Continuum Analytics and Python
12 likes4,690 views

Continuum Analytics, co-founded by Travis Oliphant, focuses on utilizing Python for data science and analytics, addressing challenges posed by the exponential growth of data. The Anaconda platform serves as an enterprise solution for data exploration, advanced analytics, and rapid application deployment, gaining massive popularity with over 2 million downloads in two years. The document discusses the importance of powerful, accessible languages for data science and outlines various tools and technologies that facilitate effective data analysis and visualization.




![Science led to Python
5
Raja Muthupillai
Armando Manduca
Richard Ehman
Jim Greenleaf
1997
⇢0 (2⇡f)
2
Ui (a, f) = [Cijkl (a, f) Uk,l (a, f)],j
⌅ = r ⇥ U](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-5-320.jpg)



















































![58
Blaze
+ - / * ^ []
join, groupby, filter
map, sort, take
where, topk
datashape,dtype,
shape,stride
hdf5,json,csv,xls
protobuf,avro,...
NumPy,Pandas,R,
Julia,K,SQL,Spark,
Mongo,Cassandra,...](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-58-320.jpg)



![62
Blaze Server
Provide
RESTful
web
API
over
any
data
supported
by
Blaze.
Server
side:
>>> my_spark_rdd = …
>>> from blaze import Server
>>> Server(my_spark_rdd).run()
Hosting computation on localhost:6363
Client
Side:
$ curl -H "Content-Type: application/json"
-d ’{"expr": {"op": "sum", "args": [ ... ] }’
my.domain.com:6363/compute.json
• Quickly share local data to collaborators
on the web.
• Expose any system (Mongo, SQL, Spark,
in-memory) simply
• Share local computation as well, sending
computations to server to run remotely.
• Conveniently drive remote server with
interactive Blaze client](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-62-320.jpg)






![dask.array: OOC, parallel, ND array
69
Arithmetic: +, *, ...
Reductions: mean, max, ...
Slicing: x[10:, 100:50:-2]
Fancy indexing: x[:, [3, 1, 2]]
Some linear algebra: tensordot, qr, svd
Parallel algorithms (approximate quantiles, topk, ...)
Slightly overlapping arrays
Integration with HDF5](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-69-320.jpg)
![dask.dataframe: OOC, parallel, ND array
70
Elementwise operations: df.x + df.y
Row-wise selections: df[df.x > 0]
Aggregations: df.x.max()
groupby-aggregate: df.groupby(df.x).y.max()
Value counts: df.x.value_counts()
Drop duplicates: df.x.drop_duplicates()
Join on index: dd.merge(df1, df2, left_index=True,
right_index=True)](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-70-320.jpg)


![73
from dask import dataframe as dd
columns = ["name", "amenity", "Longitude", "Latitude"]
data = dd.read_csv('POIWorld.csv', usecols=columns)
with_name = data[data.name.notnull()]
with_amenity = data[data.amenity.notnull()]
is_starbucks = with_name.name.str.contains('[Ss]tarbucks')
is_dunkin = with_name.name.str.contains('[Dd]unkin')
starbucks = with_name[is_starbucks]
dunkin = with_name[is_dunkin]
locs = dd.compute(starbucks.Longitude,
starbucks.Latitude,
dunkin.Longitude,
dunkin.Latitude)
# extract arrays of values fro the series:
lon_s, lat_s, lon_d, lat_d = [loc.values for loc in locs]
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
def draw_USA():
"""initialize a basemap centered on the continental USA"""
plt.figure(figsize=(14, 10))
return Basemap(projection='lcc', resolution='l',
llcrnrlon=-119, urcrnrlon=-64,
llcrnrlat=22, urcrnrlat=49,
lat_1=33, lat_2=45, lon_0=-95,
area_thresh=10000)
m = draw_USA()
# Draw map background
m.fillcontinents(color='white', lake_color='#eeeeee')
m.drawstates(color='lightgray')
m.drawcoastlines(color='lightgray')
m.drawcountries(color='lightgray')
m.drawmapboundary(fill_color='#eeeeee')
# Plot the values in Starbucks Green and Dunkin Donuts Orange
style = dict(s=5, marker='o', alpha=0.5, zorder=2)
m.scatter(lon_s, lat_s, latlon=True,
label="Starbucks", color='#00592D', **style)
m.scatter(lon_d, lat_d, latlon=True,
label="Dunkin' Donuts", color='#FC772A', **style)
