Building iot applications with Apache Spark and Apache Bahir
2 likes459 views

The document discusses the IBM Spark Technology Center's contributions to open-source projects, particularly focusing on Apache Spark and Apache Bahir for building IoT applications. It includes technical details about the functionalities of Apache Spark, such as Spark SQL, streaming capabilities, and IoT connectivity protocols like MQTT. The document emphasizes the importance of community engagement and the potential of using these technologies for real-time IoT data processing.









![IBM SparkTechnology Center
Apache Spark – Spark SQL
You can run SQL statement with SparkSession.sql(…) interface:
val spark = SparkSession.builder()
.appName(“Demo”)
.getOrCreate()
spark.sql(“create table T1 (c1 int, c2 int) stored as parquet”)
val ds = spark.sql(“select * from T1”)
You can further transform the resultant dataset:
val ds1 = ds.groupBy(“c1”).agg(“c2”-> “sum”)
val ds2 = ds.orderBy(“c1”)
The result is a DataFrame / Dataset[Row]
ds.show() displays the rows
10](https://image.slidesharecdn.com/buildingiotapplicationswithapachesparkandapachebahir-171207100832/85/Building-iot-applications-with-Apache-Spark-and-Apache-Bahir-10-320.jpg)
![IBM SparkTechnology Center
Apache Spark – Spark SQL
You can read from data sources using SparkSession.read.format(…)
val spark = SparkSession.builder()
.appName(“Demo”)
.getOrCreate()
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
// loading csv data to a Dataset of Bank type
val bankFromCSV = spark.read.csv(“hdfs://localhost:9000/data/bank.csv").as[Bank]
// loading JSON data to a Dataset of Bank type
val bankFromJSON = spark.read.json(“hdfs://localhost:9000/data/bank.json").as[Bank]
// select a column value from the Dataset
bankFromCSV.select(‘age).show() will return all rows of column “age” from this dataset.
11](https://image.slidesharecdn.com/buildingiotapplicationswithapachesparkandapachebahir-171207100832/85/Building-iot-applications-with-Apache-Spark-and-Apache-Bahir-11-320.jpg)
![IBM SparkTechnology Center
Apache Spark – Spark SQL
You can also configure a specific data source with specific options
val spark = SparkSession.builder()
.appName(“Demo”)
.getOrCreate()
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
// loading csv data to a Dataset of Bank type
val bankFromCSV = sparkSession.read
.option("header", ”true") // Use first line of all files as header
.option("inferSchema", ”true") // Automatically infer data types
.option("delimiter", " ")
.csv("/users/lresende/data.csv”)
.as[Bank]
bankFromCSV.select(‘age).show() // will return all rows of column “age” from this dataset.
12](https://image.slidesharecdn.com/buildingiotapplicationswithapachesparkandapachebahir-171207100832/85/Building-iot-applications-with-Apache-Spark-and-Apache-Bahir-12-320.jpg)






























Building iot applications with Apache Spark and Apache Bahir
- 1. IBM SparkTechnology Center Paris Open Surce Summit – Apache Software Foundation – Dec 2017 Building IoT Applications with Apache Spark and Apache Bahir Luciano Resende IBM | Spark Technology Center
- 2. 2 Data Science Platform Architect – IBM – Spark Technology Center • Have been contributing to open source at ASF for over 10 years • Currently contributing to : Jupyter Notebook ecosystem, Apache Bahir, Apache Spark, Apache Toree among other projects related to Apache Spark ecosystem [email protected] http://lresende.blogspot.com/ https://www.linkedin.com/in/lresende @lresende1975 https://github.com/lresende @ About me - Luciano Resende
- 3. Open Source Community Leadership Spark Technology Center Founding Partner 188+ Project Committers 77+ Projects Key Open source steering committee memberships OSS Advisory Board Open Source
