Common Cluster Configuration Pitfalls
Download as PPTX, PDF0 likes876 views

The document presents an overview of common pitfalls in cluster configuration, including replication and sharding issues. It emphasizes the importance of proper write concerns, effective use of arbiters, and careful shard key selection in ensuring high availability and scalability. Key takeaways suggest prioritizing high availability in replica set designs and the consequences of poor configurations on data integrity and performance.
























































Common Cluster Configuration Pitfalls
- 1. #MDBW17 Andrew Young, Technical Services Engineer COMMON CLUSTER CONFIGURATION PITFALLS
- 2. #MDBW17 OVERVIEW • Replication Review • Replication Pitfalls • Sharding Review • Sharding Pitfalls • Takeaways • Questions
- 4. #MDBW17 REPLICATION IMPROVES AVAILABILITY BY DUPLICATING DATA BETWEEN NODES Primary Secondary Secondary {x:1,y:2} {x:1,y:2} {x:1,y:2}
- 5. #MDBW17 NODES VOTE TO SELECT A PRIMARY VOTING REQUIRES A STRICT MAJORITY Server 1 Vote: Server 1 Server 2 Vote: Server 1 Server 3 Vote: Server 3 Winner: Server 1
- 6. #MDBW17 ARBITERS VOTE BUT DON’T STORE DATA Primary Secondary Arbiter {x:1,y:2} {x:1,y:2}
- 7. #MDBW17 WRITE CONCERN Primary Secondary Secondary {x:1,y:2} {x:1,y:2} {x:1,y:2} w: 1 w: 2 w: 3 w: majority
- 9. #MDBW17 BUY N LARGE • Online retailer, USA only • Requires high availability • Report generation should not impact production performance
- 12. #MDBW17 BUY N LARGE’S EXPECTED BEHAVIOR DC1 Primary Arbiter DC2 Primary I’m the only one left, so I should be primary!
- 13. #MDBW17 ACTUAL BEHAVIOR DC1 Primary Arbiter DC2 Secondary I only received one vote out of three, so I should be a secondary!
- 14. #MDBW17 DC2DC1 BUY N LARGE’S APPLICATION ARCHITECTURE Load Balancer App Server 1 Primary Arbiter App Server 2 Secondary
- 15. #MDBW17 DC2DC1 BUY N LARGE’S APPLICATION ARCHITECTURE Load Balancer App Server 1 Primary Arbiter App Server 2 Secondary
- 16. #MDBW17 DC2DC1 NETWORK SPLIT Load Balancer App Server 1 Primary Arbiter App Server 2 Secondary
- 17. #MDBW17 DC2DC1 NETWORK SPLIT Load Balancer App Server 1 Primary Arbiter App Server 2 Secondary
- 18. #MDBW17 DC2DC1 EXPECTED BEHAVIOR LEADS TO POSSIBLE DATA CORRUPTION Load Balancer App Server 1 Primary Arbiter App Server 2 Primary X = 1 ✅ X = 2 ✅
- 19. #MDBW17 DC2DC1 ACTUAL BEHAVIOR PREVENTS POSSIBLE DATA CORRUPTION Load Balancer App Server 1 Primary Arbiter App Server 2 Secondary X = 1 ✅ X = 2 ❌
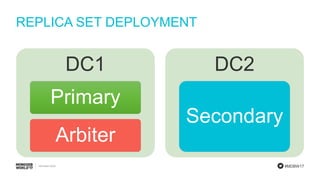
- 20. #MDBW17 REPLICA SET DEPLOYMENT V2 DC1 Primary DC2 Secondary Cloud Arbiter
- 21. #MDBW17 REPLICA SET DEPLOYMENT V2 DC1 Primary DC2 Secondary Cloud Arbiter
- 22. #MDBW17 REPLICA SET DEPLOYMENT V2 DC1 Primary DC2 Primary Cloud Arbiter
