



























































































![Training Augmentation
● Random crop/scale
○ random L in range [256, 480]
○ Resize training image, short side = L
○ Sample random 224x224 patch](https://image.slidesharecdn.com/convolutionalneuralnetworkinpractice1-161108055200/85/Convolutional-neural-network-in-practice-95-320.jpg)



![Testing Augmentation
● Multi-scale testing
○ Fully convolutional layer is mandatory
○ Random L in range [224, 640]
○ Resize training image such that short side
= L
○ Average(or max) scores
● Used in Resnet](https://image.slidesharecdn.com/convolutionalneuralnetworkinpractice1-161108055200/85/Convolutional-neural-network-in-practice-99-320.jpg)


























































Convolutional neural network in practice
- 1. Convolutional Neural Network in Practice 2016.11 [email protected]
- 3. Buzz words nowadays AI Deep learning Big dataMachine learning Reinforcement Learning ???
- 4. Glossary of AI terms From Roger Parloff, WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE (Fortune, 2016).
- 5. Definitions What is AI ? “Artificial intelligence is that activity devoted to making machines intelligent, and intelligence is that quality that enables an entity to function appropriately and with foresight in its environment.” Nils J. Nilsson, The Quest for Artificial Intelligence: A History of Ideas and Achievements (Cambridge, UK: Cambridge University Press, 2010). “a computerized system that exhibits behavior that is commonly thought of as requiring intelligence” Executive Office of the President National Science and Technology Council Committee on Technology: PREPARING FOR THE FUTURE OF ARTIFICIAL INTELLIGENCE (2016). “any technique that enables computers to mimic human intelligence” Roger Parloff, WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE (Fortune, 2016).
- 6. My diagram of AI terms Environment Data, Rules, Feedbacks ... Teaching Self-Learning, Engineering ... AI y = f(x) Catf F18f
- 7. Past, Present of AI
- 8. Decades-old technology ● Long long history. From 1940s … ● But, ○ Before Oct. 2012. ○ After Oct. 2012.
- 9. Venn diagram of AI terms From Ian Goodfellow, Deep Learning (MIT press, 2016).
- 11. Flowcharts of AI From Ian Goodfellow, Deep Learning (MIT press, 2016). E2E (end-to-end)
- 12. Image recognition error rate From https://www.nervanasys.com/deep-learning-and-the-need-for-unified-tools/ 2012
- 13. Speech recognition error rate 2012
- 14. 5 Tribes of AI researchers Symbolists (Rule, Logic-based) Connectionists (PDP assumption) Bayesians EvolutionistsAnalogizers vs.
- 15. Deep learning has had a long and rich history ! ● 3 re-brandings. ○ Cybernetics ( 1940s ~ 1960s ) ○ Artificial Neural Networks ( 1980s ~ 1990s) ○ Deep learning ( 2006 ~ )
- 16. Nothing new ! ● Alexnet 2012 ○ based on CNN ( LeCunn, 1989 ) ● Alpha Go ○ based on Reinforcement learning and MCTS ( Sutton, 1998 )
- 17. So, why now ? ● Computing Power ● Large labelled dataset ● Algorithm
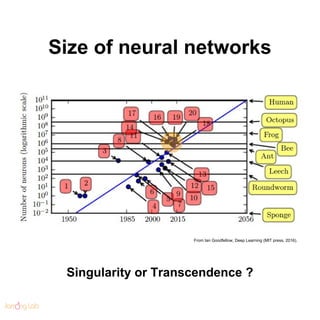
- 18. Size of neural networks From Ian Goodfellow, Deep Learning (MIT press, 2016). Singularity or Transcendence ?
- 19. Depth is KING !
- 20. Brief history of deep learning From Roger Parloff, WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE (Fortune, 2016). 1st Boom 2nd Boom1st Winter
- 21. Brief history of deep learning From Roger Parloff, WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE (Fortune, 2016).
