

























































Comprehensive Guide to Neural Networks in Machine Learning and Deep Learning Applications"
- 1. By B RAJESWARI TGTWRDC(GIRLS) KHAMMAM NEURAL NETWORKS
- 2. Bio-inspired Multi-Layer Networks 1.What is a Multi-Layer Neural Network? A Multi-Layer Perceptron (MLP) is an artificial neural network composed of multiple layers of neurons. •It is inspired by how biological neurons process information. Structure of a Multi-Layer Network •A typical two-layer neural network consists of: Input Layer – Receives input features (e.g., image pixels). Hidden Layer – Applies weighted transformations and activation functions. Output Layer – Produces the final prediction.
- 3. Diagram of a Simple Two-Layer Network Here: •Each hidden neuron receives inputs and applies a non-linear function (activation function). •The output neuron combines hidden activations to make a final decision.
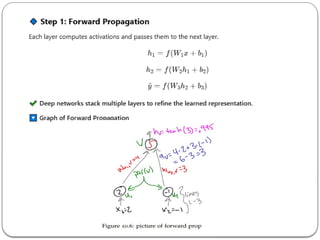
- 4. 2. How Does a Multi-Layer Network Work? •The network performs forward propagation (to make predictions) and back propagation (to update weights). Step 1: Compute Hidden Layer Activations Each hidden neuron receives inputs and computes an activation:
- 5. Graph of Activation Functions •tanh function (smooth, non-linear, differentiable) •ReLU function (better for deep networks)
- 6. •The image compares the sign function (sign(x))and the hyperbolic tangent function (tanh (x)). Explanation: Sign Function (sign(x): Defined as •It is not differentiable at x=0 due to the discontinuity. •It produces discrete output values: -1 for negative numbers, 0 at zero, 1 for positive numbers.
- 7. x sign(x) tanh (x) -2 -1 -0.964 -1 -1 -0.761 0 0 0 1 1 0.761 2 1 0.964 Example: Let’s compare outputs for a few values of x:
- 8. 3. Training a Multi-Layer Network (Back propagation) • To train the network, we minimize the error between predicted and actual outputs. • Loss Function (Error) • A common choice is Mean Squared Error (MSE):
- 10. Meaning of Activation in Neural Networks •Activation in a neural network refers to the value computed by a neuron after applying a mathematical function to its inputs. •It determines whether the neuron should be "active" (contribute to the next layer) or not. •Each neuron in a layer computes its activation using the formula: a=f(z) where: z=∑vihi+b is the weighted sum of inputs plus bias. •f(z) is an activation function that introduces non-linearity.
- 11. Step 2: Apply Activation Function If we use a ReLU activation function f(z)=max (0,z), then: a=max (0,2.0)=2.0 So, the final activation output is 2.0. Example Let’s consider a simple neural network with one hidden neuron and one output neuron. Step 1: Compute Weighted Sum Suppose: Hidden neuron activation h1=2.0 Weight v1=0.5 Bias bo=1.0 Using the formula: z=(v1 h1)+bo=(0.5 2.0)+1.0=2.0 ⋅ ⋅
- 12. How to Solve XOR? Single-layer perceptron fails because XOR is not linearly separable. Multi-layer network solves it using a hidden layer. 🔽 Diagram: Two-Layer Network for XOR
- 13. Explanation of the Small XOR Data Set The table shown in the image represents a small XOR dataset, which is commonly used in machine learning to illustrate the need for a non-linear model. Understanding the Columns y: The target output (label). x0 : Bias term (always +1). x1,x2 : Input features. Each row represents a training example. XOR Logic The dataset seems to be an extension of the XOR (Exclusive OR) function, where the output y depends on the inputs x1and x2 : y=x1 x2 ⊕ where denotes the XOR operation. ⊕ However, this dataset uses ±1 notation instead of 0 and 1, which is common in some neural network training approaches.