plt.legend(loc='lower left', frameon=False);](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-73-320.jpg)



![77
@jit('void(f8[:,:],f8[:,:],f8[:,:])')
def filter(image, filt, output):
M, N = image.shape
m, n = filt.shape
for i in range(m//2, M-m//2):
for j in range(n//2, N-n//2):
result = 0.0
for k in range(m):
for l in range(n):
result += image[i+k-m//2,j+l-n//2]*filt[k, l]
output[i,j] = result
~1500x speed-up](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-77-320.jpg)

















Continuum Analytics and Python
- 1. Continuum Analytics and Python Travis Oliphant CEO, Co-Founder Continuum Analytics
- 3. Travis Oliphant - CEO 3 • PhD 2001 from Mayo Clinic in Biomedical Engineering • MS/BS degrees in Elec. Comp. Engineering • Creator of SciPy (1999-2009) • Professor at BYU (2001-2007) • Author of NumPy (2005-2012) • Started Numba (2012) • Founding Chair of Numfocus / PyData • Previous PSF Director SciPy
- 4. Started as a Scientist / Engineer 4 Images from BYU CERS Lab
- 5. Science led to Python 5 Raja Muthupillai Armando Manduca Richard Ehman Jim Greenleaf 1997 ⇢0 (2⇡f) 2 Ui (a, f) = [Cijkl (a, f) Uk,l (a, f)],j ⌅ = r ⇥ U
- 6. “Distractions” led to my calling 6
- 8. 8 • Data volume is growing exponentially within companies. Most don't know how to harvest its value or how to really compute on it. • Growing mess of tools, databases, and products. New products increase integration headaches, instead of simplifying. • New hardware & architectures are tempting, but are avoided or sit idle because of software challenges. • Promises of the "Big Red Solve" button continue to disappoint. (If someone can give you this button, they are your competitor.) Data Scientist Challenges
- 9. Our Solution 9 • A language-based platform is needed. No simple point-and-click app is enough to solve these business problems, which require advanced modeling and data exploration. • That language must be powerful, yet still be accessible to domain experts and subject matter experts. • That language must leverage the growing capability and rapid innovation in open-source. Anaconda Platform: Enterprise platform for Data Exploration, Advanced Analytics, and Rapid Application Development and Deployment (RADD) Harnesses the exploding popularity of the Python ecosystem that our principals helped create.
- 10. Why Python? 10 Analyst • Uses graphical tools • Can call functions, cut & paste code • Can change some variables Gets paid for: Insight Excel, VB, Tableau, Analyst / Data Developer • Builds simple apps & workflows • Used to be "just an analyst" • Likes coding to solve problems • Doesn't want to be a "full-time programmer" Gets paid (like a rock star) for: Code that produces insight SAS, R, Matlab, Programmer • Creates frameworks & compilers • Uses IDEs • Degree in CompSci • Knows multiple languages Gets paid for: Code C, C++, Java, JS, Python Python Python
- 11. Python Is Sweeping Education 11
- 12. Tools used for Data 12 Source: O’Reilly Strata attendee survey 2012 and 2013
- 13. Python for Data Science 13 http://readwrite.com/2013/11/25/python-displacing-r-as-the-programming-language-for-data-science
- 14. Python is the top language in schools! 14
- 15. OUR CUSTOMERS & OUR MARKET 15
- 16. Some Users 16
- 17. Anaconda: Game-changing Python distribution 17 "Hands down, the best Scientific Python distribution products for analytics and machine learning." "Thanks for such a great product, been dabbling in python for years (2002), always knew it was going to be massive as it hit the sweet spot in so many ways, with llvm-numba its magic!!!" "It was quick and easy and had everything included, even a decent IDE. I'm so grateful it brings tears to my eyes." "I love Anaconda more than the sun, moon, and stars…"
- 18. Anaconda: Game-changing Python distribution 18 • 2 million downloads in last 2 years • 200k / month and growing • conda package manager serves up 5 million packages per month • Recommended installer for IPython/Jupyter, Pandas, SciPy, Scikit-learn, etc.