- 22. Brief history of deep learning From Roger Parloff, WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE (Fortune, 2016). 2nd Winter
- 23. Brief history of deep learning From Roger Parloff, WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE (Fortune, 2016). 3rd Boom
- 24. Brief history of deep learning From Roger Parloff, WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE (Fortune, 2016).
- 25. So, when 3rd winter ? Nope !!! ● Features are mandatory in every AI problem. ● Deep learning is cheap learning! (Though someone can disprove the PDP assumptions, deep learning is the best practical tool in representation learning.)
- 26. Biz trends after Oct.2012. ● 4 big players leading this sector. ● Bloody hiring war. ○ Along the lines of NFL football players.
- 27. Biz trend after Oct.2012. ● 2 leading research firms. ● 60+ startups
- 28. Biz trend after Oct.2012.
- 29. Future of AI
- 30. Venn diagram of ML From David silver, Reinforcement learning (UCL cource on RL, 2015).
- 31. Unsupervised & Reinforcement Learning ● 2 leading research firms focus on: ○ Generative Models ○ Reinforcement Learning
- 33. Towards General Artificial Intelligence Strong AI vs. Weak AI General AI vs. Narrow AI
- 36. Generative Adversarial Network Xi Chen et al, InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets ( 2016 )
- 38. So what can we do with AI? ● Simply, it’s sophisticated software writing software. True personalization at scale!!!
- 39. Is AI really necessary ? “a lot of S&P 500 CEOs wished they had started thinking sooner than they did about their Internet strategy. I think five years from now there will be a number of S&P 500 CEOs that will wish they’d started thinking earlier about their AI strategy.” “AI is the new electricity, just as 100 years ago electricity transformed industry after industry, AI will now do the same.” Andrew Ng., chief scientist at Baidu Research.
- 40. Conclusion Computers have opened their eyes.
- 42. Convolution Neural Network ● Motivation ○ Sparse connectivity ■ smaller kernel size ○ Parameter sharing ■ shared kernel ○ Equivariant representation ■ convolution operation
- 43. Fully Connected(Dense) Neural Network ● Typical 3-layer fully connected neural network
- 44. Sparse connectivity vs. Dense connectivity Sparse Dense From Ian Goodfellow, Deep Learning (MIT press, 2016).
- 45. Parameter sharing (x1 , s1 ) ~ (x5 , s5 ) share a single parameter From Ian Goodfellow, Deep Learning (MIT press, 2016).
- 46. Equivariant representation Convolution operation satisfies equivariant property.
- 47. A bit of history From : http://cs231n.stanford.edu/slides/winter1516_lecture6.pdf
- 48. A bit of history From : http://cs231n.stanford.edu/slides/winter1516_lecture6.pdf
- 49. A bit of history From : http://cs231n.stanford.edu/slides/winter1516_lecture6.pdf
- 50. Basic module of 2D CNN
- 51. Pooling ● Average pooling = L1 pooling ● Max pooling = infinity norm pooling
- 52. Max Pooling ● To improve translation invariance.
- 53. Parameters of convolution ● Kernel size ○ ( row, col, in_channel, out_channel) ● Padding ○ SAME, VALID, FULL ● Stride ○ if S > 1, use even kernel size F > S * 2
- 54. 1 dimensional convolution pad(P=1) pad(P=1) pad(P=1) stride(S=1) kernel (F=3) stride(S=2) ● ‘SAME’(or ‘HALF’) pad size = (F - 1) * S / 2 ● ‘VALID’ pad size = 0 ● ‘FULL’ pad size : not used nowadays
- 55. 2 dimensional convolution From : https://github.com/vdumoulin/conv_arithmetic pad = ‘VALID’, F = 3, S = 1
- 56. 2 dimensional convolution From : https://github.com/vdumoulin/conv_arithmetic pad = ‘SAME’, F = 3, S = 1
- 57. 2 dimensional convolution From : https://github.com/vdumoulin/conv_arithmetic pad = ‘SAME’, F = 3, S = 2
- 58. Artifacts of strides From : http://distill.pub/2016/deconv-checkerboard/ F = 3, S = 2
- 59. Artifacts of strides F = 4, S = 2 From : http://distill.pub/2016/deconv-checkerboard/
- 60. Artifacts of strides From : http://distill.pub/2016/deconv-checkerboard/ F = 4, S = 2
- 61. Pooling vs. Striding ● Same in the downsample aspect ● But, different in the location aspect ○ Location is lost in Pooling ○ Location is preserved in Striding ● Nowadays, striding is more popular ○ some kind of learnable pooling
- 62. Kernel initialization ● Random number between -1 and 1 ○ Orthogonality ( I.I.D. ) ○ Uniform or Gaussian random ● Scale is paramount. ○ Adjust such that out(activation) values have mean 0 and variance 1 ○ If you encounter NaN, that may be because of ill scale.
