Creating Highly-Available MongoDB Microservices with Docker Containers and Kubernetes
Download as PPTX, PDF8 likes5,050 views

The document discusses deploying highly available MongoDB microservices using Docker and Kubernetes, focusing on building stateful sets for MongoDB deployments. Key topics include Kubernetes benefits, managing pods and services, persistent storage, and ensuring high availability through replica sets. The presentation also covers best practices for resource allocation, scheduling, and scaling in a microservices architecture.

























![#MDBW17
COMPUTE RESOURCES FOR CONTAINERS
We can define how much CPU and memory each container needs
CPU
Memory
Requests
Limits
How much I’d like to get
(scheduling)
The most I can get
(contention)
CPU Units:
spec.containers[].resources.limits.cpu
spec.containers[].resources.requests.cpu
Bytes:
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.memory
Scheduler
Ensures that the sum of the resource requests
of the scheduled containers is less than the
capacity of the node.](https://image.slidesharecdn.com/crystaladay21140-1220marcobonezzicreatinghighly-availablemongodbmicroserviceswithdockercontainersand-170621223531/85/Creating-Highly-Available-MongoDB-Microservices-with-Docker-Containers-and-Kubernetes-27-320.jpg)







Creating Highly-Available MongoDB Microservices with Docker Containers and Kubernetes
- 1. CREATING HIGHLY-AVAILABLE MONGODB MICROSERVICES WITH DOCKER CONTAINERS AND KUBERNETES Marco Bonezzi Senior Technical Services Engineer, MongoDB @marcobonezzi [email protected]
- 2. About the speaker I am Marco Bonezzi: Senior TSE at MongoDB TSE = Help customers to be successful with MongoDB Based in Dublin, Ireland Experience in databases, distributed systems, high availability and containers:
- 4. #MDBW17 THERE ARE COMMON PROBLEMS WHEN USING CONTAINERS: Capacity Connectivity State Isolation Affinity How do we manage all these?
- 5. #MDBW17 THIS IS WHAT WE WILL LEARN TODAY 1. Deploy MongoDB on containers using Kubernetes 2. Build a StatefulSet for our MongoDB deployment 3. Production-like recommendations for replica sets on GCE 4. High-Availability considerations for a micro-service application
- 6. #MDBW17 1. MONGODB ON CONTAINERS USING KUBERNETES • Why MongoDB is a good fit for microservices: • Benefits of using Kubernetes: Automate the distribution and scheduling of MongoDB containers across a cluster in a more efficient way. Time to market Scalability Resiliency Allignment (API) Flexible Data Model Redundancy Orchestration Persistency Monitoring
- 7. #MDBW17 KUBERNETES BUILDING BLOCKS Node: Provide capacity o Worker machine for pods (and their containers) o Virtual or physical o Can be grouped in a cluster, managed by master CPU Memory CPU Memory Pod Pod Pod
- 8. #MDBW17 Pod: Consume capacity Group of one or more application containers + shared resources for those containers container container container container Volume Volume Volume IP Image Port … … POD
- 9. #MDBW17 Container: Units of packaging Isolated process. Based on the Linux kernel: • Namespaces: what a process can see • cgroups: what a process can use Application + dependencies + shared kernel+ libraries container mongod –dbpath /data/db --port 27017 container
- 10. #MDBW17 Service Allow your application to receive traffic o Logical set of Pods and a policy by which access them o LabelSelector to define pods targeted o Types available: ClusterIP, NodePort, LoadBalancer, ExternalName or Headless Service Service B: 10.10.9.3 Service A: 10.10.9.4 POD NODE
- 11. #MDBW17 BASIC REPLICA SET EXAMPLE Node S P S mongod mongodmongod https://github.com/kubernetes/minikube
- 12. #MDBW17 BASIC REPLICA SET EXAMPLE https://github.com/sisteming/mongo-kube/tree/master/demo1