- 15. x1x_1x1 x2x_2x2 h1=OR(x1,x2) h2=AND(x1,x2) y^=−2h2+h1 0 0 0 0 0 0 1 1 0 1 1 0 1 0 1 1 1 1 1 -2(1) + 1 = -1 Step 3: Understanding the Computation Let’s verify this using truth table values: This matches the expected XOR function: •(0,0)→0 •(0,1)→1 •(1,0)→1 •(1,1)→0
- 16. X-----------------X (Linear Model ❌) | | | O O | | | X-----------------X X-----O-----X (Multi-Layer Model ✅) | | | | O | O | | | | X-----O-----X 5. Why Are Multi-Layer Networks Powerful? •The Universal Approximation Theorem •A single-layer network can only represent linear functions. •A two-layer network can approximate any function given enough neurons. •Deeper networks can learn complex patterns more efficiently.
- 17. Back propagation Algorithm •The Back propagation Algorithm is a key method for training multi-layer neural networks. • It adjusts the weights of a neural network using gradient descent and the chain rule of calculus. 1. What is Back propagation? Back propagation allows a neural network to learn by: 1.Computing the error between predicted and actual values. 2.Propagating the error backward through the network. 3.Adjusting the weights to minimize the error.
- 18. 2. Steps of Back propagation
- 19. Step 2: Compute Error The error at the output layer is calculated as: e=y−y^ where: y is the actual target output. Y^is the predicted output from the model. Step 3: Compute Gradients (Backward Pass) This step involves computing how much we need to adjust the weights to reduce the error.
- 24. Next Steps Repeat the Forward Pass: Use the updated weights (w=0.4005, v=0.6014) to compute the new hidden layer activation and output prediction. Compute New Error: Compare the new prediction with the actual target y. Compute the new error e=y−y^ . Perform Another Back propagation Step: Compute new gradients for w and v. Update weights again using gradient descent. Continue Training for Multiple Epochs: Iterate this process for many epochs until the error is minimized, meaning the model has learned to approximate the target output well. Evaluate Performance: Once training is done, test the model on new data to check its accuracy and generalization.
- 26. 5. Key Takeaways ✔ Back propagation uses gradient descent to adjust weights. It propagates errors from output to hidden layers. ✔ Allows deep networks to learn complex patterns. ✔ Used in almost all modern deep learning models. ✔
- 27. Initialization and Convergence of Neural Networks This section cusses: • Why Initialization Matters • Problems with Poor Initialization • Good Initialization Techniques • Challenges in Convergence • Strategies for Faster CONVERGENCE
- 28. 1. Why Does Initialization Matter? 🔹 What Happens with Poor Initialization? • Weight initialization is a critical step in training neural networks. Poor initialization can lead to issues such as slow convergence, unstable training, or the complete failure of the network to learn. Below is a detailed breakdown of why proper initialization is important and what happens if it is not done correctly. 1. All Weights = 0 → The Network Never Learns ❌ If all weights are initialized to zero, the network fails to learn anything. This is because all neurons will have the same gradients and will update identically. This leads to symmetry in the network, meaning all neurons in the same layer behave the same way, making the network incapable of learning diverse features. ✅ Solution: Randomly initialize weights with small values to break symmetry.
- 29. 2. Too Large Weights → Exploding Gradients ❌ When weights are initialized with very large values, the gradients during back propagation can also become excessively large. This leads to unstable training because the weight updates are too drastic, causing the network to diverge rather than converge. The problem is especially severe in deep networks, where multiple layers amplify these large gradients, making optimization difficult. ✅ Solution: Use Xavier Initialization or He Initialization, which scales weights appropriately to prevent large gradient values.
- 30. 3. Too Small Weights → Vanishing Gradients ❌ If the weights are initialized with very small values, the gradients in the deeper layers become extremely small during back propagation. This slows down learning since the weight updates are negligible. The problem is particularly common when using activation functions like sigmoid or tanh, where gradients shrink as they propagate backward. As a result, earlier layers learn very slowly, while later layers receive better updates, leading to inefficient training. ✅ Solution: Use ReLU activation functions instead of sigmoid/tanh. Use He Initialization, which is designed for ReLU-based networks to maintain proper gradient flow
- 31. 2.Common Weight Initialization Methods •To prevent these issues, we use smart initialization techniques. (1) Random Initialization (Old Approach ❌) • Assign random values (e.g., small Gaussian noise). Problem: It can still cause vanishing/exploding gradients.
