





![7
Classical CPU pipeline
[DLX]
SIMD (vector) pipeline –
operates on closely located
data
SIMT pipeline with a bundle
of 4 threads
SPMD contains a
combination of
(SIMD&SIMT)
Types of data-level parallelism
MEMFE DE EX WB
MEMFE DE EX WB
EXEXEXMEM
EXEXEXEXFE DE
EXEXEXWB
Typically all are present in GPUs](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-7-320.jpg)



![11
A bundle (subgroup in OpenCL) of threads has to execute the
same PC in lock step
All threads in the bundle have to go through instructions in
divergent branches (even when condition evaluates to false)
Similar to predicated execution
Inefficient because more time is spent to execute the whole program
Do all GPUs execute instructions in lock step? Mali-T6xx has
separate PC for each thread [IWOCL]
Lockstep execution (SIMT)
Divergence issue
if (thread_id==0)
r3 = r1+r2;
else
r3 = r1-r2;
r4 = r0 * r3
Thread 0 Thread 1 Thread 2 Thread 4
ADD r1 r2 ACTIVE INACTIVE INACTIVE INACTIVE
SUB r1 r2 INACTIVE ACTIVE ACTIVE ACTIVE
MUL r0 r3 ACTIVE ACTIVE ACTIVE ACTIVE
Bundle of 4 threads executing in lock step
Time
Each thread executes 3 instr instead of 2](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-11-320.jpg)


![15
kernel void foo(global int* buf){
int tid = get_global_id(0) *
get_global_size(1) +
get_global_id(1);
buf[tid] = cos(tid);
}
OpenCL program
Starting from C99
+ Keywords (specify kernels
i.e.parallel work items,
address spaces (AS) to allocate objects
to mem e.g.global,local,private …)
+ Builtin functions and types
- Disallowed features
(function pointers,recursion, C std
includes)](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-15-320.jpg)
![16
kernel void foo(global int* buf){
int tid = get_global_id(0) *
get_global_size(1) +
get_global_id(1);
buf[tid] = cos(tid);
}
for (int i = 0; i<DIM1; i++)
for (int j = 0; j<DIM2; j++)
std::thread([i, j, buf]() {
int tid = i*DIM2 + j;
buf[tid] = cos(tid);
}
OpenCL program
Starting from C99
+ Keywords (specify kernels
i.e.parallel work items,
address spaces (AS) to allocate objects
to mem e.g.global,local,private …)
+ Builtin functions and types
- Disallowed features
(function pointers,recursion, C std
includes)
DIM1
DIM2](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-16-320.jpg)
![17
kernel void foo(global int* buf){
int tid = get_global_id(0) *
get_global_size(1) +
get_global_id(1);
buf[tid] = cos(tid);
}
for (int i = 0; i<DIM1; i++)
for (int j = 0; j<DIM2; j++)
std::thread([i, j, buf]() {
int tid = i*DIM2 + j;
buf[tid] = cos(tid);
}
OpenCL program
Starting from C99
+ Keywords (specify kernels
i.e.parallel work items,
address spaces (AS) to allocate objects
to mem e.g.global,local,private …)
+ Builtin functions and types
- Disallowed features
(function pointers,recursion, C std
includes)
DIM1
DIM2
C99
OpenCL](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-17-320.jpg)



![21
Example:
float cos (float x) __attribute((overloadable))
double cos(double x) __attribute((overloadable))
Many builtin functions have multiple prototypes i.e.overloads
(supported in C via __attribute((overloadable)))
OpenCL header is 20K lines of declarations
Automatically loaded by compiler (no #include needed)
Affects parse time
To speedup parsing – Precompiled Headers (PCHs) [PCH]
has large size ~ 2Mb for OpenCL header
Size affects memory consumed and disk space
BUT some types and functions require special compiler
support…
Builtin functions and types](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-21-320.jpg)








![31
1: if (tid == 0) c = a[i + 1]; // compute address of array element = load address of a and
compute the offset (a+1) => 2 instr, only 1 thread active
2: if (tid != 0) e = a[i + 2];// as in line 1- 2 instr for address computation (a+2) all threads other
than thread 0
Transformed into:
1: p = &a[i + 1]; // load address of a and compute the offset => 2 instr all threads
2: if (tid == 0) c = *p; // only thread 0 will perform this computation
3: q = &a[i + 2]; // address of a is loaded on line 3 thus only offset is to be computed (CSE
optimisation) => 1 instr all threads
4: if (tid != 0) e = *q; // all threads other than thread 0 will run this
In SPMT all lines of code will be executed, therefore the transformed program
will run 1 instr less (the transformed code will run longer for a single thread)
Optimizations for SPMD
Speculative execution](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-31-320.jpg)
![32
Exploring different types of parallelism
SPMD vs SIMD
r0= load
r1= load
r1=r0+r1
r0= load
r1= load
r1=r0+r1
r0= load
r1= load
r1=r0+r1
int *a, *b, c;
…
a[tid] = b[tid] + c;
r0= load
r1= load
r1=r0+r1
int2 *a, *b, c;
;…
//a vector operation
is performed with
multiple elements at
once
a[tid] = b[tid] + c;
Is it always good to vectorize?