- 19. Conferences & Community 19 • PyData: London, Berlin, New York, Bay Area, Seattle • Strata: Tutorials, PyData Track • PyCon, Scipy, EuroScipy, EuroPython, PyCon Brasil... • Spark Summit • JSM, SIAM, IEEE Vis, ICML, ODSC, SuperComputing
- 20. Observations & Off-the-record 20 • Hype is out of whack with reality • Dashboards are "old school" BI, but still important for narrative/confirmatory analysis • Agility of data engineering and exploration is critical • Get POCs out faster; iterate faster on existing things • Need cutting-edge tools, but production is hard • Notebooks, reproducibility, provenance - all matter
- 22. Data Science Platforms 22 • All-in-one new "platform" startups are walled gardens • Cloud vendor native capabilities are all about lock-in: "Warehouse all your data here!" • Machine Learning and Advanced Analytics is too early, and disrupting too fast, to place bets on any single walled garden. • Especially since most have no experience with "exotic" regulatory and security requirements
- 23. Good News 23 You can have a modern, advanced analytics system that integrates well with your infrastructure Bad News It's not available as a SKU from any vendor. META-PLATFORM CONSTRUCTION KIT
- 24. Great News 24 • If done well, it adds deep, fundamental business capability • Many wall street banks and firms using this. • All major Silicon Valley companies know this • Facebook, LinkedIn, Uber, Tesla, SpaceX, Netflix, ...
- 26. 26 Bitcoin is a digital currency invented in 2008 and operates on a peer-to-peer system for transaction validation. This decentralized currency is an attempt to mimic physical currencies in that there is limited supply of Bitcoins in the world, each Bitcoin must be “mined”, and each transaction can be verified for authenticity. Bitcoins are used to exchange every day goods and services, but it also has known ties to black markets, illicit drugs, and illegal gambling transactions. The dataset is also very inclined towards anonymization of behavior, though true anonymization is rarely achieved. The Bitcoin Dataset The Bitcoin dataset was obtained from http://compbio.cs.uic.edu/data/bitcoin/ and captures transaction-level information. For each transaction, there can be multiple senders and multiple receivers as detailed here: https://en.bitcoin.it/wiki/Transactions. This dataset provides a challenge in that multiple addresses are usually associated with a single entity or person. However, some initial work has been done to associated keys with a single user by looking at transactions that are associated with each other (for example, if a transaction has multiple public keys as input on a single transaction, then a single user owns both private keys). The dataset provided provides these known associations by grouping these addresses together under a single UserId (which then maps to a set of all associated addresses). Key Challenge Questions # Transactions: 15.8 Million+ # Edges: 37.4 Million + # Senders: 5.4 Million+ # Receivers: 6.3 Million+ # Bitcoins Transacted: 1.4 Million + Bitcoin Data Set Overview (May 15, 2013) Figure 1: Bitcoin Transactions Over Time Bitcoin Blockchain
- 28. Memex Dark/Deep Web Analytics 28
- 29. TECH & DEMOS 29
- 30. Data Science @ NYT 30 @jakevdp eSciences Institute, Univ. Washington
- 31. 31 conda cross-platform, multi-language package & container tool bokeh interactive web plotting for Python, R; no JS/HTML required numba JIT compiler for Python & NumPy, using LLVM, supports GPU blaze deconvolve data, expression, and computation; data-web dask lightweight, fast, Pythonic scheduler for medium data xray easily handle heterogeneously-shaped dense arrays holoviews slice & view dense cubes of data in the browser seaborn easy, beautiful, powerful statistical plotting beaker polyglot alternative Notebook-like project
- 32. 32 • Databricks Canvas • Graphlab Create • Zeppelin • Beaker • Microsoft AzureML • Domino • Rodeo? Sense? • H2O, DataRobot, ... Notebooks Becoming Table Stakes
- 33. 33
- 34. 34 "With more than 200,000 Jupyter notebooks already on GitHub we're excited to level-‐up the GitHub-‐Jupyter experience."