- 33. 3. Challenges in Convergence 🔹 (1) Vanishing Gradients 😓 In deep networks, gradients shrink → slow learning. Solution: Use ReLU + He initialization. ✔ 🔹 (2) Exploding Gradients 💥 In deep networks, gradients become too large. Solution: Use gradient clipping or He initialization. ✔ 🔹 (3) Poor Local Minima 😩 The network gets stuck in bad solutions. Solution: Use batch normalization and adaptive optimizers (Adam, ✔ RMSprop).
- 34. Convergence of Randomly Initialized Networks •The graph illustrates how different weight initialization methods affect the convergence of a neural network during training. •The x-axis represents the number of iterations (training progress), while the y-axis represents the test error (lower is better). Key Observations: Zero Initialization Fails to Converge Efficiently The curve labeled "zero-init" remains significantly higher than the others, meaning the network struggles to reduce test error effectively. This happens because initializing all weights to zero leads to symmetry in the network, causing neurons to learn the same features, making training ineffective.
- 35. 2.Random Initialization Leads to Faster Convergence • The multiple colored lines represent different runs of the network with random weight initialization. • These networks show better and faster reduction in test error compared to zero initialization. • However, the convergence rate varies among different runs, suggesting that the choice of initialization distribution can still impact training efficiency. 3.Final Performance Variation • Some curves (e.g., green and blue) achieve lower test errors faster, while others (e.g., purple) take longer or oscillate more. • This highlights the importance of using optimized initialization techniques (e.g., Xavier or He initialization) instead of purely random initialization.
- 36. Problem Solution Slow learning Use adaptive learning rates (Adam, RMSprop) Vanishing gradients Use ReLU + He initialization Exploding gradients Apply gradient clipping Poor local minima Use batch normalization 4. Strategies to Improve Convergence
- 37. 6. Key Takeaways ✔ Good initialization speeds up training and prevents bad convergence. ✔ Xavier (Glorot) → Best for sigmoid/tanh networks. ✔ He Initialization → Best for ReLU-based deep networks. ✔ LeCun Initialization → Works well for small networks with sigmoid.
- 38. Beyond Two Layers in Neural Networks (Deep Learning) • Neural networks can go beyond two layers to create deep neural networks (DNNs), which allow them to learn more complex patterns. • This section will explain: • Why go beyond two layers? • Deep Networks Structure (Diagrams) • Forward and Back propagation in Deep Networks • Advantages & Challenges of Deep Networks • Graphs showing Training Convergence
- 39. Feature Two-Layer Network Multi-Layer Network Function Approximation Can approximate any function More efficient & expressive Training Complexity Fewer parameters, easier to train More parameters, harder to optimize Performance on Complex Tasks Limited to simple problems Handles deep features (vision, NLP) Why Go Beyond Two Layers? • Two-layer network can approximate any function, but deeper networks offer: Fewer neurons for the same task (efficient representation) ✔ Better generalization (learns hierarchical patterns) ✔ Solves complex tasks (e.g., image recognition, NLP) ✔ 🔽 Comparison: Two-Layer vs. Multi-Layer Networks
- 40. 2. Deep Networks Structure (Diagrams) A two-layer network consists of one hidden layer between input and output: 🔽 Two-Layer Neural Network (Shallow) Multi-Layer Neural Network (Deep)
- 44. Step 2: Back propagation • Compute error at output • Propagate errors backward through layers • Update weights using gradient descent 🔽 Graph of Back propagation
- 48. 4. Advantages & Challenges of Deep Networks 🔹 Advantages ✔ Feature Hierarchies: First layers learn simple patterns (edges), deeper layers learn complex features (objects). Efficient Representation: Fewer parameters required than a wide ✔ network. Better Generalization: Captures higher-level abstract representations. ✔ 🔹 Challenges ❌ Vanishing Gradients: Lower layers get very small updates, slowing learning. ❌ Exploding Gradients: Large updates make training unstable. ❌ More Parameters: Harder to optimize.
