Building Large-Scale Stream Infrastructures Across Multiple Data Centers with Apache Kafka
4 likes1,208 views

The document outlines strategies for building large-scale streaming infrastructures using Apache Kafka across multiple data centers (DCs). It discusses various patterns for data replication, such as stretched clusters, active/passive, and active/active, while addressing challenges like offset management during failovers. Additionally, it highlights considerations for resource utilization, security, and future enhancements related to offset preservation and timestamp indexing.




























Building Large-Scale Stream Infrastructures Across Multiple Data Centers with Apache Kafka
- 1. Jun Rao Confluent, Inc Building Large-Scale Stream Infrastructures Across Multiple Data Centers with Apache Kafka
- 2. Outline • Kafka overview • Common multi data center patterns • Future stuff
- 3. What’s Apache Kafka Distributed, high throughput pub/sub system
- 4. Kafka usage
- 5. Common use case • Large scale real time data integration
- 6. Other use cases • Scaling databases • Messaging • Stream processing • …
- 7. Why multiple data centers (DC) • Disaster recovery • Geo-localization • Saving cross-DC bandwidth • Security
- 8. What’s unique with Kafka multi DC • Consumers run continuous and have states (offsets) • Challenge: recovering the states during DC failover
- 9. Pattern #1: stretched cluster • Typically done on AWS in a single region • Deploy Zookeeper and broker across 3 availability zones • Rely on intra-cluster replication to replica data across DCs Kafka producers consumer s DC 1 DC 3DC 2 producersproducers consumer s consumer s
- 10. On DC failure Kafka producers consumer s DC 1 DC 3DC 2 producers consumer s • Producer/consumer fail over to new DCs • Existing data preserved by intra-cluster replication • Consumer resumes from last committed offsets and will see same data
- 11. When DC comes back • Intra cluster replication auto re-replicates all missing data • When re-replication completes, switch producer/consumer back Kafka producers consumer s DC 1 DC 3DC 2 producersproducers consumer s consumer s
- 12. Be careful with replica assignment • Don’t want all replicas in same AZ • Rack-aware support in 0.10.0 • Configure brokers in same AZ with same broker.rack • Manual replica assignment pre 0.10.0
- 13. Stretched cluster NOT recommended across regions • Asymmetric network partitioning • Longer network latency => longer produce/consume time • Across region bandwidth: no read affinity in Kafka region 1 Kafk a ZK region 2 Kafk a ZK region 3 Kafk a ZK
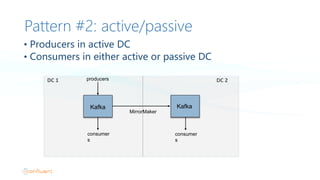
- 14. Pattern #2: active/passive • Producers in active DC • Consumers in either active or passive DC Kafka producers consumer s DC 1 MirrorMaker DC 2 Kafka consumer s
- 15. What’s MirrorMaker • Read from a source cluster and write to a target cluster • Per-key ordering preserved • Asynchronous: target always slightly behind • Offsets not preserved • Source and target may not have same # partitions • Retries for failed writes
- 16. On active DC failure • Fail over producers/consumers to passive cluster • Challenge: which offset to resume consumption • Offsets not identical across clusters Kafka producers consumer s DC 1 MirrorMaker DC 2 Kafka
- 17. Solutions for switching consumers • Resume from smallest offset • Duplicates • Resume from largest offset • May miss some messages (likely acceptable for real time consumers) • Set offset based on timestamp • Current api hard to use and not precise • Better and more precise api being worked on (KIP-33, KIP-79) • Preserve offsets during mirroring • Harder to do • No timeline yet
- 18. When DC comes back • Need to reverse mirroring • Similar challenge for determining the offsets in MirrorMaker Kafka producers consumer s DC 1 MirrorMaker DC 2 Kafka
- 19. Limitations • MirrorMaker reconfiguration after failover • Resources in passive DC under utilized
- 20. Pattern #3: active/active • Local aggregate mirroring to avoid cycles • Producers/consumers in both DCs • Producers only write to local clusters Kafka local Kafka aggregat e Kafka aggregat e producers producer s consumer s consumer s MirrorMaker Kafka local DC 1 DC 2 consumer s consumer s
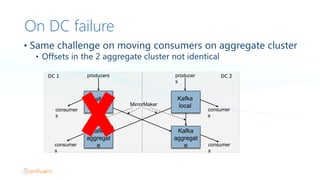
- 21. On DC failure • Same challenge on moving consumers on aggregate cluster • Offsets in the 2 aggregate cluster not identical Kafka local Kafka aggregat e Kafka aggregat e producers producer s consumer s consumer s MirrorMaker Kafka local DC 1 DC 2 consumer s consumer s
- 22. When DC comes back • No need to reconfigure MirrorMaker Kafka local Kafka aggregat e Kafka aggregat e producers producer s consumer s consumer s MirrorMaker Kafka local DC 1 DC 2 consumer s consumer s
- 23. Beyond 2 DCs • More DCs better resource utilization • With 2 DCs, each DC needs to provision 100% traffic • With 3 DCs, each DC only needs to provision 50% traffic • Setting up MirrorMaker with many DCs can be daunting • Only set up aggregate clusters in 2-3
- 24. Comparison Pros Cons Stretched • Better utilization of resources • Easy failover for consumers • Still need cross region story Active/passive • Needed for global ordering • Harder failover for consumers • Reconfiguration during failover • Resource under-utilization Active/active • Better utilization of resources • Harder failover for consumers • Extra aggregate clusters
- 25. Multi-DC beyond Kafka • Kafka often used together with other data stores • Need to make sure multi-DC strategy is consistent
- 26. Example application • Consumer reads from Kafka and computes 1-min count • Counts need to be stored in DB and available in every DC
- 27. Independent database per DC • Run same consumer concurrently in both DCs • No consumer failover needed Kafka local Kafka aggregat e Kafka aggregat e producers producer s consumer consumer MirrorMaker Kafka local DC 1 DC 2 DB DB
- 28. Stretched database across DCs • Only run one consumer per DC at any given point of time Kafka local Kafka aggregat e Kafka aggregat e producers producer s consumer consumer MirrorMaker Kafka local DC 1 DC 2 DB DB on failover
- 29. Other considerations • Enable SSL in MirrorMaker • Encrypt data transfer across DCs • Performance tuning • Running multiple instances of MirrorMaker • May want to use RoundRobin partition assignment for more parallelism • Tuning socket buffer size to amortize long network latency • Where to run MirrorMaker • Prefer close to target cluster
- 30. Future work • KIP-33, KIP-79: timestamp index • Allow consumers to seek based on timestamp • Integration with Kafka Connect for data ingestion • Offset preserving mirroring
- 31. 31Confidential THANK YOU! Jun Rao| [email protected] | @junrao Kafka Training with Confluent University • Kafka Developer and Operations Courses • Visit www.confluent.io/training Want more Kafka? • Download Confluent Platform Enterprise at http://www.confluent.io/product • Apache Kafka 0.10 upgrade documentation at http://docs.confluent.io/3.0.0/upgrade.html • Kafka Summit recordings now available at http://kafka-summit.org/schedule/
Editor's Notes
- #4: New theme. Picture/logo