- 11. #2 Exploit Modern Hardware Use all available CPUs/cores Some MySQL storage engines (InnoDB, Cluster) now scale beyond 4 CPUs but they aren’t the best for query activity Use all available disk/storage devices Look into distributed caching architectures
- 12. #3 Divide and Conquer This generally equates to parallel processing and application partitioning in hybrid systems Queries should be parallelized across CPUs/cores on single box Queries should be parallelized across multiple nodes in MPP fashion Only way to truly tackle large volumes of data
- 13. #4 Scale both I/O and User Connections Divide and conquer applies to both the I/O layer and user connectivity layer Distribution of I/O via MPP allows linear performance gains when properly done Even idle user connections can eat up resources fast; should have way of scaling concurrency
- 14. #5 Provide Transparent Expansion and Failover Should have way to increase capacity and resources without stopping query activity For critical systems, will need to have way to failover to stand-by servers if primary fails Both should be as transparent to the end user as possible
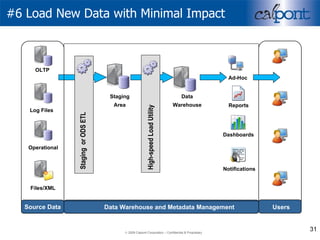
- 15. #6 Load New Data with Minimal Impact For real time or near real time applications, data loads must have minimal impact on query activity Data (obviously…) should be loaded as quickly as possible, which means parallel load processing Scheduled loads and ETL operations should be auto-monitored Watch impact of new data on query times
- 16. #7 Quickly Troubleshoot Poor Read Performance Must have way to exonerate the innocent and implicate the guilty – in other words, is it the database or not? Bad database design is the #1 cause of poor performance Poorly coded SQL is the #2 cause
- 17. Good suggestions, but how can I practically do all these things…?
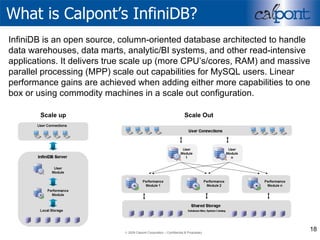
- 18. What is Calpont’s InfiniDB? InfiniDB is an open source, column-oriented database architected to handle data warehouses, data marts, analytic/BI systems, and other read-intensive applications. It delivers true scale up (more CPU’s/cores, RAM) and massive parallel processing (MPP) scale out capabilities for MySQL users. Linear performance gains are achieved when adding either more capabilities to one box or using commodity machines in a scale out configuration. Scale up Scale Out
- 19. #1 Only Read the Data You Need Column databases only read the columns needed to satisfy a query vs. full rows Column databases (most of them…) remove the need for indexing because the column is the index Column databases automatically eliminate unnecessary I/O both logically and physically As a rule of thumb, column databases provide 5-10x the query performance of legacy RDBMS’s InfiniDB has a column-oriented architecture Recommendation : Start using a column-oriented database Caveat : if you are reading all (select *) or most of the columns in a table, then a column database may not be right for your application.