Speed up if fewer
threads are created
while each thread
execution time
remains the same](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-32-320.jpg)
![33
Exploring different types of parallelism
SPMD vs SIMD
r0= load
r1= load
r1=r0+r1
r0= load
r1= load
r1=r0+r1
r0= load
r1= load
r1=r0+r1
int *a, *b, c;
…
a[i] = b[i] + c;
r0= load
r1= load
r1=r0+r1
int2 *a, *b, c;
;…
//a vector operation
is performed with
multiple elements at
once
a[i] = b[i] + c;
Is it always good to vectorize?
Speed up if fewer
threads are created
while each thread
execution time
remains the same
What if the computation of c (calling some builtin functions)
results in many instructions that have to be duplicated in a
vectorized kernel:
vectorized application longer threads by 100 cycles
c = builtin100cysles(x)
c.s1 = builtin100cysles(x1);
c.s2 = builtin100cysles(x2)](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-33-320.jpg)


![36
How many registers to allocate for the kernel
Using more registers reduces spilling (storing to/loading from memory)
by keeping data in a register
For GPUs #REGs can affect amount of threads that can be
created because all registers are shared and allocated to threads
before scheduling them (Waiting -> Ready transition)
Thread interleaving reduces idle time while waiting for result
Example RA tread off - 1024 registers in total
Allocate 4 REGs with 20 spills and run max 256 threads to mask blocking
Allocate 16 REGs with 5 spills and run max 64 threads to mask blocking
More information in
Occupancy in RegisterAllocation
[OPT]](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-36-320.jpg)

![38
Fixed pipeline with programmable functionality
Evolved from very fixed functionality to highly programmable
components by writing shaders (in C like syntax - OpenGL)
Evolving towards unifying graphics and compute - Vulkan [VUL]
Sometimes requires less accuracy as soon as visualization is
correct and therefore alternative optimizations are possible
Harder to estimate the workload
What about graphics?
Geometry
(Vertexes)
Vertex
Shader
Fragment
Shader
BlenderRasterizer
A boundary
between vertex and
pixel processing](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-38-320.jpg)

![40
[DLX] https://en.wikipedia.org/wiki/DLX
[IWOCL] http://www.iwocl.org/wp-content/uploads/iwocl-2014-
workshop-Tim-Hartley.pdf
[PCH] http://clang.llvm.org/docs/PCHInternals.html
[OPT] https://www.cvg.ethz.ch/teaching/2011spring/gpgpu/GPU-
Optimization.pdf
[VUL] https://www.khronos.org/vulkan/
References](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-40-320.jpg)














Challenges in GPU compilers
- 1. 1 Challenges in GPU compilers Anastasia Stulova, ARM Guest lecture on Modern Compiler Design Cambridge University November 9th,2016
- 2. 2 About me: I work on OpenCL/GPU compilers in Media Processing Group (MPG), ARM ARM (www.arm.com) is a leader in low-power microprocessor IP MPG’s main product is mobile Mali GPU http://www.arm.com/products/graphics-and-multimedia/mali-gpu Among others we support OpenCL and OpenGL standards We work with the open source LLVM framework (llvm.org) I am the code maintainer of OpenCL in the Clang frontend (clang.llvm.org) Intro
- 3. 3 GPU – graphics processing unit GPGPU – general purpose GPU ISA – instruction set architecture PC – program counter IPC – instructions per cycle AST – abstract syntax tree SIMD – single instruction multiple data SIMT – single instruction multiple threads SPMD – single program multiple data CSE – common sub-expression elimination CFG – control flow graph FSM – finite state machine Abbreviations
- 4. 4 Brief history of GPUs What makes GPUs special? How to program GPUs? Writing a GPU compiler Supporting new language features – Front-end Optimizing for GPUs – Middle-end Mapping to GPU HW – Back-end A few words about graphics Summary Outline
- 5. 5 Initially created in 70s as highly compute capable HW accelerators to achieve required rendering speed in FPS (frame per second) The GPU programmability started growing to support different needs e.g.various games,GUIs, etc GPUs started offering programmability similar to regular processors In 2007 Nvidia launched CUDA to support fully programmable GPUs from C like syntax (exposing ISA,registers,pipeline), marking the beginning of widespread GPGPU era Nowadays any program that contains a massive amount of data level parallelism can be mapped efficiently to GPU Brief GPU history
- 6. 6 Massive data-level parallelism Comparison CPU vs GPU Lockstep execution What makes GPUs special?