- 4. IBM SparkTechnology Center IBM Spark Technology Center Founded in 2015. Location: Physical: 505 Howard St., San Francisco CA Web: http://spark.tc Twitter: @apachespark_tc Mission: Contribute intellectual and technical capital to the Apache Spark community. Make the core technology enterprise- and cloud-ready. Build data science skills to drive intelligence into business applications — http://bigdatauniversity.com Key statistics: About 40 developers, co-located with 25 IBM designers. Major contributions to Apache Spark http://jiras.spark.tc Apache SystemML is now a top level Apache project ! Founding member of UC Berkeley AMPLab and RISE Lab Member of R Consortium and Scala Center 4
- 5. IBM SparkTechnology Center Agenda Introductions Apache Spark Apache Bahir IoT Applications Live Demo Summary References 5
- 6. IBM SparkTechnology Center Apache Spark 6
- 7. IBM SparkTechnology Center Apache Spark Introduction What is Apache Spark ? 7 Spark Core Spark SQL Spark Streaming Spark ML Spark GraphX executes SQL statements performs streaming analytics using micro-batches common machine learning and statistical algorithms distributed graph processing framework general compute engine, handles distributed task dispatching, scheduling and basic I/O functions large variety of data sources and formats can be supported, both on- premise or cloud BigInsights (HDFS) Cloudant dashDB SQL DB
- 8. IBM SparkTechnology Center Apache Spark Evolution 8
- 9. IBM SparkTechnology Center Apache Spark – Spark SQL 9 Spark SQL ▪Unified data access APIS: Query structured data sets with SQL or Dataset/DataFrame APIs ▪Fast, familiar query language across all of your enterprise data RDBMS Data Sources Structured Streaming Data Sources
- 10. IBM SparkTechnology Center Apache Spark – Spark SQL You can run SQL statement with SparkSession.sql(…) interface: val spark = SparkSession.builder() .appName(“Demo”) .getOrCreate() spark.sql(“create table T1 (c1 int, c2 int) stored as parquet”) val ds = spark.sql(“select * from T1”) You can further transform the resultant dataset: val ds1 = ds.groupBy(“c1”).agg(“c2”-> “sum”) val ds2 = ds.orderBy(“c1”) The result is a DataFrame / Dataset[Row] ds.show() displays the rows 10
- 11. IBM SparkTechnology Center Apache Spark – Spark SQL You can read from data sources using SparkSession.read.format(…) val spark = SparkSession.builder() .appName(“Demo”) .getOrCreate() case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer) // loading csv data to a Dataset of Bank type val bankFromCSV = spark.read.csv(“hdfs://localhost:9000/data/bank.csv").as[Bank] // loading JSON data to a Dataset of Bank type val bankFromJSON = spark.read.json(“hdfs://localhost:9000/data/bank.json").as[Bank] // select a column value from the Dataset bankFromCSV.select(‘age).show() will return all rows of column “age” from this dataset. 11
- 12. IBM SparkTechnology Center Apache Spark – Spark SQL You can also configure a specific data source with specific options val spark = SparkSession.builder() .appName(“Demo”) .getOrCreate() case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer) // loading csv data to a Dataset of Bank type val bankFromCSV = sparkSession.read .option("header", ”true") // Use first line of all files as header .option("inferSchema", ”true") // Automatically infer data types .option("delimiter", " ") .csv("/users/lresende/data.csv”) .as[Bank] bankFromCSV.select(‘age).show() // will return all rows of column “age” from this dataset. 12
- 13. IBM SparkTechnology Center Apache Spark – Spark SQL Data Sources under the covers • Data source registration (e.g. spark.read.datasource) • Provide BaseRelation implementation • That implements support for table scans: • TableScans, PrunedScan, PrunedFilteredScan, CatalystScan • Detailed information available at • http://www.spark.tc/exploring-the-apache-spark-datasource-api/ 13
- 14. IBM SparkTechnology Center Apache Spark – Spark SQL Structured Streaming Unified programming model for streaming, interactive and batch queries 14 Image source: https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html Considers the data stream as unbounded table