- 63. Gabor Filter
- 65. Initialization guide ● Xavier(or Glorot) initialization ○ http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a .pdf ● He initialization ○ Good for RELU nonlinearity ○ https://arxiv.org/abs/1502.01852 ● Use batch normalization if possible ○ Immune to ill-scaled initialization
- 67. Guide ● Start from robust baseline ○ 3 choices ■ VGG, Inception-v3, Resnet ● Smaller and deeper ● Towards getting rid of POOL and final dense layer ● BN and skip connection are popular
- 68. VGG
- 69. VGG ● https://arxiv.org/abs/1409.1556 ● VGG-16 is good start point. ○ apply BN if you train from scratch ● Image input : 224x224x3 ( -1 ~ 1 ) ● Final outputs ○ conv5 : 7x7x512 ○ fc2 : 4096 ○ sm : 1000
- 70. VGG practical tricks ● If gray image ○ divide all feature nums by 2 ● Replace FCs with fully convolutional layers ○ variable size input image ○ training/evaluation augmentation ○ read 4~5 pages in this paper
- 71. Fully connected layer ● conv5 output : 7x7x512 ● Fully connected layer ○ flatten : 1x25088 ○ fc1 weight: 25088x4096 ■ output : 1x4096 ○ fc2 weight: 4096x4096 ■ output : 1x4096 ○ Fixed size image only
- 72. Fully convolutional layer ● conv5 output : 7x7x512 ● Fully convolutional layer ○ fc1 ← conv 7x7@4096 ■ output : (row-6)x(col-6)x4096 ○ fc2 ← conv 1x1@4096 ■ output : (row-6)x(col-6)x4096 ○ Global average pooling ■ output : 1x1x4096 ○ Variable sized images
- 73. VGG Fully convolutional layer From : https://github.com/buriburisuri/sugartensor/blob/master/sugartensor/sg_net.py
- 74. Google Inception
- 75. Google Inception ● https://arxiv.org/pdf/1512.00567.pdf ● Bottlenecked architecture. ○ 1x1 conv ○ latest version : v5 ( v3 is popular ) ● Image input : 224x224x3 ( -1 ~ 1 ) ● Final output ○ conv5 : 7x7x1024 ( or 832 ) ○ fc2 : 1024 ○ sm : 1000
- 77. Batch normalization ● Extremely powerful ○ Use everywhere possible ○ Absorb biases to BN’s shifts
- 78. Resnet
- 79. Resnet ● https://arxiv.org/pdf/1512.03385v1.pdf ● Residual block ○ skip connection + stride ○ bottleneck block ● Image input : 224x224x3 ( -1 ~ 1 ) ● Final output ○ conv5 : 7x7x2048 ○ fc2 : 1x1x2048 ( average pooling ) ○ sm : 1000
- 80. Resnet ● Very deep using skip connection ○ Now, v2 - 1001 layer architecture ● Now, Resnet-152 v2 is the de-facto standard
- 82. Summary ● Start from Resnet-50 ● Use He’s initialization ● learning rate : 0.001 (with BN), 0.0001 (without BN) ● Use Adam ( should be alpha < beta ) optim ○ alpha=0.9, beta=0.999 (with easy training) ○ alpha=0.5, beta=0.95 (with hard training)
- 83. Summary ● Minimize hyper-parameter tuning or architecture modification. ○ Deep learning is highly nonlinear and count-intuitive ○ Grid or random search is expensive
- 84. Visualization
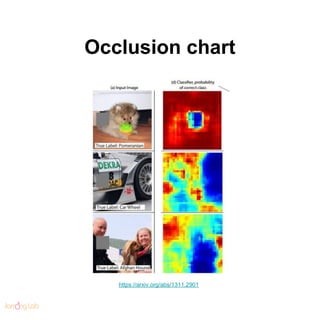
- 88. Occlusion chart https://arxiv.org/abs/1311.2901
- 90. CAM : Class Activation Map http://cnnlocalization.csail.mit.edu/
- 91. Saliency Maps From : http://cs231n.stanford.edu/slides/winter1516_lecture9.pdf
- 92. Deconvolution approach From : http://cs231n.stanford.edu/slides/winter1516_lecture9.pdf
- 93. Augmentation