- 7. 7 Classical CPU pipeline [DLX] SIMD (vector) pipeline – operates on closely located data SIMT pipeline with a bundle of 4 threads SPMD contains a combination of (SIMD&SIMT) Types of data-level parallelism MEMFE DE EX WB MEMFE DE EX WB EXEXEXMEM EXEXEXEXFE DE EXEXEXWB Typically all are present in GPUs
- 8. 8 On a GPU all cores execute the same set of instructions but not necessarily at the same point in time – SPMD model (separate pipelines don’t synchronize) Parallelism in CPU vs GPU Program for CPU Core1Core2 instrN instrN+1 … instr1 instr2 … Instr N-1 Program for GPU instr1 instr2 … instrN instrN+1 … Dozens of threads Thousands to millions of threads On a CPU different cores execute a completely different unrelated set of instructions
- 9. 9 CPU vs GPU performance LD1: r0= load LD2: r1= load ADD: r1=r0+r1 … Time CPU pipeline w 4 stages S1 S2 S3 S4 LD1 LD2 LD1 LD2 LD1 LD2 LD1 LD2 ADD:T1
- 10. 10 LD1: r0= load LD2: r1= load ADD: r1=r0+r … GPU can switch fast between threads, achieved by putting extra resources (i.e. thousands of registers) Switching threads in CPU costs thousands to millions of cycles Recall GPU pipeline picture: each Tn is typically a bundle of threads (each threads travels along 1 lane of the pipeline) CPU vs GPU performance LD1: r0= load LD2: r1= load ADD: r1=r0+r … S1 S2 S3 S4 LD1:T1 LD2:T1 LD1:T1 LD1:T2 LD2:T1 LD1:T1 LD2:T2 LD1:T2 LD2:T1 LD1:T1 LD1:T3 LD2:T2 LD1:T2 LD2:T1 LD2:T3 LD1:T3 LD2:T2 LD1:T2 ADD:T1 LD2:T3 LD1:T3 LD2:T2 LD1: r0= load LD2: r1= load ADD: r1=r0+r1 … Throughput = 1/3 IPC Throughput = 1 IPC Time Resume T1 (if more threads available,GPU could decide to schedule new threads) CPU pipeline w 4 stages T1 T2 T3 GPU pipeline w 4 stages S1 S2 S3 S4 LD1:T1 LD2:T1 LD1:T1 LD2:T1 LD1:T1 LD2:T1 LD1:T1 LD2:T1 ADD:T1
- 11. 11 A bundle (subgroup in OpenCL) of threads has to execute the same PC in lock step All threads in the bundle have to go through instructions in divergent branches (even when condition evaluates to false) Similar to predicated execution Inefficient because more time is spent to execute the whole program Do all GPUs execute instructions in lock step? Mali-T6xx has separate PC for each thread [IWOCL] Lockstep execution (SIMT) Divergence issue if (thread_id==0) r3 = r1+r2; else r3 = r1-r2; r4 = r0 * r3 Thread 0 Thread 1 Thread 2 Thread 4 ADD r1 r2 ACTIVE INACTIVE INACTIVE INACTIVE SUB r1 r2 INACTIVE ACTIVE ACTIVE ACTIVE MUL r0 r3 ACTIVE ACTIVE ACTIVE ACTIVE Bundle of 4 threads executing in lock step Time Each thread executes 3 instr instead of 2
- 12. 12 GPGPU programming model (OpenCL terminology) www.khronos.org/opencl OpenCL language How to program for GPGPUs?
