Cluster based storage - Nasd and Google file system - advanced operating systems unisa 2014
Download as PPTX, PDF2 likes798 views

The document discusses cluster-based storage and specifically the design, implementation, and evaluation of Network-Attached Secure Disks (NASD) and Google File System (GFS). It addresses the architecture, goals, scalability, performance metrics, and fault tolerance of these systems, highlighting GFS's suitability for large-scale data processing and its influence on computer science. Key conclusions emphasize the effective management of large files and high availability, despite cost considerations and the challenges faced in traditional storage solutions.


![Agenda
The File System
Motivations
Architecture
Benchmarks
Comparisons and conclusions
[Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung,
2003]](https://image.slidesharecdn.com/clusterbasedstorage-nasdandgooglefilesystem-advancedoperatingsystemsunisa2014-151112130629-lva1-app6892/85/Cluster-based-storage-Nasd-and-Google-file-system-advanced-operating-systems-unisa-2014-3-320.jpg)


































Cluster based storage - Nasd and Google file system - advanced operating systems unisa 2014
- 1. Cluster-based Storage Antonio Cesarano Bonaventura Del Monte Università degli studi di Salerno 16th May 2014 Advanced Operating Systems Prof. Giuseppe Cattaneo
- 2. Agenda Context Goals of design NASD NASD prototype Distrubuted file systems on NASD NASD parallel file system Conclusions A Cost-Effective, High-Bandwidth Storage Architecture Garth A. Gibson, David F. Nagle, Khalil Amiri, Jeff Butler, Fay W. Chang, Howard Gobioff, Charles Hardin, Erik Riedel, David Rochberg, Jim Zelenka, 1997-2001
- 3. Agenda The File System Motivations Architecture Benchmarks Comparisons and conclusions [Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, 2003]
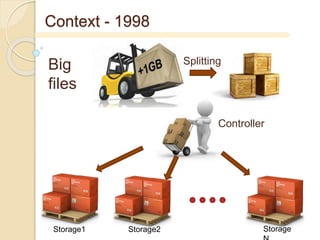
- 4. Context - 1998 New drive attachment technology I/O bounded applications Streaming audio-video Data mining Fibre channel And new network standards
- 5. Context - 1998 Cost-ineffective storage servers Excess of on-drive transistors
- 6. Controller Context - 1998 Big files Splitting Storage1 Storage2 Storage
- 7. Goal No traditional storage file server Cost-effective bandwidth scaling
- 8. What is NASD? Network-Attached Secure Disk direct transfer to clients secure interfaces via cryptographic support asynchronous oversight variable-size data objects map to blocks
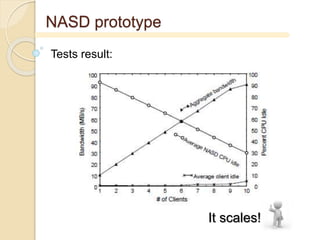
- 10. NASD prototype Based on Unix inode interface Network with 13 NASD Each NASD runs on •DEC Alpha 3000, 133MHz, 64MB RAM •2 x Seagate Medallist on 5MB/s SCSI bus •Connected to 10 clients by ATM (155MB/s) Ad Hoc handling modules (16K loc)
- 11. NASD prototype Tests result: It scales!
- 12. DFS on NASD Porting NFS and AFS on NASD architecture o Ok, no performance loss o But there are concurrency limitations Solution: A new higher-level parallel file system must be used…
- 13. NASD parallel file system Scalable I/O low-level interface Cheops as storage management layer Exports the same object interfaces of NASD devices Maps them to object on devices Maps striped objects Supports concurrency control for multi-disk accesses (10K loc)
- 14. NASD parallel file system Test Clustering data mining application + = *Each NASD drive provides 6.2MB/s
- 15. Conclusions High Scalability Direct transfer to clients Working prototype Usabe with existing file systems But...very high costs: •Network adapters • ASIC microcontroller, •Workstation increasing the total cost by over 80%
- 17. The Google File System • Started with their Search Engine • They provided new services like: Google Video Gmail Google Maps, Earth Google App Engine … and many more
- 18. Design overview Observing common operations in Google applications leads developers to make several assumptions: Multiple clusters distribuited worldwide Fault-tolerance and auto-recovery need to be built into the systems because problems are very often A modest number of large files (100+ MB or Multi-GB) Workloads consist of either large streaming or small random reads, meanwhile write operations are sequential and append large quantity of data to files Google applications and GFS should be co-designed Producer – consumer pattern
- 19. GFS Architecture MASTER CLIENT CHUNK SERVER CHUNKS UNIX FS Request for Metadata Metadata Response METADATA CHUNK SERVER CHUNKS UNIX FS R A M R-W REQUEST R-W RESPONSE
- 20. GFS Architecture: Chunks Similar to standard File System blocks but much larger Size: at least 64 MB (configurable) Advantages: • Reduced clients’ need to contact w/ the master • Client may perform many operations on a single block • Less chunks less metadata in the master • No internal fragmentation due to lazy space
- 21. GFS Architecture: Chunks Disadvantages: • Some small files, made of a small number of chunks may be accessed many times • Not a major issue since Google Apps mostly read large multi-chunk files sequentially • Moreover this can be fixed using an high replication factor
