


































C19013010 the tutorial to build shared ai services session 2
- 1. The tutorial to build shared AI services --Session 2 Suqiang Song (Jack) Director & Chapter Leader of Data/AI Engineering @ Mastercard [email protected] https://www.linkedin.com/in/suqiang-song-72041716/
- 2. Agenda Module 3: AI Engineering platform and AI Engineers ( 40 mins) • Key factors to consider an AI Engineering platform • architect a data pipeline framework • Apache NiFi introduction • Traditional AI Tribe and its challenges • knowledges and skills are required for AI Engineer • Growing path for an AI Engineer Session 2: Feb. 1rd Friday 10am-12pm PT Module 4: Benchmark between Spark Machine learning and Deep learning + Code Lab 2 (30 mins) • Traditional Collaborative Filtering approach with Spark Mllib ALS (Scala) • Build an NCF deep learning approach with Intel Analytic Zoo on Spark (Scala) Q & A (10 mins)Live Demo (40 mins) • Build an end to end AI Pipeline with Kafka, NiFi, Spark Streaming and Keras on Spark
- 3. Course Prerequisites • Install Docker at your local laptop • Download two Docker images from shared drive URL kafka.tar and demo-whole.tar and also demo_pipeline.xml passcode : jack • Load images to your Docker environment https://1drv.ms/f/s!AsXKHMXBWUIBiBpaYk9FFjdoUifg $ docker load -i demo-whole.tar $ docker load -i kafka.tar
- 4. Module 3
- 5. AI Engineering Organization/ProcessAPI/ Pipeline Enablement Talent Data Technology infrastructure ConsolidateLeverage Automate Key factors to consider an AI Engineering platform
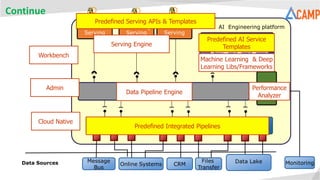
- 6. Continue AI Engineering platform ML /DL learning pipelines Historical + Incremental Data Sources Data Pipeline Bus Real Time Event Integration Batch Data Integration Business Rule Integration Online Systems CRM Files Transfer Data LakeMessage Bus Real Time Serving Streaming Serving Batch Serving Monitoring Metrics Serving Engine Data Pipeline Engine Machine Learning & Deep Learning Libs/Frameworks Performance Analyzer Predefined Integrated Pipelines Predefined Serving APIs & Templates Predefined AI Service Templates Workbench Admin Cloud Native
- 7. Data Flow Pipeline • Flow-based ”programming” • Source –Channel-Sink “structure” • Ingest Data from various sources and Transform data to various destinations • Extract – Transform – Load • High-Throughput, straight-through data flows • Data Governance • Combine Batch and Stream- Processing • Visual coding with flow editor • Event Processing (ESP & CEP)
- 8. The X(quality attributes) for data pipeline framework includes • Clustering • High Availability & Recovery • Delivery Guarantee • Data Buffering ,Flow Control and Back Pressure • Data Governance • Usability • Extensibility • Multi-Tenancy • Version Control & Deployment • Security • Monitoring & Diagnostic Capabilities • Integration Capabilities • Cloud Native • Performance , Latency and Throughputs Architect a data pipeline framework What is the DFX ? Along with functional requirements, there are various quality attributes. The difference in these attributes can make the product very different. Such as Tesla and Leaf DFX is Design For Quality Attributes
- 9. Example : High Availability and Recovery High availability – Pipeline level : Each step or processor at flow that is likely to encounter failures will have a "failure" routing relationship – Pipeline Failure is handled by looping that failure relationship back on the same step or to new steps – Node level failover will depends on a "cluster coordinator" and a "primary node" elected – Pipeline failover between nodes ? Recovery – Replay : Content repository should be designed to act as a rolling buffer of history which supports replay every well – Data Recovery after failover , the eventual consistency – Breakpoint resume : Last-saved offset , how you resume the pipeline from the broken pieces after fixed