- 13. 13 GPGPU programming (OpenCL terminology) C/C++ Host (CPU) Hotspot - Kernel
- 14. 14 WI – work-item is a single sequential unit of work with its private memory (PM) defined by a kernel in OpenCL language WG – work-group is a collection ofWIs that can run in parallel on the same core (sharing the same pipeline) and access local memory shared among allWIs in the same WG Different memories can have different access time GPGPU programming (OpenCL terminology) - Creates program for parallel computations on Device - Cross compiles for Device - Sends work to Device - Copy data to/from Device global memory Device (GPU) WG : WI Local Mem PM WI PM WI PM WG : WI Local Mem PM WI PM WI PM Global Memory C/C++ OpenCL API OpenCL Language Host (CPU) Hotspot - Kernel
- 15. 15 kernel void foo(global int* buf){ int tid = get_global_id(0) * get_global_size(1) + get_global_id(1); buf[tid] = cos(tid); } OpenCL program Starting from C99 + Keywords (specify kernels i.e.parallel work items, address spaces (AS) to allocate objects to mem e.g.global,local,private …) + Builtin functions and types - Disallowed features (function pointers,recursion, C std includes)
- 16. 16 kernel void foo(global int* buf){ int tid = get_global_id(0) * get_global_size(1) + get_global_id(1); buf[tid] = cos(tid); } for (int i = 0; i<DIM1; i++) for (int j = 0; j<DIM2; j++) std::thread([i, j, buf]() { int tid = i*DIM2 + j; buf[tid] = cos(tid); } OpenCL program Starting from C99 + Keywords (specify kernels i.e.parallel work items, address spaces (AS) to allocate objects to mem e.g.global,local,private …) + Builtin functions and types - Disallowed features (function pointers,recursion, C std includes) DIM1 DIM2
- 17. 17 kernel void foo(global int* buf){ int tid = get_global_id(0) * get_global_size(1) + get_global_id(1); buf[tid] = cos(tid); } for (int i = 0; i<DIM1; i++) for (int j = 0; j<DIM2; j++) std::thread([i, j, buf]() { int tid = i*DIM2 + j; buf[tid] = cos(tid); } OpenCL program Starting from C99 + Keywords (specify kernels i.e.parallel work items, address spaces (AS) to allocate objects to mem e.g.global,local,private …) + Builtin functions and types - Disallowed features (function pointers,recursion, C std includes) DIM1 DIM2 C99 OpenCL
- 18. 18 General strategy Supporting new languages – OpenCL example Optimising for GPUs Mapping to GPU HW Compilation for GPUs
- 19. 19 General compiler philosophy OpenCL has a lot in common with C Syntax,types,operators,functions GPU has some similarity to CPU ISA, registers,pipeline Can we reuse existing compiler technologies? Extension of C parser Take existing IR formats Borrow functionality of other backends Integrate all the components in the same way
- 20. 20 Supporting many new builtin types and functions Compiler extensions for builtin types and functions - pipe example Adding address space qualifiers Supporting new languages – OpenCL example Frontend aspects
- 21. 21 Example: float cos (float x) __attribute((overloadable)) double cos(double x) __attribute((overloadable)) Many builtin functions have multiple prototypes i.e.overloads (supported in C via __attribute((overloadable))) OpenCL header is 20K lines of declarations Automatically loaded by compiler (no #include needed) Affects parse time To speedup parsing – Precompiled Headers (PCHs) [PCH] has large size ~ 2Mb for OpenCL header Size affects memory consumed and disk space BUT some types and functions require special compiler support… Builtin functions and types
- 22. 22 Compiler support - Pipe Classical streaming pattern Host (C/C++) code sets up pipe and connections to kernels OpenCL code specifies how elements are written/read Standard C parser won’t offer functionality to support pipe kernel void producer(write_only pipe int p) { int i = …; write_pipe(p,&i); } kernel void consumer(read_only pipe int p) { int i ; read_pipe(p,&i); } Device pipe = clCreatePipe(context, 0, sizeof(int), 10 /* # packets*/…); producer = clCreateKernel(program, “producer”, &err); consumer = clCreateKernel(program, “consumer”, &err); // Set up connections err = clSetKernelArg (producer, 0, sizeof(pipe), pipe); err = clSetKernelArg (consumer, 0, sizeof(pipe), pipe); // Send work for execution on the device err = clEnqueueNDRangeKernel(queue, producer, …); err = clEnqueueNDRangeKernel(queue, consumer, …); Host