- 94. Augmentation ● 3 types of augmentation ○ Traing data augmentation ○ Evaluation augmentation ○ Label augmentation ● Augmentation is mandatory ○ If you have really big data, then augment data and increase model capacity
- 95. Training Augmentation ● Random crop/scale ○ random L in range [256, 480] ○ Resize training image, short side = L ○ Sample random 224x224 patch
- 96. Training Augmentation ● Random flip/rotate ● Color jitter
- 97. Training Augmentation ● Random flip/rotate ● Color jitter ● Random occlude
- 98. Testing Augmentation ● 10-crop testing ( VGG ) ○ average(or max) scores
- 99. Testing Augmentation ● Multi-scale testing ○ Fully convolutional layer is mandatory ○ Random L in range [224, 640] ○ Resize training image such that short side = L ○ Average(or max) scores ● Used in Resnet
- 100. Advanced Augmentation ● Homography transform ○ https://arxiv.org/pdf/1606.03798v1.pdf
- 101. Advanced Augmentation ● Elastic transform for medical image ○ http://users.loni.usc.edu/~thompson/MAP/warp.html
- 103. Other Augmentation ● Be aggressive and creative!
- 104. Feature level Augmentation ● Exploit equivariant property of CNN ○ Xu shen, “Transform-Invariant Convolutional Neural Networks for Image Classification and Search”, 2016 ○ Hyo-Eun Kim, “Semantic Noise Modeling for Better Representation Learning”, 2016
- 105. Image Localization
- 106. Localization and Detection From : http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
- 107. Classification + Localization From : http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
- 108. Simple recipe CE loss L2(MSE) loss Joint-learning ( Multi-task learning ) or Separate learning From : http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
- 109. Regression head position From : http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
- 110. Multiple objects detection From : http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
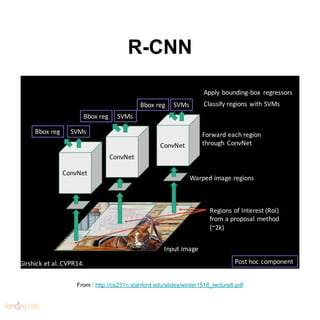
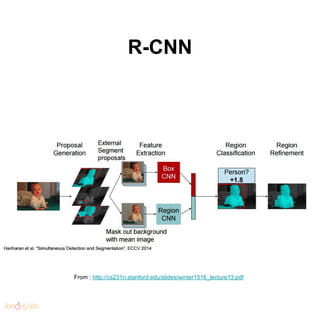
- 112. Fast R-CNN From : http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
- 113. Faster R-CNN From : http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
- 114. Faster R-CNN ● https://arxiv.org/pdf/1506.01497.pdf ● de-facto standard From : http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
- 115. Segmentation
- 116. Semantic Segmentation From : http://cs231n.stanford.edu/slides/winter1516_lecture13.pdf
- 117. Naive recipe From : http://cs231n.stanford.edu/slides/winter1516_lecture13.pdf
- 118. Fast recipe From : http://cs231n.stanford.edu/slides/winter1516_lecture13.pdf
- 119. Multi-scale refinement From : http://cs231n.stanford.edu/slides/winter1516_lecture13.pdf
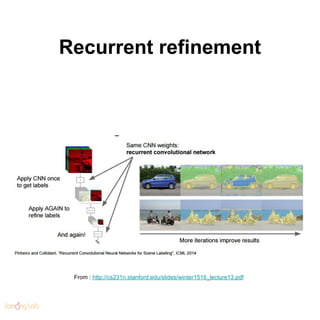
- 120. Recurrent refinement From : http://cs231n.stanford.edu/slides/winter1516_lecture13.pdf
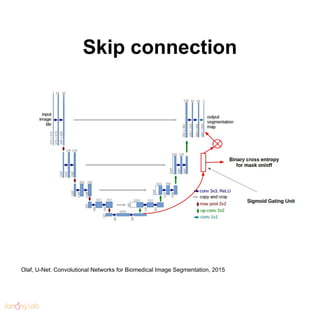
- 123. Skip connection Olaf, U-Net: Convolutional Networks for Biomedical Image Segmentation, 2015
- 124. Instance Segmentation From : http://cs231n.stanford.edu/slides/winter1516_lecture13.pdf