- 49. Breadth vs Depth, Basis Functions What is Breadth vs. Depth? • Neural networks can be designed to be wide (more neurons per layer) or deep (more layers with fewer neurons per layer). • Wide Networks: Have more neurons per layer but fewer layers. • Deep Networks: Have fewer neurons per layer but many layers.
- 50. Why Consider Deeper Networks If Two-Layer Networks Are Universal Function Approximators? •The Universal Approximation Theorem states that a two-layer (shallow) neural network with enough hidden units can approximate any function. •However, this does not mean that a shallow network is the most efficient way to represent every function. •Some functions require an exponential number of neurons in a shallow network, whereas a deep network can achieve the same result with far fewer neurons.
- 51. Circuit Complexity and the Parity Function •To understand why deep networks can be more efficient, we look at circuit complexity: Consider the parity function, which determines whether the number of 1s in a binary input is odd or even: 1 if the number of 1s is odd 0 if the number of 1s is even
- 52. If we use XOR gates in a circuit: •A deep network (logarithmic depth) can compute parity with O(D) gates (linear in the number of inputs). •A shallow network (constant depth) would require exponential many gates, making it inefficient.
- 53. Feature Wide Network (Breadth) Deep Network (Depth) Number of Layers Small (1-2) Large (4+) Number of Neurons per Layer Large Small Computational Complexity Low High Expressiveness Limited Can approximate complex functions Training Time Faster Slower Vanishing Gradient Problem Less likely More likely Best For Simple tasks Hierarchical features (e.g., image recognition) Trade-Off Between Breadth and Depth
- 54. Basis Functions in Neural Networks Neural networks can approximate both linear and complex non-linear functions. A natural question arises: 👉 Can a neural network mimic a k-Nearest Neighbors (KNN) classifier efficiently? •The answer lies in using Radial Basis Functions (RBFs), which transform a neural network into a structure that behaves similarly to KNN.
- 55. 1. What is a Basis Function? •A basis function is a mathematical function used to transform input data before passing it to the network. It helps in: •Feature transformation: Mapping input space to a more useful representation. •Better function approximation: Capturing complex relationships in data. 🔹 Example: •Linear functions use a dot product transformation •Here, wiis the center of the radial function. •γicontrols the width of the Gaussian function.
- 56. 2. How Do RBF Networks Mimic KNN? a) KNN Classifier •KNN makes predictions based on distances: It finds the closest K points to a given query point and assigns the most common label. b) RBF Networks •Instead of directly storing all training points, RBF neurons act like prototypes. •Each hidden unit in an RBF network corresponds to a "prototype" data point. •The output is determined by a weighted sum of these RBF neurons, similar to KNN’s distance-weighted voting. Key Idea: •Large γ → Localized activation (behaves like KNN, considering only nearby points) •Small γ → Broad activation (behaves like a generalizing model, considering distant points too)
- 57. X (Input) Y (Class) 1.0 A 1.5 A 2.0 B 2.5 B 3. Example: RBF vs. KNN •Imagine we have a 1D dataset where we classify points based on proximity: •KNN (K=1): Predicts class based on nearest neighbor. RBF Network: Centers an RBF neuron at each data point. •Uses a Gaussian function to determine influence. •The output is a weighted sum of RBF neuron activations.
- 58. If a new point X = 1.8 is given: KNN (K=1) → Predicts Class A (closer to 1.5) RBF with optimized γ behaves similarly! Feature KNN RBF Network Memory Usage Stores entire dataset Stores fewer prototypes Computational Cost Slow for large datasets Fast after training Generalization Sensitive to noise Can learn smoother decision boundaries Training No training needed Requires optimization of centers & γ . Advantages of RBF Networks Over KNN
- 59. Thank you