- 13. #MDBW17 2. BUILDING OUR MONGODB STATEFULSET • StatefulSet: Designed for applications that require • Components required: Stable, unique network identifiers mongo-1 mongo-n ... Volu me Volu medata Stable, persistent storage 1 2 3 n Ordered, graceful deployment and scaling Ordered, graceful deletion and terminationPersistent Volume Claim Headless Service StatefulSet
- 14. #MDBW17 STATEFULSET • Provide a unique identity to its Pods, comprised of an ordinal Identity stays with the Pod, regardless of which node it is scheduled on Hostnames: Pods created, scaled and deleted sequentially (i.e. mongo-{0..N-1}) mongo-1 mongo-2mongo-0 BETA FEATURE FROM KUBERNETES 1.5
- 15. #MDBW17 HEADLESS SERVICE • Similar to Kubernetes services but without any load balancing ‒ Combined with StatefulSets: unique DNS addresses to access pods ‒ Template for DNS name is <pod-name>.<service-name> I’m mongo-1.mongo! Cool, I can add you two to the replica set I’m mongo-2.mongo! rs.initiate() rs.add(“mongo-1.mongo:27017”) rs.add(“mongo-2.mongo:27017”)
- 16. #MDBW17 PERSISTENT STORAGE VOLUMES • Storage: critical component for Stateful containers • Dynamic volume provisioning: Before: provision new storage, then create volume in Kubernetes Now: dynamic provision using provisioner defined Persistent Volume Physical Storage Persistent Volume Claim Persistent Volume Persistent Volume Claim POD POD StatefulSet STABLE FROM KUBERNETES 1.6
- 19. #MDBW17 MONGODB STATEFUL SET POD - mongo-0 container (mongod) POD - mongo-1 POD - mongo-2 SSD volume SSD volume SSD volume Headless Service (*.mongo, 27017) container (mongod) container (mongod) Application
- 20. #MDBW17 SUMMARY: WHAT MAKES STATEFUL SETS GREAT FOR MONGODB Unique pod identity Stable network Stable storage Scaling Known and predictable hostnames Persistency resilient to rescheduling Scale application reads Easier to manage
- 21. #MDBW17 DEMO 2: REPLICA SET AS A STATEFULSET mongo-watch: https://github.com/sisteming/mongo- kube/tree/master/mongo-watch https://github.com/sisteming/mongo-kube/tree/master/demo2
- 22. #MDBW17 Node 2Node 1 3. ORCHESTRATING AND DEPLOYING PRODUCTION-LIKE STATEFULSET Node 0 rs0 • Replica Sets are about High Availability rs0 rs0 How do we ensure all containers are evenly distributed?
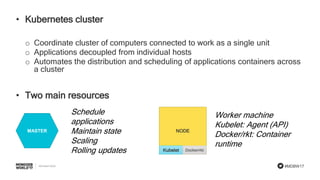
- 23. #MDBW17 • Kubernetes cluster o Coordinate cluster of computers connected to work as a single unit o Applications decoupled from individual hosts o Automates the distribution and scheduling of applications containers across a cluster • Two main resources MASTER NODE Kubelet Docker/rkt Schedule applications Maintain state Scaling Rolling updates Worker machine Kubelet: Agent (API) Docker/rkt: Container runtime
- 24. #MDBW17 POD SCHEDULING • Master controls nodes (minions) via Scheduler • Responsible for tracking all resources and pods • Takes care of: Resource requirements Constraints Affinity/Anti-affinity
- 25. #MDBW17 SCHEDULING OUR REPLICA SET MEMBERS nodeSelector Node labels Affinity Eligible if node has each of the k-v pairs as labels Node 1 mongod-RS1 env: prod rs: rs0 env: prod rs: rs0 env: test rs: rs-t1 mongod-RS1 Hostname os Instance arch Standard set of labels, beta.kubernetes.io Soft/hard constraints on nodes and pods nodeAffinity Affinity or anti- Affinity node labels labels on pods currently running BETA FEATURES IN KUBERNETES 1.6
- 26. #MDBW17 DISTRIBUTION OVER MULTIPLE NODES Node 2Node 1Node 0 mongo-0 / rs0 mongo-1 / rs0 mongo-2 / rs0
- 27. #MDBW17 COMPUTE RESOURCES FOR CONTAINERS We can define how much CPU and memory each container needs CPU Memory Requests Limits How much I’d like to get (scheduling) The most I can get (contention) CPU Units: spec.containers[].resources.limits.cpu spec.containers[].resources.requests.cpu Bytes: spec.containers[].resources.limits.memory spec.containers[].resources.requests.memory Scheduler Ensures that the sum of the resource requests of the scheduled containers is less than the capacity of the node.