- 128. Deconvolution ● Learnable upsampling ○ resize * 2 + normal convolution ○ controversial names ■ deconvolution, convolution transpose, upconvolution, backward strided convolution, ½ strided convolution ○ Artifacts by strides and kernel sizes ■ http://distill.pub/2016/deconv-checkerboard/ ○ Restrict the freedom of architectures
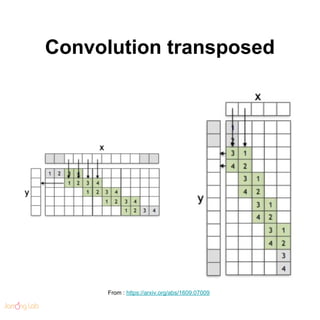
- 129. Convolution transposed From : https://arxiv.org/abs/1609.07009
- 130. ½ strided(sub-pixel) convolution From : https://arxiv.org/abs/1609.07009
- 131. ESPCN ( Efficient Sub-pixel CNN) Periodic shuffle Wenzhe, Real-Time Single Image and Video Super-Resolution Using and Efficient Sub-Pixel Convolutional Neural Network, 2016
- 132. L2 loss issue Christian, Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 2016
- 134. Videos
- 137. Long-Time ST-CNN From : http://cs231n.stanford.edu/slides/winter1516_lecture14.pdf
- 138. Long-Time ST-CNN From : http://cs231n.stanford.edu/slides/winter1516_lecture14.pdf
- 139. Summary ● Model temporal motion locally ( 3D CONV ) ● Model temporal motion globally ( RNN ) ● Hybrids of both ● IMHO, RNN will be replaced with 1D convolution dilated (atrous convolution)
- 141. Stacked Autoencoder
- 142. Stacked Autoencoder ● Blurry artifacts caused by L2 loss
- 143. Variational Autoencoder ● Generative model ● Blurry artifacts caused by L2 loss
- 144. Variational Autoencoder ● SAE with mean and variance regularizer ● Bayesian meets deep learning
- 145. Generative Model ● Find realistic generating function G(x) by deep learning !!! y = G(x) G : Generating function x : Factors y : Output data
- 146. GAN (Generative Adversarial Networks) Ian. J. Fellow et al. Generative Adverserial Networks. 2014. ( https://arxiv.org/abs/1406.2661)
- 147. Discriminator
- 148. Generator
- 149. Adversarial Network
- 150. Results ( From Ian. J. Fellow et al. Generative Adverserial Networks. 2014. ) ( From P. Kingma et al. Auto-Encoding Variational Bayes. 2013. )
- 151. Pitfalls of GAN ● Very difficult to train. ○ No guarantee to Nash Equilibrium. ■ Tim Salimans et al, Improved Techniques for Training GANS, 2016. ■ Junbo Zhao et al, Energy-based Generative Adversarial Network, 2016. ● Cannot control generated data. ○ How can we condition generating function G(x)?
- 152. InfoGAN Xi Chen et al. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets, 2016 ( https://arxiv.org/abs/1606.03657 ) ● Add mutual Information regularizer for inducing latent codes to original GAN.
- 153. InfoGAN
- 154. Results ( From Xi Chen et al. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets)
- 155. Results Interpretable factors interfered on face dataset
- 156. Supervised InfoGAN
- 158. AC-GAN ● Augustus, “Conditional Image Synthesis With Auxiliary Classifier GANs”, 2016
- 159. Features of GAN ● Unsupervised ○ No labelled data used ● End-to-end ○ No human feature engineering ○ No prior nor assumption ● High fidelity ○ automatic highly non-linear pattern finding ⇒ Currently, SOTA in image generation.
- 160. Skipped topics ● Ensemble & Distillation ● Attention + RNN ● Object Tracking ● And so many ...
- 161. Computers have opened their eyes.
- 162. Thanks