- 10. Example : Data Buffering ,Flow Control and Back Pressure Buffering with Prioritization – Configure a prioritizer per connection, such as FirstInFristOut , NewestFirst,OldestFirst etc.. – Determine what is important for your data – time based, arrival order, importance of a data set – Funnel many connections down to a single connection to prioritize across data sets – Develop your own prioritizer if needed Flow Control & Back-Pressure – Configure back-pressure such as expiration, threshold for per connection – Based on number of flows or total size of flows – Upstream processor no longer scheduled to run until below threshold
- 11. Example : Security Control Plane – Pluggable authentication :2-Way SSL, LDAP, Kerberos – File-based authority provider out of the box – Multiple roles to defines access controls Data Plane – Optional 2-Way SSL between cluster nodes – Optional 2-Way SSL on Site-To-Site ( or Edge-to-Edge) connections – Encryption/Decryption of data through processors Data privacy and compliance – PCI/PII compliance – GDPR (General Data Protection Regulation) Yes , you don’t want your CEO to be testified before Congress ☺
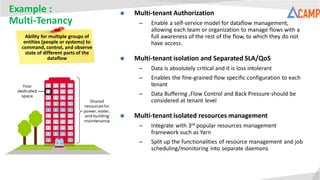
- 12. Example : Multi-Tenancy Ability for multiple groups of entities (people or systems) to command, control, and observe state of different parts of the dataflow Multi-tenant Authorization – Enable a self-service model for dataflow management, allowing each team or organization to manage flows with a full awareness of the rest of the flow, to which they do not have access. Multi-tenant isolation and Separated SLA/QoS – Data is absolutely critical and it is loss intolerant – Enables the fine-grained flow specific configuration to each tenant – Data Buffering ,Flow Control and Back Pressure should be considered at tenant level Multi-tenant isolated resources management – Integrate with 3rd popular resources management framework such as Yarn – Split up the functionalities of resource management and job scheduling/monitoring into separate daemons
- 14. Technology Assessment Score Definition
- 15. Clustering Assessment Score Ratings High Availability and Recovery 2 431 5 N NiFiN 2 431 5 N Delivery Guarantee 2 431 5 N Data Buffering ,Flow Control and Back Pressure 2 431 5 N Data Governance 2 431 5 N Usability 2 431 5 N Extensibility 2 431 5 N Multi-Tenancy 2 431 5 N Version Control & Deployment 2 431 5 N Authentication & Authorization 2 431 5 N Encryption and decryption 2 431 5 N Monitoring & Diagnostic 2 431 5 N Integration capabilities 2 431 5 N Cloud Native 2 431 5 N Performance, Latency and Throughputs (Real Time & Streaming) 2 431 5 N Performance, Latency and Throughputs (Batch files / DB actions ) 2 431 5 N
- 16. Ingest TransformAnalyze Output Understand Problem Ingest Data Explore and Understand Data Clean and Shape Data Evaluate Data Create and build Models Communicate Results Deliver & Deploy Model Data Engineer Architect how data is organized & ensure operability Data Scientist Deep analytics and modeling for hidden insights Business Analyst Work with data to apply insights to business strategy App Developer Integrates data & insights with existing or new applications Traditional AI Tribe