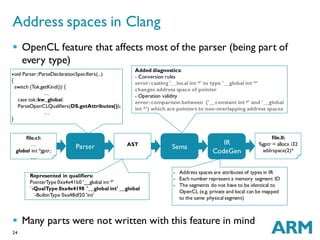
- 23. 23 Pipe type specifier requires special compiler support Pipe builtin functions:int read_pipe (read_only pipe gentype p, gentype *ptr) gentype is any builtin or user defined type Generic programming style behaviour in C99 needed Implemented as an internal Clang builtin function with custom generic programming support Semantical analysis for pipe: error:type 'pipe' can only be used as a function parameter in OpenCL Pipe type implementation in Clang file.cl: … pipe int p; … NewAST type node: PipeType 0xa4e41b0 ‘pipe int‘ `-BuiltinType 0xa48df20 'int' file.ll: %opencl.pipe_t = type opaque … %opencl.pipe_t* %p Parser AST Sema IR CodeGen void Parser::ParseDeclarationSpecifiers(DeclSpec &DS…) { … switch (Tok.getKind()) { … case tok::kw_pipe: … isInvalid = DS.SetTypePipe(true, …); break;
- 24. 24 OpenCL feature that affects most of the parser (being part of every type) Many parts were not written with this feature in mind Represented in qualifiers: PointerType 0xa4e41b0 '__global int *' `-QualType 0xa4e4198 '__global int' __global `-BuiltinType 0xa48df20 'int' Added diagnostics: - Conversion rules error:casting '__local int *' to type '__global int *‘ changes address space of pointer - Operation validity error:comparison between ('__constant int *' and '__global int *') which are pointers to non-overlapping address spaces Address spaces in Clang file.cl: … global int *gptr; … Parser void Parser::ParseDeclarationSpecifiers(...) { switch (Tok.getKind()) { … case tok::kw_global: ParseOpenCLQualifiers(DS.getAttributes()); … } AST Sema IR CodeGen - Address spaces are attributes of types in IR - Each number represent a memory segment ID - The segments do not have to be identical to OpenCL (e.g. private and local can be mapped to the same physical segment) file.ll: %gptr = alloca i32 addrspace(2)*
- 25. 25 Do traditional optimisations always work for GPUs? Optimisation for SPMD/SIMT Exploring different parallelism granularity via vectorization Optimising for GPUs Middle-end aspects
- 26. 26 Shorter programs are still faster => sequential code optimizations are still important BUT some single-thread optimizations might reduce the number of concurrent threads that can run in parallel or might prevent parallel access to memory A good trade off needs to be found because we do not always need each thread to run as fast as possible (HW can be filled with other threads at nearly 0 cost) There is still an overhead of maintaining threads Reducing #threads by coarsening might be beneficial in some situations Increased complexity and need of different considerations while optimizing - heuristics are typically good at optimizing one thing Hence iterative compilations or machine learning might be helpful… Optimizing for GPUs
- 27. 27 r1 = … if (r0) r1 = computeA(); // shuffle data from r1 into r3 // of threads id r2. T0:r1 T1:r1 T2:r1 T3:r1 T0:r3 T1:r3 T2:r3 T3:r3 r3 = sub_group_shuffle(r1,r2); if (r0) r3 = computeB(); Erroneous sequential optimizations for SIMT
- 28. 28 r1 = … if (r0) r1 = computeA(); // shuffle data from r1 into r3 // of threads id r2. T0:r1 T1:r1 T2:r1 T3:r1 T0:r3 T1:r3 T2:r3 T3:r3 r3 = sub_group_shuffle(r1,r2); if (r0) r3 = computeB(); r1 = … if (!r0) // Incorrectfunctionality!The data in r1 // have not been computed by all threadsyet. r3 = sub_group_shuffle(r1,r2); else { r1 = computeA(); r3 = sub_group_shuffle(r1,r2); r3 = computeB(); } Erroneous sequential optimizations for SIMT After valid sequential code transformation to reduce #branches r0!=0 r1==0
- 29. 29 Observation:transformations should maintain control flow wrt sub_group_shuffle as in the original program LLVM solution:mark such functions with special “convergent” attribute r1 = … if (r0) r1 = computeA(); // shuffle data from r1 into r3 // of threads id r2. T0:r1 T1:r1 T2:r1 T3:r1 T0:r3 T1:r3 T2:r3 T3:r3 r3 = sub_group_shuffle(r1,r2); if (r0) r3 = computeB(); r1 = … if (!r0) // Incorrectfunctionality!The data in r1 // have not been computed by all threadsyet. r3 = sub_group_shuffle(r1,r2); else { r1 = computeA(); r3 = sub_group_shuffle(r1,r2); r3 = computeB(); } Erroneous sequential optimizations for SIMT After valid sequential code transformation to reduce #branches r0!=0 r1==0