- 22. GFS Architecture: Master A single process running on a separate machine Stores all metadata in its RAM: • File and chunk namespace • Mapping from files to chunks • Chunks location • Access control information and file locking • Chunk versioning (snapshots handling) • And so on…
- 23. GFS Architecture: Master Master has the following responsabilities: Chunk creation, re-replication, rebalancing and deletion for: Balancing space utilization and access speed Spreading replicas across racks to reduce correlated failures, usually 3 copies for each chunk Rebalancing data to smooth out storage and request load Persistent and replicated logging of crititical metadata updates
- 24. GFS Architecture: M - CS Communication Master and chunkservers communicate regularly in order to retrieve their states: o Is chunkserver down? o Are there disk failure on any chunkserver ? o Are any replicas corrupted ? o Which chunk-replicas does a given chunkserver store? Moreover master handles garbage collection and deletes «stale» replicas o Master logs the deletion, then renames the target file to an hidden name o A lazy GC removes the hidden files after a given amount of time
- 25. GFS Architecture: M - CS Communication Server Requests Client retrieves metadata from master for the requested Read / Write dataflows between client and chunkserver decoupled from master control flow Single master is no longer a bottleneck: its involvement with R&W is minimized: Clients communicate directly with chunkservers Master has to log operations as soon as they are completed Less than 64 BYTES of metadata for each
- 26. GFS Architecture: Reading CHUNKSERVER MASTER APPLICATION GFS CLIENT METADATA R A M CHUNKSERVER CHUNKSERVER
- 27. GFS Architecture: Reading CHUNKSERVER MASTER APPLICATION GFS CLIENT METADATA R A M CHUNKSERVER CHUNKSERVER NAME - RANGE NAME CHUNK INDEX CHUNK HANDLE REPLICA LOCATIONS
- 28. GFS Architecture: Reading CHUNKSERVER MASTER APPLICATION GFS CLIENT METADATA R A M CHUNKSERVER CHUNKSERVER CHUNK HANDLE RANGEDATA FROM FILE DATA
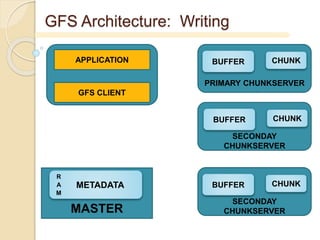
- 29. GFS Architecture: Writing MASTER APPLICATION GFS CLIENT METADATA R A M PRIMARY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK
- 30. GFS Architecture: Writing MASTER APPLICATION GFS CLIENT METADATA R A M NAME - DATA NAME CHUNK INDEX CHUNK HANDLE PRIMARY AND SECONDAY REPLICA LOCATIONS PRIMARY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK
- 31. GFS Architecture: Writing MASTER APPLICATION GFS CLIENT METADATA R A M PRIMARY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK DATA DATA DATA
- 32. GFS Architecture: Writing MASTER APPLICATION GFS CLIENT METADATA R A M PRIMARY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK WRITE CMD
- 33. GFS Architecture: Writing MASTER APPLICATION GFS CLIENT METADATA R A M PRIMARY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK SECONDAY CHUNKSERVER BUFFER CHUNK ACKs ACK
- 34. Fault Tolerance GFS has its own relaxed consistency model Consistent: all replicas have the same value Defined: each replica reflects the performed mutations GFS is high available Faster recovery (machine quickly rebootable) Chunks replicated at least 3 times (take this RAID-6)
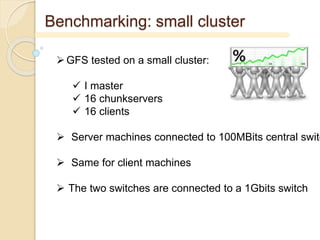
- 35. Benchmarking: small cluster GFS tested on a small cluster: I master 16 chunkservers 16 clients Server machines connected to 100MBits central switc Same for client machines The two switches are connected to a 1Gbits switch
- 36. Benchmarking: small cluster Read Rate Write Rate 1 client 10 MB/s 6.3 MB/s 16 clients 6 MB/s 2.2 MB/s Network limit 12.5 MB/s
- 37. Benchmarking: real-world cluster Cluster A: 342 PCs Used for research and development Tasks last few hours reading TBs of data, processing and writing results back Cluster B: 227 PCs Continuously generates and processes multi-TB data s Typical tasks last more hours than cluster A tasks
- 38. Benchmarking: real-world cluster Cluster A B Chunkservers # 342 227 Available disk space 72 TB 180 TB Used disk space 55 TB 155 TB # of files 735000 737000 # of chunks 992000 1550000 Metadata at CSs 13 GB 21 GB Metadata at Master 48 MB 60 MB Read rate 580 MB/s (750 MB/s) 380 MB/s (1300 MB/s) Write rate 30 MB/s 100 MB/s * 3 Master Ops 202~380 Ops/s 347~533 Ops/s
- 39. Benchmarking: recovery time One chunkserver killed in cluster B: o This chunkserver had 15000 chunks containing 600GB of data o All chunks were restored in 23.2 mins with a replication rate of 440 MB/s Two chunkserver killed in cluster B: o Each with 16000 chunks and 660 GB of data, 266 of them became uniques o These 266 chunks were replicated at an higher priority within 2 mins
- 40. Comparisons to others models GFS RAIDxFS GPFS AFS NASD spreads file data across storage servers simpler, uses only replication for redundancy location independent namespace centralized approach rather than distribuited managementcommodity machines instead of network attached disks lazy allocated fixed-size blocks rather than variable-lengh objects
- 41. Conclusion GFS demonstrates how to support large-scale processing workloads on commodity hardware: designed to tollerate frequent component failures optimised for huge files that are mostly appended and read It has met Google’s storage needs, therefore good enough for them GFS has influenced massively the computer science in the last few years