- 23. #MDBW17 REPLICA SET DEPLOYMENT V3 DC1 Primary DC2 Secondary DC3 Secondary
- 24. #MDBW17 REPLICA SET DEPLOYMENT V3 DC1 Primary DC2 Secondary • Under Provisioned 1 Hour Lag DC3 Secondary • Under Provisioned 1 Hour Lag
- 25. #MDBW17 REPLICA SET DEPLOYMENT V3 DC1 Primary DC2 Secondary • Under Provisioned 1 Hour Lag DC3 Primary • Under Provisioned 1 Hour Lag
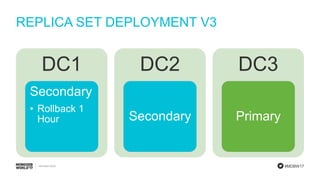
- 26. #MDBW17 REPLICA SET DEPLOYMENT V3 DC1 Secondary • Rollback 1 Hour DC2 Secondary DC3 Primary
- 27. #MDBW17 REPLICA SET DEPLOYMENT V4 DC1 Primary DC2 Secondary DC3 Secondary
- 28. #MDBW17 REPLICA SET DEPLOYMENT V5 DC1 Primary • Operational DC2 Secondary • High Availability DC3 Secondary • HA Hidden • Reporting
- 29. #MDBW17 LESSONS LEARNED - REPLICATION • Be sure that the application’s write concern setting can still be fulfilled if one of the nodes crashes. • Use arbiters very sparingly if at all. • The standard “hot spare” disaster recovery model requires manual intervention. For true HA, a network split or the loss of a data center should not leave the replica set in a read-only mode. • Design replica sets for high availability first and then add specialized nodes as needed.
- 30. SHARDING REVIEW
- 31. #MDBW17 BUY N LARGE V2 • BnL has gone global. • Traffic has increased and the current replica set is starting to experience performance issues from the increased load.
- 33. #MDBW17 SHARDING DIVIDES UP THE DATA S0 A-E N-Q S1 F-J R-T S2 K-M U-Z Collections are sharded, not databases.
- 34. #MDBW17 HIGH AVAILABILITY VS SCALABILITY Primary A-Z Secondary A-Z Secondary A-Z S0 A-E N-Q S1 F-J R-T S2 K-M U-Z
- 35. #MDBW17 BUT WHAT ABOUT SECONDARY READS? • Can improve performance in certain cases. • May return stale or duplicate documents. • Use with caution! https://xkcd.com/386/
- 37. #MDBW17 SHARDED CLUSTER CONFIGURATION V1 • Shard keys: {_id:”hashed”} CFG P S S S0 P S S H S1 P S S H S2 P S S H
- 38. #MDBW17 SHARDED QUERIES mongos A-F G-M N-Z mongos A-F G-M N-Z Range Query (Requires Shard Key) Scatter / Gather Query (No Shard Key)
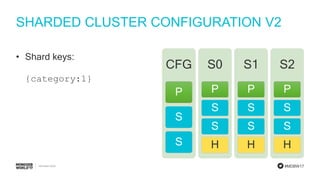
- 39. #MDBW17 SHARDED CLUSTER CONFIGURATION V2 • Shard keys: {category:1} CFG P S S S0 P S S H S1 P S S H S2 P S S H
- 40. #MDBW17 HOW DOES CHUNKING ACTUALLY WORK? • Chunks are metadata. • Chunks represent a key range. S0 A-E N-Q S1 F-J R-T S2 K-M U-Z
- 41. #MDBW17 HOW DOES CHUNKING ACTUALLY WORK? • The mongos instance controls chunk creation and splitting. • After writing 1/5th of the maximum chunk size to a chunk, the mongos requests a chunk split. S0 A-E N-Q S1 F-J R-S T S2 K-M U-Z
- 42. #MDBW17 SHARD KEY SELECTION AND CARDINALITY • If a key range can’t be split, it lacks cardinality. S0 A-E N-Q S1 F-J R-S T S2 K-M U-Z S Can’t Split!