- 30. 30 Definition of domination/post-domination of nodes in CFG? Example:A dom B, C post-dom B CFG G´ is equivalent to G wrt Ni: iff ∀ Nj (i≠j) dom and post- dom relations wrt Ni remain the same in both G and G´ Example:A valid transformation can swapA1 and A2 in case it is beneficial to do so (no other valid transformations exist) Fixing wrong optimizations Control flow equivalence A1 A2 B C After the transformation,B is control equivalent to all other nodes B is a convergent operation A2 A1 B C A2 A1 B C Wrong: A2 no longer dominates B
- 31. 31 1: if (tid == 0) c = a[i + 1]; // compute address of array element = load address of a and compute the offset (a+1) => 2 instr, only 1 thread active 2: if (tid != 0) e = a[i + 2];// as in line 1- 2 instr for address computation (a+2) all threads other than thread 0 Transformed into: 1: p = &a[i + 1]; // load address of a and compute the offset => 2 instr all threads 2: if (tid == 0) c = *p; // only thread 0 will perform this computation 3: q = &a[i + 2]; // address of a is loaded on line 3 thus only offset is to be computed (CSE optimisation) => 1 instr all threads 4: if (tid != 0) e = *q; // all threads other than thread 0 will run this In SPMT all lines of code will be executed, therefore the transformed program will run 1 instr less (the transformed code will run longer for a single thread) Optimizations for SPMD Speculative execution
- 32. 32 Exploring different types of parallelism SPMD vs SIMD r0= load r1= load r1=r0+r1 r0= load r1= load r1=r0+r1 r0= load r1= load r1=r0+r1 int *a, *b, c; … a[tid] = b[tid] + c; r0= load r1= load r1=r0+r1 int2 *a, *b, c; ;… //a vector operation is performed with multiple elements at once a[tid] = b[tid] + c; Is it always good to vectorize? Speed up if fewer threads are created while each thread execution time remains the same
- 33. 33 Exploring different types of parallelism SPMD vs SIMD r0= load r1= load r1=r0+r1 r0= load r1= load r1=r0+r1 r0= load r1= load r1=r0+r1 int *a, *b, c; … a[i] = b[i] + c; r0= load r1= load r1=r0+r1 int2 *a, *b, c; ;… //a vector operation is performed with multiple elements at once a[i] = b[i] + c; Is it always good to vectorize? Speed up if fewer threads are created while each thread execution time remains the same What if the computation of c (calling some builtin functions) results in many instructions that have to be duplicated in a vectorized kernel: vectorized application longer threads by 100 cycles c = builtin100cysles(x) c.s1 = builtin100cysles(x1); c.s2 = builtin100cysles(x2)
- 34. 34 HW resources, occupancy and thread lifecycles Occupancy in register allocation Mapping to instructions Mapping to GPU HW Backend aspects
- 35. 35 HW will try to put as many threads inflight as possible if there is enough HW available for their execution to completion If all available resources are occupied,threads will wait to be accepted for execution on GPU Thus thread states can be described by FSM: Occupancy and thread categorization Ready Waiting to be scheduled Active In GPU pipeline Completed Ended execution Blocked Waiting To be admitted for execution Waiting for resources to be available
- 36. 36 How many registers to allocate for the kernel Using more registers reduces spilling (storing to/loading from memory) by keeping data in a register For GPUs #REGs can affect amount of threads that can be created because all registers are shared and allocated to threads before scheduling them (Waiting -> Ready transition) Thread interleaving reduces idle time while waiting for result Example RA tread off - 1024 registers in total Allocate 4 REGs with 20 spills and run max 256 threads to mask blocking Allocate 16 REGs with 5 spills and run max 64 threads to mask blocking More information in Occupancy in RegisterAllocation [OPT]