- 35. Anaconda 35 ✦ Centralized analytics environment • browser-based interface • deploys on existing infrastructure ✦ Collaboration • cross-functional teams using same data and software ✦ Publishing • code • data • visualizations
- 36. Bokeh 36 http://bokeh.pydata.org • Interactive visualization • Novel graphics • Streaming, dynamic, large data • For the browser, with or without a server • No need to write Javascript
- 39. Previous: Javascript code generation 39 server.py Browser js_str = """ <d3.js> <highchart.js> <etc.js> """ plot.js.template App Model D3 highcharts flot crossfilter etc. ... One-shot; no MVC interaction; no data streaming HTML
- 40. bokeh.py & bokeh.js 40 server.py BrowserApp Model BokehJS object graph bokeh-server bokeh.py object graph JSON
- 41. 41
- 42. 42 4GB Interactive Web Viz
- 44. 44
- 45. 45
- 46. 46
- 48. Additional Demos & Topics 48 • Airline flights • Pandas table • Streaming / Animation • Large data rendering
- 50. 50 Dark Data: CSV, hdf5, npz, logs, emails, and other files in your company outside a traditional data store
- 51. 51 Dark Data: CSV, hdf5, npz, logs, emails, and other files in your company outside a traditional data store
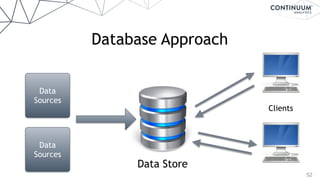
- 53. 53 Bring the Database to the Data Data Sources Data Sources Clients Blaze (datashape,dask) NumPy,Pandas,SciPy, sklearn,etc. (for analytics)
- 54. Anaconda — portable environments 54 PYTHON'&'R'OPEN'SOURCE'ANALYTICS NumPy, SciPy, Pandas, Scikit=learn, Jupyter / IPython, Numba, Matplotlib, Spyder, Numexpr, Cython, Theano, Scikit=image, NLTK, NetworkX, IRKernel, dplyr, shiny, ggplot2, tidyr, caret, nnet and 330+ packages conda Easy to install Quick & agile data exploration Powerful data analysis Simple to collaborate Accessible to all
- 55. 55 • Infrastructure for meta-data, meta-compute, and expression graphs/dataflow • Data glue for scale-up or scale-out • Generic remote computation & query system • (NumPy+Pandas+LINQ+OLAP+PADL).mashup() Blaze is an extensible interface for data analytics. It feels like NumPy/Pandas. It drives other data systems. Blaze expressions enable high-level reasoning http://blaze.pydata.org Blaze
- 56. 56 Blaze ?
- 58. 58 Blaze + - / * ^ [] join, groupby, filter map, sort, take where, topk datashape,dtype, shape,stride hdf5,json,csv,xls protobuf,avro,... NumPy,Pandas,R, Julia,K,SQL,Spark, Mongo,Cassandra,...
- 59. 59 numpy pandas sql DB Data Runtime Expressions spark datashape metadata storage odo paralleloptimized dask numbaDyND blaze castra bcolz
- 60. 60 Data Runtime Expressions metadata storage/containers compute APIs, syntax, language datashape blaze dask odo parallelize optimize, JIT
- 61. 61
- 62. 62 Blaze Server Provide RESTful web API over any data supported by Blaze. Server side: >>> my_spark_rdd = … >>> from blaze import Server >>> Server(my_spark_rdd).run() Hosting computation on localhost:6363 Client Side: $ curl -H "Content-Type: application/json" -d ’{"expr": {"op": "sum", "args": [ ... ] }’ my.domain.com:6363/compute.json • Quickly share local data to collaborators on the web. • Expose any system (Mongo, SQL, Spark, in-memory) simply • Share local computation as well, sending computations to server to run remotely. • Conveniently drive remote server with interactive Blaze client
- 63. 63 Dask: Out-of-Core Scheduler • A parallel computing framework • That leverages the excellent Python ecosystem • Using blocked algorithms and task scheduling • Written in pure Python Core Ideas • Dynamic task scheduling yields sane parallelism • Simple library to enable parallelism • Dask.array/dataframe to encapsulate the functionality • Distributed scheduler coming
- 64. Example: Ocean Temp Data 64 • http://www.esrl.noaa.gov/psd/data/gridded/ data.noaa.oisst.v2.highres.html • Every 1/4 degree, 720x1440 array each day
- 65. Bigger data... 65 36 years: 720 x 1440 x 12341 x 4 = 51 GB uncompressed If you don't have this much RAM... ... better start chunking.