- 28. #MDBW17 HIGH AVAILABILITY IN OUR STATEFULSET Replicated copy of our data Automatic failover Scalability of read operations Container restart (same node) Container reschedule (diff. node) Persistent volumes MongoDB Replica Set Kubernetes + Stateful Sets
- 29. #MDBW17 4. MICROSERVICE APPLICATIONS WITH MONGODB ON KUBERNETES STATEFULSET Connecting our microservice application (within Kubernetes) mongodb://mongo-0.mongo,mongo-1.mongo,mongo- 2.mongo:27017/APP_? Cases to be handled: o High Availability: 1. Failover (change of primary in the replica set) 2. Pod killed (i.e. Pod is killed and it comes back up) 3. Pod rescheduled (i.e. Node is down and pod gets scheduled to a different node) o Geographically distributed reads: 1. Read from nearest secondary using ReadPreference + Replica Set tags
- 30. #MDBW17 DEMO: Q&A LIST Scenarios: 1. Replica Set failover 2. Pod with primary mongod is killed 3. Node with primary mongod is
- 31. #MDBW17 DEMO 3: MONGODB REPLICA SET STATEFULSET ON GOOGLE CLOUD ENGINE https://github.com/sisteming/mongo-kube/tree/master/demo3
- 32. #MDBW17 SUMMARY Key elements for a successful MongoDB Stateful Set on Kubernetes Resource requests/limit s Persistent state Isolation AffinityScheduling Unique network identifiers High Availability Labels Monitoring Liveness Probes Disruption Budget Further improvements
Editor's Notes
- #2: Thank you everybody for being here today for this talk. It is really exciting to be speaking today about these technologies, MongoDB, Docker containers and Kubernetes, We get many questions on how to combine these technologies successfully and in this talk, you’ll learn some useful information that will help you to build successful micro-services using MongoDB on Kubernetes.
- #3: Let me introduce myself, my name is Marco Bonezzi, I’m a Senior TSE (or Technical Services Engineer) at MongoDB. What TSE really means is that we help customers to be successful with MongoDB by assisting them to make the most from MongoDB for their particular solution. I am based in Dublin, in Ireland My main experience is in databases, distributed systems and high availability solutions with different database technologies
- #4: In the last few years, microservices architectures have become more and more frequent even for traditinal organisations. You might be familiar with the 12 factor app: codebase, dependencies, Config,backing services,build-release-run,processes, All data which needs to be stored must use a stateful backing service, usually a database. And from our experience, MongoDB is a database frequently used to build such microservice architectures.
- #5: This also means that we have seen many cases and articles covering both the problems or defects of Docker containers - How to manage and distribute containers? - How to combine container technologies with a MongoDB highly available architecture? - Should I even use containers for stateful applications and store any data? This doesn’t mean that containers are bad or shouldn’t be used. But it means that there are important things to consider when implemeting our application on a microservice architecture. It’s easy to find examples on sample apps deployed on containers. But to be successful with containers, we need to manage elements like: Capacity Affinity Isolation, State… How do we manage this when we only want to deploy our application and make sure it will be resilient and highly available?
- #6: We will see how to deploy MongoDB containers in Kubernetes How we move to the next step, what is a statefulset and how to implement a StatefulSet for our MongoDB replica set How we manage and orchestrate it using Kubernetes How a toy microservice application will interact with MongoDB running on a StatefulSet in terms of High Availability
- #7: MongoDB is a common datastore frequently used for microservices, due to its features for scalability, high availability or flexible data model. When talking about microservices, Kubernetes is becoming the default solution to manage and orchestrate containers, and for our MongoDB cluster, it can help us to orchestrate and schedule correctly our containers and also help us with the persistency for each of them.
- #8: You may be already familiar with these concepts, but we will cover the basic Kubernetes building blocks required for our MongoDB cluster. The first element are the nodes, which provide capacity to run our containers or pods. These are the worker machines that will provide resources like memory and CPU for our containers. In common configurations, nodes are grouped in a cluster, which are managed by a Kubernetes master.