- 37. 37 Code is often inlined and unrolled (to exploit SIMD) and therefore big basic blocks are produced IR uses large number of intrinsics for implementing builtin functions and custom operations Exotic and complex instructions lead to many more possibilities in instruction selection phase The above factors have a negative impact on compilation time (critical for doing it at runtime) Mapping to instructions and compilation time * + r3 = ADD r1 r2 r4 = MUL r3 r5Common case from matrix multiplication r4 = FMA r1 r2 r3OR
- 38. 38 Fixed pipeline with programmable functionality Evolved from very fixed functionality to highly programmable components by writing shaders (in C like syntax - OpenGL) Evolving towards unifying graphics and compute - Vulkan [VUL] Sometimes requires less accuracy as soon as visualization is correct and therefore alternative optimizations are possible Harder to estimate the workload What about graphics? Geometry (Vertexes) Vertex Shader Fragment Shader BlenderRasterizer A boundary between vertex and pixel processing
- 39. 39 Reusing existing compilers helps shorten development time and avoid reinventing the same techniques Compilation approaches suitable for GPUs are emerging Many grew in a very ad hoc way,combining many concepts, and moving rapidly in different directions New challenges to come: Supporting new standards (including C++) and new use cases (computer vision, deep learning) Convergence between graphics and compute Increase compilation speed Explore alternative optimization strategies that can take both single and multi-threaded performance into account Summary
- 40. 40 [DLX] https://en.wikipedia.org/wiki/DLX [IWOCL] http://www.iwocl.org/wp-content/uploads/iwocl-2014- workshop-Tim-Hartley.pdf [PCH] http://clang.llvm.org/docs/PCHInternals.html [OPT] https://www.cvg.ethz.ch/teaching/2011spring/gpgpu/GPU- Optimization.pdf [VUL] https://www.khronos.org/vulkan/ References
- 42. 42 v1.0 v1.2 v2.0 v2.1 CL Next OpenCL evolution Core part of the language and API (operationsand types taken from C, special types - images,samplers,events; builtin functions:math and many more,address spaces) Allows linking of separate modules + adds more type and builtin functions Improves interaction between host and device:dynamic parallelism (GPU creates new workloads),program scope variables,streaming communicationsamong kernels - pipes (bypassinghost),shared virtual memory amonghost and all devices C++ Support
- 43. 43 Transforms program from source language into representation suitable for compiler analysis and transformations Interface with programmers about wrong use of language and flags potential errors in the source code error:use of undeclared identifier 'c' Frontend What does it do? d = a*b + c t1 = load a t2 = load b t3 = load c t4 = mul t1, t2 t5 = add t3, t4
- 44. 44 Clang parser is not always suitable forAS rules of OpenCL Example:defaultAS NULL literal has to be AS agnostic to be used interchangably: NULL = (void*)0 Recursive Descent parsing of NULL ParseExpr() ParseCastExpr() ParseType() ParseExpr() … ParseNullLiteral() Hence NULL is assigned to the default AS Workaround by custom checks of NULL in semantical cheks Default address space Scope Type global local pointer LangAS::generic LangAS::generic scalar LangAS::global LangAS::private Not known that NULL object is being parsed
- 45. 45 Map CL to C11 atomic types: Sema.cpp - Sema::Initialize(): // typedef _Atomic int atomic_int addImplicitTypedef("atomic_int",Context.getAtomicType(Context.IntTy)); Only subset of types are allowed Added Sema checks to restrict operations (only allowed through builtin functions): atomic_int a,b; a+b; // disallowed in CL _Atomic int a,b; a+b; // allowed in C11 Use C11 builtin functions to implement CL2.0 functions Missing memory visibility scope as LLVM doesn’t have this construct C atomic_exchange_explicit(volatile A *obj,C desired,memory_orderorder,memory_scope scope);// CL C atomic_exchange_explicit(volatile A *obj,C desired,memory_orderorder);// C11 Can be added as metadata or IR extension Atomic types if (getLangOpts().OpenCL) //The only legal unary operation for atomics is '&'. if (Opc != UO_AddrOf&& InputExpr->getType()->isAtomicType()) return ExprError(…);