- 68. Core Concepts 68
- 69. dask.array: OOC, parallel, ND array 69 Arithmetic: +, *, ... Reductions: mean, max, ... Slicing: x[10:, 100:50:-2] Fancy indexing: x[:, [3, 1, 2]] Some linear algebra: tensordot, qr, svd Parallel algorithms (approximate quantiles, topk, ...) Slightly overlapping arrays Integration with HDF5
- 70. dask.dataframe: OOC, parallel, ND array 70 Elementwise operations: df.x + df.y Row-wise selections: df[df.x > 0] Aggregations: df.x.max() groupby-aggregate: df.groupby(df.x).y.max() Value counts: df.x.value_counts() Drop duplicates: df.x.drop_duplicates() Join on index: dd.merge(df1, df2, left_index=True, right_index=True)
- 71. More Complex Graphs 71 cross validation
- 73. 73 from dask import dataframe as dd columns = ["name", "amenity", "Longitude", "Latitude"] data = dd.read_csv('POIWorld.csv', usecols=columns) with_name = data[data.name.notnull()] with_amenity = data[data.amenity.notnull()] is_starbucks = with_name.name.str.contains('[Ss]tarbucks') is_dunkin = with_name.name.str.contains('[Dd]unkin') starbucks = with_name[is_starbucks] dunkin = with_name[is_dunkin] locs = dd.compute(starbucks.Longitude, starbucks.Latitude, dunkin.Longitude, dunkin.Latitude) # extract arrays of values fro the series: lon_s, lat_s, lon_d, lat_d = [loc.values for loc in locs] %matplotlib inline import matplotlib.pyplot as plt from mpl_toolkits.basemap import Basemap def draw_USA(): """initialize a basemap centered on the continental USA""" plt.figure(figsize=(14, 10)) return Basemap(projection='lcc', resolution='l', llcrnrlon=-119, urcrnrlon=-64, llcrnrlat=22, urcrnrlat=49, lat_1=33, lat_2=45, lon_0=-95, area_thresh=10000) m = draw_USA() # Draw map background m.fillcontinents(color='white', lake_color='#eeeeee') m.drawstates(color='lightgray') m.drawcoastlines(color='lightgray') m.drawcountries(color='lightgray') m.drawmapboundary(fill_color='#eeeeee') # Plot the values in Starbucks Green and Dunkin Donuts Orange style = dict(s=5, marker='o', alpha=0.5, zorder=2) m.scatter(lon_s, lat_s, latlon=True, label="Starbucks", color='#00592D', **style) m.scatter(lon_d, lat_d, latlon=True, label="Dunkin' Donuts", color='#FC772A', **style) plt.legend(loc='lower left', frameon=False);
- 74. 74 • Dynamic, just-in-time compiler for Python & NumPy • Uses LLVM • Outputs x86 and GPU (CUDA, HSA) • (Premium version is in Accelerate product) http://numba.pydata.org Numba
- 75. Python Compilation Space 75 Ahead Of Time Just In Time Relies on CPython / libpython Cython Shedskin Nuitka (today) Pythran Numba HOPE Theano Replaces CPython / libpython Nuitka (future) Pyston PyPy
- 76. Example 76 Numba
- 77. 77 @jit('void(f8[:,:],f8[:,:],f8[:,:])') def filter(image, filt, output): M, N = image.shape m, n = filt.shape for i in range(m//2, M-m//2): for j in range(n//2, N-n//2): result = 0.0 for k in range(m): for l in range(n): result += image[i+k-m//2,j+l-n//2]*filt[k, l] output[i,j] = result ~1500x speed-up
- 78. Features 78 • Windows, OS X, and Linux • 32 and 64-bit x86 CPUs and NVIDIA GPUs • Python 2 and 3 • NumPy versions 1.6 through 1.9 • Does not require a C/C++ compiler on the user’s system. • < 70 MB to install. • Does not replace the standard Python interpreter (all of your existing Python libraries are still available)
- 79. How Numba Works 79 Bytecode Analysis Python Function (bytecode) Function Arguments Type Inference Numba IR Rewrite IR Lowering LLVM IRLLVM JIT Machine Code @jit def do_math(a,b): … >>> do_math(x, y) Cache Execute!