- 15. IBM SparkTechnology Center Apache Spark – Spark SQL Structured Streaming SQL regular APIs val spark = SparkSession.builder() .appName(“Demo”) .getOrCreate() val input = spark.read .schema(schema) .format(”csv") .load(”input-path") val result = input .select(”age”) .where(”age > 18”) result.write .format(”json”) . save(” dest-path”) 15 Structured Streaming APIs val spark = SparkSession.builder() .appName(“Demo”) .getOrCreate() val input = spark.readStream .schema(schema) .format(”csv") .load(”input-path") val result = input .select(”age”) .where(”age > 18”) result.write .format(”json”) . startStream(” dest-path”)
- 16. IBM SparkTechnology Center Apache Spark – Spark Streaming 16 Spark Streaming ▪Micro-batch event processing for near- real time analytics ▪e.g. Internet of Things (IoT) devices, Twitter feeds, Kafka (event hub), etc. ▪No multi-threading or parallel process programming required
- 17. IBM SparkTechnology Center Apache Spark – Spark Streaming Also known as discretized stream or Dstream Abstracts a continuous stream of data Based on micro-batching Based on RDDs 17
- 18. IBM SparkTechnology Center Apache Spark – Spark Streaming val sparkConf = new SparkConf() .setAppName("MQTTWordCount") val ssc = new StreamingContext(sparkConf, Seconds(2)) val lines = MQTTUtils.createStream(ssc, brokerUrl, topic, StorageLevel.MEMORY_ONLY_SER_2) val words = lines.flatMap(x => x.split(" ")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination() 18
- 19. IBM SparkTechnology Center Apache Bahir 19
- 20. IBM SparkTechnology Center MAY/2016: Established as a top-level Apache Project. • PMC formed by Apache Spark committers/pmc, Apache Members • Initial contributions imported from Apache Spark AUG/2016: Flink community join Apache Bahir • Initial contributions of Flink extensions • In October 2016 Robert Metzger elected committer Origins of the Apache Bahir Project
- 21. IBM SparkTechnology Center Origins of the Bahir name Naming an Apache Project is a science !!! • We needed a name that wasn’t used yet • Needed to be related to Spark We ended up with : Bahir • A name of Arabian origin that means Sparkling, • Also associated with a guy who succeeds at everything
- 22. IBM SparkTechnology Center Why Apache Bahir It’s an Apache project • And if you are here, you know what it means What are the benefits of curating your extensions at Apache Bahir • Apache Governance • Apache License • Apache Community • Apache Brand 22
- 23. IBM SparkTechnology Center Why Apache Bahir Flexibility • Release flexibility • Bounded to platform or component release Shared infrastructure • Release, CI, etc Shared knowledge • Collaborate with experts on both platform and component areas 23
- 24. IBM SparkTechnology Center Bahir extensions for Apache Spark MQTT – Enables reading data from MQTT Servers using Spark Streaming or Structured streaming. • http://bahir.apache.org/docs/spark/current/spark-sql-streaming-mqtt/ • http://bahir.apache.org/docs/spark/current/spark-streaming-mqtt/ Couch DB/Cloudant – Enables reading data from CouchDB/Cloudant using Spark SQL and Spark Streaming. Twitter – Enables reading social data from twitter using Spark Streaming. • http://bahir.apache.org/docs/spark/current/spark-streaming-twitter/ Akka – Enables reading data from Akka Actors using Spark Streaming or Structured Streaming. • http://bahir.apache.org/docs/spark/current/spark-streaming-akka/ ZeroMQ – Enables reading data from ZeroMQ using Spark Streaming. • http://bahir.apache.org/docs/spark/current/spark-streaming-zeromq/ 24
- 25. IBM SparkTechnology Center Bahir extensions for Apache Spark Google Cloud Pub/Sub – Add spark streaming connector to Google Cloud Pub/Sub • https://issues.apache.org/jira/browse/BAHIR-116 25
