





















Clustering for Stream and Parallelism (DATA ANALYTICS)
- 1. MEMBERS: Dheeraj Pachauri(1809113042) Himanshu Bharti(1809113052) Shahnawaz Khan(1900910139007) Abhay Kumar Mishra(1900910139001)
- 2. Clustering Data Stream Stream Clustering Requirements for clustering algorithms Stream clustering steps & algorithms Prototype array Window models Outliers & its detection Applications of clustering
- 3. Method of identifying similar groups of data in a data set. Entities in each group are comparatively more similar to entities of that group than those of other group. Some methods include K-means, K-mediods, DB- SCAN etc.
- 4. STREAM: Data that arrives continuously such as Google queries, telephone records, multimedia data, financial transactions etc. Not feasible to store in a database & data can be lost if not processed immediately DATA STREAM: Continuous, massive, unbounded sequences of data objects that are continuously generated at a rapid rate. The problem of data stream clustering is defined as: Input: a sequence of n points in metric space & an integer k. Output: k centers in the set of the n points so as to minimize the sum of distances from data points to their closest cluster centers.
- 5. ONLINE PHASE Summarize the data into memory-efficient data structures OFFLINE PHASE Use a clustering algorithm to find the data partition
- 6. Provide timely results by performing fast & incremental processing of data objects Rapidly adapt to changing dynamics of the data, which means algorithm should detect when new clusters may appear, or others disappear Scale to the number of objects that are continuously arriving Provide a compact model representation Rapidly detect the presence of outliers & act accordingly High dimensionality, interpretability & usability Deals with different data types. Ex- XML trees, DNA sequences, GPS information etc.
- 7. ALGORITHM STEPS: Data Abstraction: Summarize the data into memory-efficient data structures Clustering phase: Use a clustering algorithm to find the data partition
- 8. There are five main classes: HIERARCHICAL BASED ALGORITHMS: It uses the dendrogram data structure which is binary tree based. Useful to summarize & visualize the data. Examples are BIRCH, CHAMELEON, ODAC, E-Stream & HUE-Stream.
- 9. It splits the data instances into a predefined number of clusters based on similarity to the cluster centroids. Examples are Clustream, HPStream, SWClustering, StreamKM++ & CLARA.
- 10. It uses multi-resolution grid data structure. The workspace is divided into a number of cells, in a grid structure, and each instance is assigned to a cell Grid cells are then clustered. Examples include GCHDS, GSCDS, DGClust, CLIQUE, WaveCluster & STING.
- 11. It keeps summary of input data in large number of micro clusters. Micro cluster is a set of data instances that are very close to each other. Synopsis is kept with a feature vector. Then, these micro clusters are merged & formed final clusters. Examples are DBSCAN, LDBSCAN, DSCLU, SOStream & MR-Stream
- 12. It finds the data distribution model that fit best to the input data. Attempt to optimize the fit between the data & some mathematical model. Adopts statistical & AI approach Examples are COBWEB, CluDistream & SWEM
- 13. Some data stream clustering algorithms usea simplified summarization structure called prototype array. Array of protoypes that summarizes the data partition. It’s used to summarize the stream to divide the data stream into chunks of size m.
- 14. In most data stream scenarios, more recent information from the stream can reflect the emerging of new trends or changes on the data distribution. This information can be used to explain the evolution of the process under observation. Moving window techniques have been proposed to partially address this problem.
- 15. Only the most recent information from the data stream are stored in a data structure whose size can be variable or fixed. This is usually a first in, first out(FIFO) structure which considers the objects from the current period of time upto a certain period in the past. The organization & manipulation of objects are based on the principle of queue processing.
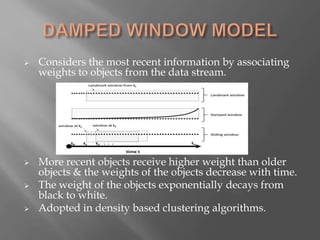
- 16. Considers the most recent information by associating weights to objects from the data stream. More recent objects receive higher weight than older objects & the weights of the objects decrease with time. The weight of the objects exponentially decays from black to white. Adopted in density based clustering algorithms.
- 17. Last in the row It considers the data in the data stream from the beginning until now.
- 18. The coreset tree structure is responsible for reducing 2m objects to m objects. The construction of this structure is defined as follows: First, the tree has only the root node v, which contains all the 2m objects in Ev. The prototype of the root node Xpv is chosen randomly from Ev & Nv=|Ev|=2m. Afterwards, two child nodes for v are created as v1 & v2. To create these nodes, the object that is farthest away from the prototype object is selected.
- 19. OUTLIERS: The set of objects are considerably dissimilar from the remainder of the data. PROBLEM: Find top n outlier points APPLICATIONS: Credit card fraud detection Telecom fraud detection Customer segmentation Medical analysis
- 20. Besides the requirements of being incremental & fast, data stream clustering algorithms should also be able to properly handle outliers through the stream. These are objects that deviate from the general behaviour of a data model & occur due to different causes, such as problems in data collection, storage & transmission errors, fraudulent activities or changes in the behaviour of the system.
- 21. Pattern recognition Spatial data analysis Image processing Economic Science(especially market research) WWW
- 22. Internet Data Mining & Analysis by MJ Zaki Websites(dimacs.rutgers.edu & dsc.soic.indiana.edu) Class notes