- 43. #MDBW17 SHARDED CLUSTER CONFIGURATION V3 • Shard keys: { category:1, sku: 1, _id: 1 } CFG P S S S0 P S S H S1 P S S H S2 P S S H
- 44. #MDBW17 HOW DOES BALANCING ACTUALLY WORK? • When one shard has too many chunks, the balancer executes a chunk move operation. • Balancing is based on number of chunks, not size of data. S0 A-E N-Q S1 F-J R S T S2 K-M U-Z S
- 45. #MDBW17 CHUNK MOVE PROCESS 1. Documents in the shard key range of the chunk are copied to the destination shard. 2. The chunk metadata is updated. 3. A delete command is queued on the source shard. S0 A-E N-Q S1 F-J R S T S2 K-M U-Z S
- 46. #MDBW17 WHAT ARE ORPHANED DOCUMENTS? • Sometimes the same document exists in two places. • Only primaries and mongos instances know about chunks. • Reading from secondary nodes in a sharded system will return both copies of the document. S0 A-E N-Q S1 F-J R S T S2 K-M U-Z S
- 47. #MDBW17 EMPTY CHUNKS • If documents are deleted from a chunk and not replaced, chunks can become empty. • Empty chunks can cause data size imbalances between shards. S0 2012 2015 S1 2013 2016 S2 2014 2017
- 48. #MDBW17 SHARDED CLUSTER CONFIGURATION V4 • Shard keys: { category:1, sku: 1, _id: 1 } CFG P S S S0 P S S S1 P S S S2 P S S
- 49. TAKEAWAYS
- 50. #MDBW17 LESSONS LEARNED - REPLICATION • Be sure that the application’s write concern setting can still be fulfilled if one of the nodes crashes. • Use arbiters very sparingly if at all. • The standard “hot spare” disaster recovery model requires manual intervention. For true HA, a network split or the loss of a data center should not leave the replica set in a read-only mode. • Design replica sets for high availability first and then add specialized nodes as needed.
- 51. #MDBW17 LESSONS LEARNED - SHARDING • Replication is for HA, sharding is for scaling. • Shard key selection is extremely important. ‒ Affects query performance ‒ Affects chunk balancing ‒ Can not easily be changed later on • Secondary reads on sharded clusters are highly discouraged. ‒ Orphaned documents will cause multiple versions of the same document to be returned. ‒ MongoDB 3.4 greatly improved both replication and sharding.
- 52. #MDBW17 YOUR MILEAGE MAY VARY https://xkcd.com/722/
- 53. QUESTIONS
- 55. SAVE THE DATE STRATA + HADOOP WORLD September 25 – 28, 2017 Javits Center 655 W 34th St New York, NY 10001** ORACLE OPENWORLD September 25 – 28, 2017 Moscone Center 747 Howard Street San Francisco, CA, 94103
- 56. Diamond
- 57. Platinum
- 58. Gold
- 59. Silver
Editor's Notes
- #5: If the primary become unavailable, whether that is due to an outage or just regular maintenance, one of the secondaries can take over as primary.
- #6: Here we see an example election. Since two of the three servers have voted for server 1, server 1 will become primary.
- #8: Default write concern is w:1. The client can override the write concern, either by decreasing it to w:0 or by increasing it to another value.
- #11: Buy N Large is used to standard enterprise software deployment. As such, they are using industry standard disaster recovery methodologies. They have two data centers: their primary data center (DC1) and a “hot spare” disaster recovery data center (DC2). They also set their write concern value to “majority” based on our suggested practices.
- #12: Their primary data center has now failed, leaving only the “hot spare” disaster recovery data center operational.
- #13: Buy N Large expects that because there is only one node left, that one node will constitute a majority and will vote to make itself primary.
- #14: However, the actual behavior is that the secondary remains a secondary, because it knows that there should be three nodes and thus one vote is not enough to become primary.