- 46. 46 OpenCL builtin function enqueue_kernel(…,void (^block)(local void *,...)) block has an ObjC syntax (a lambda function with captures) block can have any number of local void* arguments Kind of variadic prototype No standard compilation approach To diagnose correctly it was added as Clang builtin function with a custom check Dynamic parallelism support
- 47. 47 Optimizations Transformation (preparing/making program more suitable for backend - lowering) Ideally target agnostic but not in reality! Middleend What does it do? t1 = add a 2 t2 = sub b 1 t3 = add t1 t2 t1 = add a 1 t2 = sub b t1
- 48. 48 %opencl.image2d_ro_t = type opaque define void @foo(i32 addrspace(1)* %i, %opencl.image2d_ro_t addrspace(1)* %img) !kernel_arg_addr_space !1 !kernel_arg_access_qual !2 !kernel_arg_type !3 !kernel_arg_base_type !3 !kernel_arg_type_qual !4 { … %2 = addrspacecast i32 addrspace(1)* %1 to i32 addrspace(4)* … %0 = call i32 @llvm.gpu.read.image(%img)} !1 = !{i32 1, i32 1} !2 = !{!"none", !"read_only"} !3 = !{!"int*", !"image2d_t"} IR for SPMD (LLVM example) LLVM IR - linear format three address code define i32 @foo(i32 %i) { entry: %i.addr = alloca i32 store i32 %i, i32* %i.addr %0 = load i32, i32* %i.addr %add = add nsw i32 %0, 1 ret i32 %add } OpenCL types are all unknown to IR Kernel is marked by metadataIR has an address space attribute for the type Special IR node to cast between objects in different ASes can be eliminated for flattenAS arch or mapped to address calculation sequence Additional information about kernel is kept in metadata Intrinsic represent special operations unavailable in IR lowered to instructions by backend
- 49. 49 Adhoc - a combination of historically grown tricks Do we need other formats that has explicit kernel nodes and known special types as well as functions (i.e.barrier) ? Some alternatives could be SPIRV, PENSIL… IR for SPMD (LLVM example)
- 50. 50 Multiple threads execute single PC in lock step What if threads have to go through different PC i.e.diverge Now all threads in subgroup will be able to execute in a lock step Inefficient because more time is spent to execute the whole program (each thread will compute both cos and sin but only those with valid pred will make result effective) Do all GPUs execute instructions in lock step? MaliT6xx has separate PC for each thread Divergent execution support r0 = … if (r0) r2 = cos(r1); else r2 = sin(r1); r0 = … pred0 = r0!=0 pred1 = r0==0 if (pred0) r2 = cos(r1) // result in r2 is written conditionally if (pred1) r2 = sin(r1) // result in r2 is written conditionally What compiler might do in order to support lock step execution
- 51. 51 lowering i.e.mapping into instructions that make use of registers can perform last optimisations too (peephole optimisations) Backend What does it do? ADD r1 r2 r3 * a b
- 52. 52 Non technical aspects - closed source can be good because it allows better synergy with other SW components but can be bad because it prevents the knowledge sharing. Resource occupancy… Backend general challenges (2/2)
- 53. 53 Closed source facilitates better interplay between SW components but a lot of experimentally grown features that need re-evaluation Close integration with runtime environment Compilation time in an issue: Online compilation requires compilation speed to be minimised GPU code is normally inlined and unrolled and therefore very large basic blocks are produced => increased compilation time because compiler needs to traverse more nodes Many possibilities of instructions => increased number of choices Need to fit needs of both Graphics and Compute… Overall
- 54. 54 DifferentWorkloads: Compute has more complex algorithms and uses more features (branching,loops,function calls, pointers) Graphics workloads are harder to predict (each vertex can be computed in slightly different way while all compute threads truly go through the same exactly program flow) Conflicting accuracy/performance tradeoff: Example:DIV is expensive => many techniques (using subtract,multiply, reciprocal,etc, in HW or SW or hybrid)… rounding issues CL: exact number matters GL:as soon as visualisation correct we don’t care about exact number => different optimisations possible with different implementation of DIV with respect to accuracy and speed Graphics vs Compute