- 18. 4 4 4 4 4 3 3 0 1 2 3 4 ALGORITHM ML MODELING RESEARCH MATH STATISTICS HYPERTUNING FEATURE ENGINEERING 2 1 1 1 2 2 2 0 1 2 3 4 QA TROUBLE SHOOTING ABSTRACT THINKING DEBUGING DATA STRUCTURES UNIT TEST SOFTWARE ALGORITHM 1 1 1 3 4 0 1 2 3 4 SHELL/PERL C++ JAVA/SCALA PYTHON R 2 1 2 1 2 1 2 2 0 1 2 3 4 DATA MODELING DATA WAREHOUSING… SQL RDB & NOSQL ETL DATA GOVERNANCE DATA PIPELINE JOB/WORKFLOW 3 1 1 2 2 4 2 0 1 2 3 4 APPLIANCE(SCALE UP) DISTRIBUTE… KAFKA/STREAMING SPARK HADOOP SAS MPP Data Mining Programing / Coding Languages Data Engineering Big Data Stacks 3 3 2 3 4 2 2 2 0 1 2 3 4 PANDAS H2O SPARK MLLIB SCIKIT LEARN R LIB DL-CAFFE DL-KERAS DL-TENSORFLOW APIs /Services/App ( Model Serving) 1 1 1 1 1 1 1 0 1 2 3 4 AUTOMATION REAL TIME MESSAGING CACHE API/APP FRAMEWORK RPC/RESTFUL… CI/CD CLOUD NATIVE 3 4 3 2 2 3 0 1 2 3 4 DATA VISUALIZATION MODEL INTERPRETABILITY BUSINESS ACUMEN COMMUNICATION SKILLS BUSINESS ANALYSIS PRESENTATION Ratings for traditional data scientist ML/DL Frameworks Visualization & Communications
- 19. Ratings for traditional data engineer 1 1 1 2 1 1 2 0 1 2 3 4 ALGORITHM ML MODELING RESEARCH MATH STATISTICS HYPERTUNING FEATURE ENGINEERING 3 3 3 3 4 3 3 0 1 2 3 4 QA TROUBLE SHOOTING ABSTRACT THINKING DEBUGING DATA STRUCTURES UNIT TEST SOFTWARE ALGORITHM 4 2 3 3 1 0 1 2 3 4 SHELL/PERL C++ JAVA/SCALA PYTHON R 4 4 4 4 4 4 4 4 0 1 2 3 4 DATA MODELING DATA WAREHOUSING… SQL RDB & NOSQL ETL DATA GOVERNANCE DATA PIPELINE JOB/WORKFLOW 3 4 3 4 4 2 3 0 1 2 3 4 APPLIANCE(SCALE UP) DISTRIBUTE… KAFKA/STREAMING SPARK HADOOP SAS MPP Data Mining Programing / Coding Languages Data Engineering Big Data Stacks 2 1 2 2 1 2 2 2 0 1 2 3 4 PANDAS H2O SPARK MLLIB SCIKIT LEARN R LIB DL-CAFFE DL-KERAS DL-TENSORFLOW APIs /Services/App ( Model Serving) 3 2 2 3 3 3 3 0 1 2 3 4 AUTOMATION REAL TIME MESSAGING CACHE API/APP FRAMEWORK RPC/RESTFUL… CI/CD CLOUD NATIVE 2 1 2 1 1 2 0 1 2 3 4 DATA VISUALIZATION MODEL INTERPRETABILITY BUSINESS ACUMEN COMMUNICATION SKILLS BUSINESS ANALYSIS PRESENTATION ML/DL Frameworks Visualization & Communications
- 20. Ratings for traditional application developer 1 1 1 2 1 1 1 0 1 2 3 4 ALGORITHM ML MODELING RESEARCH MATH STATISTICS HYPERTUNING FEATURE ENGINEERING 3 4 4 4 3 4 4 0 1 2 3 4 QA TROUBLE SHOOTING ABSTRACT THINKING DEBUGING DATA STRUCTURES UNIT TEST SOFTWARE ALGORITHM 2 3 4 2 1 0 1 2 3 4 SHELL/PERL C++ JAVA/SCALA PYTHON R 2 1 3 3 2 2 2 3 0 1 2 3 4 DATA MODELING DATA WAREHOUSING… SQL RDB & NOSQL ETL DATA GOVERNANCE DATA PIPELINE JOB/WORKFLOW 1 1 2 1 1 1 1 0 1 2 3 4 APPLIANCE(SCALE UP) DISTRIBUTE… KAFKA/STREAMING SPARK HADOOP SAS MPP Data Mining Programing / Coding Languages Data Engineering Big Data Stacks 1 1 1 1 1 1 1 1 0 1 2 3 4 PANDAS H2O SPARK MLLIB SCIKIT LEARN R LIB DL-CAFFE DL-KERAS DL-TENSORFLOW APIs /Services/App ( Model Serving) 3 4 4 4 4 4 3 0 1 2 3 4 AUTOMATION REAL TIME MESSAGING CACHE API/APP FRAMEWORK RPC/RESTFUL… CI/CD CLOUD NATIVE 2 1 3 2 1 2 0 1 2 3 4 DATA VISUALIZATION MODEL INTERPRETABILITY BUSINESS ACUMEN COMMUNICATION SKILLS BUSINESS ANALYSIS PRESENTATION ML/DL Frameworks Visualization & Communications
- 21. Ratings for modern AI engineer 3 2 2 3 2 3 3 0 1 2 3 4 ALGORITHM ML MODELING RESEARCH MATH STATISTICS HYPERTUNING FEATURE ENGINEERING 3 4 4 3 4 3 4 0 1 2 3 4 QA TROUBLE SHOOTING ABSTRACT THINKING DEBUGING DATA STRUCTURES UNIT TEST SOFTWARE ALGORITHM 3 2 4 4 2 0 1 2 3 4 SHELL/PERL C++ JAVA/SCALA PYTHON R 3 3 3 3 3 3 4 3 0 1 2 3 4 DATA MODELING DATA WAREHOUSING… SQL RDB & NOSQL ETL DATA GOVERNANCE DATA PIPELINE JOB/WORKFLOW 3 4 4 4 4 2 3 0 1 2 3 4 APPLIANCE(SCALE UP) DISTRIBUTE… KAFKA/STREAMING SPARK HADOOP SAS MPP Data Mining Programing / Coding Languages Data Engineering Big Data Stacks 3 2 4 3 2 3 4 4 0 1 2 3 4 PANDAS H2O SPARK MLLIB SCIKIT LEARN R LIB DL-CAFFE DL-KERAS DL-TENSORFLOW APIs /Services/App ( Model Serving) 3 4 4 4 4 3 3 0 1 2 3 4 AUTOMATION REAL TIME MESSAGING CACHE API/APP FRAMEWORK RPC/RESTFUL… CI/CD CLOUD NATIVE 4 3 3 3 2 3 0 1 2 3 4 DATA VISUALIZATION MODEL INTERPRETABILITY BUSINESS ACUMEN COMMUNICATION SKILLS BUSINESS ANALYSIS PRESENTATION Visualization & Communications ML/DL Frameworks