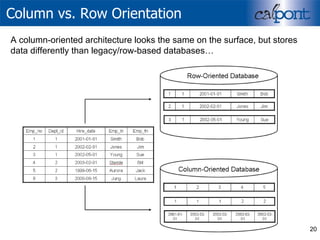
- 20. Column vs. Row Orientation A column-oriented architecture looks the same on the surface, but stores data differently than legacy/row-based databases…
- 21. #2 Exploit Modern Hardware A column-based database with scale up capabilities is a great combination – not only do you read only the data that’s needed but it is accelerated by all a machine’s processing power Scale up abilities generally equates to having a multi-threaded database architecture Currently, the only internal MySQL engines that offer scale up are InnoDB and MySQL Cluster, neither of which are optimal for complex, analytic queries. InfiniDB from Calpont is both column-oriented and multi-threaded Recommendation : Use databases/storage engines that scale up (i.e. use available CPU’s/cores)
- 22. InfiniDB Community – Scale Up InfiniDB Community edition is a FOSS, multi-threaded database server that is capable of using a machine’s CPUs/cores to process queries 87% 22.14 164.12 Q3.2 83% 55.04 316.79 Q3.1 87% 15.94 121.33 Q2.3 87% 19.70 151.20 Q2.2 79% 44.65 210.21 Q2.1 Overall Percent Reduction with additional cores InfiniDB 8 cores (elapsed time in seconds) InfiniDB 1 Core (elapsed time in seconds) SSB Query (@100 scale)
- 23. #3 Divide and Conquer For Web and general purpose database applications, look into read sharding/partitioning to service queries. Can be done via replication or ETL For data warehousing/analytic databases, domain or time-based partitioning across multiple machines via ETL can help Memcached usage can help in certain cases InfiniDB provides true MPP query capabilities to deliver a real divide-and-conquer strategy Recommendation : Use Scale-Out in addition to Scale-up
- 24. InfiniDB Enterprise – Scale Up and Out User Connections User Module 1 User Module n Performance Module 1 Performance Module n Performance Module 2 Shared Storage Database files, System Catalog
- 25. #3 Divide and Conquer InfiniDB also ‘divides and conquers’ by: Shared nothing data cache provides distributed data cache across all nodes Distributed hash joins, which are tailor-made for large join operations 87% 77.74 148.49 297.46 597.97 Q3.2 84% 134.21 316.50 425.25 848.79 Q3.1 87% 51.36 96.03 192.03 386.66 Q2.3 87% 56.41 106.37 214.87 430.25 Q2.2 87% 68.21 129.90 261.35 531.34 Q2.1 Overall Percent Reduction from 1 – 8PM’s 8PM (elapsed time in seconds) 4PM (elapsed time in seconds) 2PM (elapsed time in seconds) 1PM (elapsed time in seconds) SSB Query @1000
- 26. #4 Scale both I/O and User Connections Recommendation : Use modular architecture User Connections User Module 1 User Module n Performance Module 1 Performance Module n Performance Module 2 Shared Storage Database files, System Catalog Add more Performance Modules to scale I/O Add more User Modules to scale concurrency
- 27. #5 Provide Transparent Expansion and Failover A combination of replication and application sharding / partitioning can provide for capacity expansion and failover Failover is not built in to MySQL but can be implemented via replication and floating IP’s or other products like DRBD InfiniDB allows new Performance Module nodes to be transparently added and removed. Failover is automatically handled at the performance module level InfiniDB allows new User Modules to be added and configured to an existing setup. Failover involves aiming existing users at other participating nodes from a failed user module Recommendation : Use either replication or MPP
- 28. #5 Provide Transparent Expansion and Failover Cust_id 1-999 Cust_id 1000-1999 Cust_id 2000-2999 Sharding Architecture MySQL Replication Web/App Servers Browsers
- 29. #5 Provide Transparent Expansion and Failover User Connections User Module 1 User Module n Performance Module 1 Performance Module n Performance Module 2 Shared Storage Database files, System Catalog If one Performance Module fails, traffic resumes with the remaining nodes User queries can be redirected to other User Modules if one fails
- 30. #6 Load New Data with Minimal Impact For incremental data feeds, you can use ETL tools to write new data to flat files on read database host and then load them with high-speed loader vs. incremental inserts Storage engines supporting MVCC should be able to support concurrent loads/queries InfiniDB supports MVCC InfiniDB has high-speed, multi-threaded, non-blocking loader that loads data and simply moves a table’s high-water mark once the load has been completed Recommendation : Use two-step ETL feed with non-blocking load utilities and/or MVCC database engine