- #15: To better understand why this is, let’s look at Buy N Large’s complete architecture.
- #16: In this case, both application servers talk to the primary in DC1.
- #17: Now let’s imagine that a network error prevents DC1 from seeing DC2. Each data center thinks the other is down, but in reality all of the servers are still operating normally.
- #18: The application server in each data center can only see the MongoDB instance in its own data center. However, the load balancer still sees both data centers and still sends traffic to both application servers.
- #19: If the secondary in DC2 is allowed to become primary because it can only see one itself, then there would be an opportunity for the same data to be changed differently in each data center. When the network issue was resolved, the system would need to determine how to reconcile the updates that were made.
- #20: Because the voting algorithm that MongoDB uses does not allow the secondary in DC2 to become primary in this situation, this possible data corruption is prevented.
- #21: To alleviate this problem, Buy N Large moved the arbiter to a small cloud instance where it could see both data centers.
- #22: Later on, Buy N Large decided to perform routine maintenance on the primary node and shut it down.
- #23: This time, the node in the second data center was successfully elected as primary thanks to the arbiter in the cloud. However, because write concern is set to “majority”, writes still fail to complete when one of the data bearing nodes is down.
- #24: To prevent this from happening again in the future, Buy N Large switched out the arbiter for a data bearing node.
- #25: However, after the system ran for a while under regular load, the secondaries – which were under provisioned as they were not considered to be as important as the primary – began to lag behind the primary.
- #26: The next time the primary was rotated out for maintenance the secondary in DC3 became primary. Because it is an hour behind, that hour of data is no longer available to the application.
- #27: When the node in DC1 comes back online as a secondary, it sees that it is an hour ahead of the primary and initiates a rollback. That hour of data is written out to disk so that it is not lost, but the documents in the database are replaced with those that are on the primary. Recovering the data requires a manual process.
- #28: Buy N Large has re-provisioned their hardware to be the same in all data centers, but because any secondary might become primary, they don’t want to use one of the secondary nodes for reporting.
- #29: The final replica set deployment includes a hidden secondary node for reporting purposes.
- #36: Secondary reads also affect the ability for a replica set to continue to function properly when the primary becomes unavailable. If each of the secondaries is already handling some percentage of the reads for the replica set, then the loss of the primary means that the reads from the primary will now be spread across the remaining secondaries.
- #38: Then they noticed that queries were taking a long time.
- #40: Then they started seeing jumbo chunks that couldn't be migrated.
- #43: Because the mongos only knows about the data it is writing, the 1/5th number is used as a heuristic to make an educated guess about when the chunk should be split. The heuristic assumes five mongos instances that are receiving equal traffic. If your system has a significantly larger number of mongos instances and they are all being used equally often, it is possible for this heuristic to break down and cause problems.
- #44: BI reporting tools begin to see duplicate documents.
- #46: The chunk move process has been improved in 3.4 with the addition of parallel chunk migrations. In 3.4 it is more efficient to add more than one shard at a time when increasing capacity due to parallel chunk migrations. 3.4 also adds support for inter-cluster compression, although it is turned off my default.
- #47: There is currently a plan to make secondaries aware of chunk metadata. The difficulty with this is that the view that secondaries have of the chunk metadata must be accurate as of their most recent oplog entry. If a secondary is lagging behind a primary, it is important that the secondary’s chunk metadata matches this lag.
- #48: In a system where documents are deleted in such a way that chunks become empty, a cluster may become unbalanced from a data size perspective even though it appears balanced from a chunk count perspective. This can happen, for instance, when the shard key contains a timestamp element and old documents are deleted after a certain number of days. If a shard contains empty chunks, the mergeChunks command can be used to merge those empty chunks with chunks that contain data.
- #49: Here is the final configuration for Buy N Large’s sharded cluster. In this configuration, their BI tools must be taken into account when sizing the cluster because they use the same servers as their production systems. Another option might be to create a second BI cluster and copy data from production to that cluster.