- 81. Anaconda — portable environments 81 PYTHON'&'R'OPEN'SOURCE'ANALYTICS NumPy, SciPy, Pandas, Scikit=learn, Jupyter / IPython, Numba, Matplotlib, Spyder, Numexpr, Cython, Theano, Scikit=image, NLTK, NetworkX, IRKernel, dplyr, shiny, ggplot2, tidyr, caret, nnet and 330+ packages conda Easy to install Quick & agile data exploration Powerful data analysis Simple to collaborate Accessible to all
- 82. 82 • cross platform package manager • can create sandboxes ("environments"), akin to Windows Portable Applications or WinSxS • "un-container" for deploying data science/data processing workflows http://conda.pydata.org Conda
- 83. System Package Managers 83 yum (rpm) apt-get (dpkg) Linux OSX macports homebrew fink Windows chocolatey npackd Cross-platform conda
- 84. 84 • Excellent support for “system-level” environments — like having mini VMs but much lighter weight than docker (micro containers) • Minimizes code-copies (uses hard/soft links if possible) • Simple format: binary tar-ball + metadata • Metadata allows static analysis of dependencies • Easy to create multiple “channels” which are repositories for packages • User installable (no root privileges needed) • Integrates very well with pip • Cross Platform Conda features
- 85. Anaconda Cloud: analytics repository 85 • Commercial long-term support • Licensed for redistribution • Private, on-premises available • Proprietary tools for building custom distribution, like Anaconda • Enterprise tools for managing custom packages and environments • http://anaconda.org
- 86. Anaconda Cluster: Anaconda + Hadoop + Spark 86 For data scientists: • Rapidly, easily create clusters on EC2, DigitalOcean, on-prem cloud/provisioner • Manage Python, R, Java, JS packages across the cluster For operations & IT: • Robustly manage runtime state across the cluster • Outside the scope of rpm, chef, puppet, etc. • Isolate/sandbox packages & libraries for different jobs or groups of users • Without introducing complexity of Docker / virtualization • Cross platform - same tooling for laptops, workstations, servers, clusters
- 87. Cluster Creation 87 $ conda cluster create mycluster --profile=spark_profile $ conda cluster submit mycluster mycode.py $ conda cluster destroy mycluster spark_profile: provider: aws_east num_nodes: 4 node_id: ami-3c994355 node_type: m1.large aws_east: secret_id: <aws_access_key_id> secret_key: <aws_secret_access_key> keyname: id_rsa.pub location: us-east-1 private_key: ~/.ssh/id_rsa cloud_provider: ec2 security_group: all-open http://continuumio.github.io/conda-cluster/quickstart.html
- 88. 88 $ conda cluster manage mycluster list ... info -e ... install python=3 pandas flask ... set_env ... push_env <local> <remote> $ conda cluster ssh mycluster $ conda cluster run.cmd mycluster "cat /etc/hosts" Package & environment management: Easy SSH & remote commands: http://continuumio.github.io/conda-cluster/manage.html Cluster Management
- 89. Anaconda Cluster & Spark 89 # example.py conf = SparkConf() conf.setMaster("yarn-client") conf.setAppName("MY APP") sc = SparkContext(conf=conf) # analysis sc.parallelize(range(1000)).map(lambda x: (x, x % 2)).take(10) $ conda cluster submit MY_CLUSTER /path/to/example.py
- 90. Python & Spark in Practice 90 Challenges of real-world usage • Package management (perennial popular topic in Python) • Python (& R) are outside the "normal" Java build toolchain • bash scripts, spark jobs to pip install or conda install <foo> • Kind of OK for batch; terrible for interactive • Rapid iteration • Production vs dev/test clusters • Data scientist needs vs Ops/IT concerns
- 91. Fix it twice… 91 PEP 3118: Revising the buffer protocol Basically the “structure” of NumPy arrays as a protocol in Python itself to establish a memory-sharing standard between objects. It makes it possible for a heterogeneous world of powerful array-like objects outside of NumPy that communicate. Falls short in not defining a general data description language (DDL). http://python.org/dev/peps/pep-3118/
- 92. Putting Rest of NumPy in Std Lib 92 • memtype • dtype system on memory-views • extensible with Numba and C • extensible with Python • gufunc • generalized low-level function dispatch on memtype • extensible with Numba and C • usable by any Python Working on now with a (small) team — could use funding
- 93. 93 • Python has had a long and fruitful history in Data Analytics • It will have a long and bright future with your help! • Contribute to the PyData community and make the world a better place! The Future of Python
- 94. © 2015 Continuum Analytics- Confidential & Proprietary Thanks October1, 2015 •SIG for hosting tonight and inviting me to come •DARPA XDATA program (Chris White and Wade Shen) which helped fund Numba, Blaze, Dask and Odo. •Investors of Continuum. •Clients and Customers of Continuum who help support these projects. •Numfocus volunteers •PyData volunteers