- 22. AI EngineerAreas need enhancements Training / Improving approach Languages Deep Learning To be expert , from bottom to the top Use Deep Learning to avoid the gap Spark ***** Hadoop *** 6 months certificate Plus Data Engineering Big Data Stacks API /Application Design and implement Essentials Model Serving Programing Course or Hands on project , no need a CS MasterProgramming / Coding Java/ Scala ++ ,Python + Growing path 1 : traditional data scientist - > AI Engineer
- 23. AI EngineerAreas need enhancements Training / Improving approach Languages ML Framework Deep Learning Visualization , Communication Skills Presentation Visualization & Communication API /Application Design and implement Advanced Model Serving Secondary DS/BA Master At least 6 months certificate Use Deep Learning to simply Data Mining Java/ Scala + ,Python +,R ++ Fast.ai ,GitHub , Kaggle, Coursera /Udemy At least 6 months DL certificate Growing path 2 : traditional data engineer - > AI Engineer
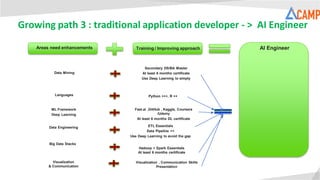
- 24. AI EngineerAreas need enhancements Training / Improving approach Languages Fast.ai ,GitHub , Kaggle, Coursera /Udemy At least 6 months DL certificate ETL Essentials Data Pipeline ++ Use Deep Learning to avoid the gap Hadoop + Spark Essentials At least 6 months certificate Data Engineering Big Data Stacks Python +++, R ++ Secondary DS/BA Master At least 6 months certificate Use Deep Learning to simply Data Mining ML Framework Deep Learning Visualization , Communication Skills Presentation Visualization & Communication Growing path 3 : traditional application developer - > AI Engineer
- 25. Module 4+ Code Lab2 https://github.com/jack1981/AaaSDemo
- 26. Collaborative Filtering -- concept
- 27. Spark Mllib ALS NCF on Spark Collaborative Filtering -- Model selection Spark Mllib KMeans
- 28. • Offers a set of parallelized machine learning algorithms for ML • Supports Model Selection (hyper parameter tuning) using Cross Validation and Train-Validation Split. • Supports Java, Scala or Python apps using Data Frame-based API Enables Parallel, Distributed ML for large datasets on Spark Clusters Spark Mllib
- 30. Spark Mllib ML Pipeline DataFrame: Spark ML uses DataFrame rather than regular RDD as they hold a variety of data types (e.g. feature vectors, true labels, and predictions). Transformer: a transformer converts a DataFrame into another DataFrame usually by appending columns. (since Spark DataFrame is immutable, it actually creates a new DataFrame). The implement method for a transformer is “transform()”. Estimator: An Estimator is an algorithm which can be fit on a DataFrame to produce a Transformer. Implements method fit() taking a DataFrame and a model (also a transformer) as input. Pipeline: Chains multiple Transformers and Estimators each as a stage to specify an ML workflow. These stages are run in order, and the input DataFrame is transformed as it passes through each stage. Parameter: All Transformers and Estimators now share a common API for specifying parameters. Evaluator: Evaluate model performance. The Evaluator can be • RegressionEvaluator for regression problems, • BinaryClassificationEvaluator for binary data, or • MulticlassClassificationEvaluator for multiclass problems.
- 31. Alternating Least Squares (ALS) Spark ML
- 32. Collaborative Filtering -- Trade Offs Cluster Based MF Based Cluster +MF Based Deep Learning (CPU)
- 33. Code Time !
- 34. Live Demo (Build an end to end AI Pipeline with Kafka, NiFi, Spark Streaming and Keras on Spark)
- 35. Kafka
- 36. Livy
- 37. Spark Streaming
- 38. Q & A