- 26. IBM SparkTechnology Center Apache Spark extensions in Bahir Adding Bahir extensions into your application • Using SBT • libraryDependencies += "org.apache.bahir" %% "spark-streaming-mqtt" % "2.2.0” • Using Maven • <dependency> <groupId>org.apache.bahir</groupId> <artifactId>spark-streaming-mqtt_2.11 </artifactId> <version>2.2.0</version> </dependency> 26
- 27. IBM SparkTechnology Center Apache Spark extensions in Bahir Submitting applications with Bahir extensions to Spark • Spark-shell • bin/spark-shell --packages org.apache.bahir:spark-streaming_mqtt_2.11:2.2.0 ….. • Spark-submit • bin/spark-submit --packages org.apache.bahir:spark-streaming_mqtt_2.11:2.2.0 ….. 27
- 28. IBM SparkTechnology Center IoT - Internet of Things 28
- 29. IBM SparkTechnology Center IoT – Definition by Wikipedia The Internet of things (IoT) is the network of physical devices, vehicles, home appliances, and other items embedded with electronics, software, sensors, actuators, and network connectivity which enable these objects to connect and exchange data. 29
- 30. IBM SparkTechnology Center IoT – Definition by Wikipedia The Internet of things (IoT) is the network of physical devices, vehicles, home appliances, and other items embedded with electronics, software, sensors, actuators, and network connectivity which enable these objects to connect and exchange data. 30
- 31. IBM SparkTechnology Center IoT – Interaction between multiple entities 31 Things Software People actuate inform
- 32. IBM SparkTechnology Center 32 Manufacturer Chipset Board Appliance Cloud Service provider Consumer IoT Platform Connectivity Security Analysis Management Integration IoT Ecosystem in a Nutshell
- 33. IBM SparkTechnology Center IoT Patterns – Some of them … 33 • Remote control • Security analysis • Edge analytics • Historical data analysis • Distributed Platforms • Real-time decisions
- 34. IBM SparkTechnology Center IoT Patterns – Real-time decisions 34 • Action is triggered if an anomaly (+/-) is identified • MTTR (mean time to repair) is critical • High throughput might hide real issue • QoS tradeoffs • Payload size and format
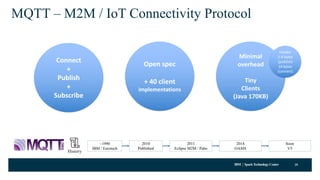
- 35. IBM SparkTechnology Center MQTT – M2M / IoT Connectivity Protocol 35 Connect + Publish + Subscribe ~1990 IBM / Eurotech 2010 Published 2011 Eclipse M2M / Paho 2014 OASIS Open spec + 40 client implementations Minimal overhead Tiny Clients (Java 170KB) History Header 2-4 bytes (publish) 14 bytes (connect) Soon V5
- 36. IBM SparkTechnology Center MQTT – Quality of Service 36 MQTT Broker QoS0 QoS1 QoS2 At most once At least once Exactly once . No connection failover . Never duplicate . Has connection failover . Can duplicate . Has connection failover . Never duplicate
- 37. IBM SparkTechnology Center MQTT – World usage Smart Home Automation Messaging Notable Mentions: • IBM IoT Platform • AWS IoT • Microsoft IoT Hub • Facebook Messanger 37
- 38. IBM SparkTechnology Center Live Demo 38
- 39. IBM SparkTechnology Center IoT Simulator using MQTT The demo environment https://github.com/lresende/bahir-iot-demo 39 Node.js Web app Simulates Elevator IoT devices Elevator simulator Metrics: • Weight • Speed • Power • Temperature • System MQTT Mosquitto
- 41. IBM SparkTechnology Center Summary – Take away points Apache Spark • IoT Analytics Runtime with support for ”Continuous Applications” Apache Bahir • Bring access to IoT data via supported connectors (e.g. MQTT) IoT Applications • Using Spark and Bahir to start processing IoT data in near real time using Spark Streaming and Spark Structured Streaming 41
- 42. IBM SparkTechnology Center Join the Apache Bahir community !!! 42
- 43. IBM SparkTechnology Center References Apache Bahir http://bahir.apache.org Documentation for Apache Spark extensions http://bahir.apache.org/docs/spark/current/documentation/ Source Repositories https://github.com/apache/bahir https://github.com/apache/bahir-website Demo Repository https://github.com/lresende/bahir-iot-demo 43 Image source: http://az616578.vo.msecnd.net/files/2016/03/21/6359412499310138501557867529_thank-you-1400x800-c-default.gif