- 31. #6 Load New Data with Minimal Impact OLTP Files/XML Log Files Operational Source Data Staging or ODS ETL High-speed Load Utility Ad-Hoc Dashboards Reports Notifications Users Staging Area Data Warehouse Data Warehouse and Metadata Management
- 32. #7 Quickly Troubleshoot Poor Read Performance MySQL 5.1 and above ships with mysqlslap utility which can help do load testing; others 3 rd party tools exist as well MySQL 5.1 SQL profiler a good utility to examine SQL performance InfiniDB offers both a SQL statement diagnostic utility as well as a more detailed trace utility for troubleshooting slow running code InfiniDB removes the need for indexing, partitioning, and most other database design tuning; no heavy-duty expertise required to build a very fast database Recommendation : Proactively use load testing; reactively use SQL analysis and tracing
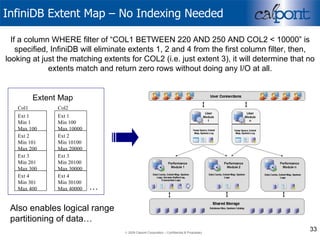
- 33. InfiniDB Extent Map – No Indexing Needed If a column WHERE filter of “COL1 BETWEEN 220 AND 250 AND COL2 < 10000” is specified, InfiniDB will eliminate extents 1, 2 and 4 from the first column filter, then, looking at just the matching extents for COL2 (i.e. just extent 3), it will determine that no extents match and return zero rows without doing any I/O at all. … Extent Map Also enables logical range partitioning of data… Ext 2 Min 101 Max 200 Ext 3 Min 201 Max 300 Ext 4 Min 301 Max 400 Col1 Ext 1 Min 1 Max 100 Ext 2 Min 10100 Max 20000 Ext 3 Min 20100 Max 30000 Ext 4 Min 30100 Max 40000 Col2 Ext 1 Min 100 Max 10000
- 34. Summary Provides both diagnostic and tracing tools; no major design tuning efforts Use load testing and SQL analysis tools Method for troubleshooting poor read performance Has high-speed loader with no blocking and MVCC Use two-step ETL and bulk load process Load data with minimal impact Does transparent failover for I/O and manual for connectivity Use replication and load balancers Provide transparent expansion and failover Modular architecture for scaling both concurrency and I/O Application partition Scale concurrency and I/O Supports MPP scale out Spread load via replication or MPP Divide and Conquer Is multi-threaded and uses multiple CPUs / Cores Use DB’s/storage engines that are multi-threaded Exploit modern hardware Is column-oriented Use column database Only read the data you need InfiniDB General Technique Recommendation
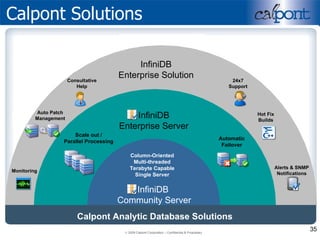
- 35. Calpont Solutions Calpont Analytic Database Server Editions Calpont Analytic Database Solutions InfiniDB Community Server Column-Oriented Multi-threaded Terabyte Capable Single Server InfiniDB Enterprise Server Scale out / Parallel Processing Automatic Failover InfiniDB Enterprise Solution Monitoring 24x7 Support Auto Patch Management Alerts & SNMP Notifications Hot Fix Builds Consultative Help
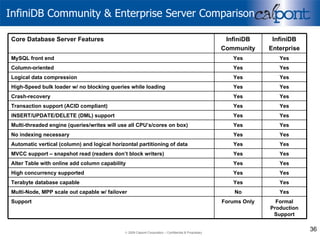
- 36. InfiniDB Community & Enterprise Server Comparison Yes No Multi-Node, MPP scale out capable w/ failover Formal Production Support Forums Only Support Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes InfiniDB Community Yes INSERT/UPDATE/DELETE (DML) support Yes Transaction support (ACID compliant) Yes MySQL front end Yes Logical data compression Yes High-Speed bulk loader w/ no blocking queries while loading Yes Multi-threaded engine (queries/writes will use all CPU’s/cores on box) Yes Crash-recovery Yes Terabyte database capable Yes High concurrency supported Yes Alter Table with online add column capability Yes MVCC support – snapshot read (readers don’t block writers) Yes Automatic vertical (column) and logical horizontal partitioning of data Yes No indexing necessary Yes Column-oriented InfiniDB Enterprise Core Database Server Features
- 37. For More Information Download InfiniDB Community Edition Download InfiniDB documentation Read the InfiniDB technical white paper Read InfiniDB intro articles on MySQL dev zone Visit InfiniDB online forums Trial the InfiniDB Enterprise Edition: http://www.calpont.com www.infinidb.org
- 38. Building High-Performance MySQL Query Systems and Analytic Applications Thanks…!