- #9: Pods are logical groups of one or more containers + resources for each that can be shared between them like volumes or IP addresses. They will use the capacity provided by the nodes to run the processes running into each container.
- #10: You are all probably aware of what containers are at this point. Containers are generally based on Docker runtime engine where a process in userspace is run in isolation from the rest of the processes in the system. A different defintion can also see “container” is just a term people use to describe a combination of Linux namespaces and cgroups. The confusion with containers occurs when we assume that they fulfill the same use case as VMs, zones or jails; which they do not. Containers allow for a flexibility and control that is not possible with Jails, Zones, or VMs. And THAT IS A FEATURE. These features are what is pushing the use of containers as a basic unit of packaging for our applications.
- #11: Once we have our containers running, the next step is to allow our application to receive traffic. This is done by using services, where we define a logical set of pods and a policy by which we will access each of them. For instance, there are different types like NodePort, LoadBalancer or ClusterIP and the decision on which one we’ll use is based on the access pattern required for the type of application we deploy.
- #12: Now that we know the basic elements in a Kubernetes deployment, we will start by deploying a really simple replica set with 3 pods, each running the mongod process, in a singe Kubernetes node using minikube. Minikube runs a single-node Kubernetes cluster inside a VM on your laptop for users looking to try out Kubernetes or develop with it day-to-day. With these basic steps, we will see how to connect each container to configure the replica set so that we will have a primary node and two secondaries.
- #13: You can find the details and steps for this first test in the link above. In this example, we are using the IP for each pod as by default the hostname won’t be reachable by others.
- #14: Ok so we’ve seen how to deploy a replica set in Kubernetes, but this was a very simple and manual approach. The next step in our journey is now to build a StatefulSet (previously known as petsets) which is a special Kubernetes controller designed for applications that need: Unique network identifiers Persistent storage Ordered, gracefuly deployment, scaling and termination To create a statefulset, there are some elements we need to create in advance: Persistent Volumes Headless service, special for this use case And then the statefulset itself
- #15: Statefulsets were added as beta feature from Kubernetes 1.5, but it is becoming a critical solution for Kubernetes to handle stateful, distributed applications as MongoDB clusters. One of the key points of StatefulSets is the use of unique identity for each pod, including an ordinal. This means that the hostname for each pod will be based on the statefulset name + an ordinal and pods will be created, scaled and deleted sequentially based on this identity.
- #16: Headless Services in Kubernetes are similar to other services, but without any load balancing, which for our case, makes sense. Kubernetes schedules a DNS Pod and Service on the cluster. Every Service is assigned a DNS name. Unlike normal Services, this resolves to the set of IPs of the pods selected by the Service. This means that each pod will be able to contact the rest of pods in the statefulset just by using the statefulset name (mongo), the ordinal (0,1,2) and the headless service (mongo). And this can be quite handy not only for inter-node connectivity (which is based on an overlay network), but also for easier replica set configuration.
- #17: Statefulset are aimed to provide a solution to maintain the state for stateful applications. This solution is based on persistent storage and dynamic volume provisioning, included as stable in Kubernetes 1.6. We have physical storage defined, from which Kubernetes will create Persistent Volumes to be used by the Persistent Volume Claims. From the Pod’s point of view, the claim is a volume. The difference between PV and PVC is that we can have a PV from which we create multiple PVC with smaller size. For example, when using minikube, we will have to manually create both PV and PVC. But when deploying on GCE, Azure and AWS, Kubernetes will already have the required provisioner for dynamic provision these elements.
- #18: This is an example of a Stateful set yaml configuration file We can see here the definition of Service, replicas 3 Labels Specs and affinity rules we’ll see next Containers definition and command Volume mounts and volume cliam templates Persistent storage
- #19: This is an example of a Stateful set yaml configuration file We can see here the definition of Service, replicas 3 Labels Specs and affinity rules we’ll see next Containers definition and command Volume mounts and volume cliam templates Persistent storage
- #20: Now that we covered the main components for our MongoDB replica set as a statefulset, we can see here the diagram of the architecture for the Statefulset deployment. Each container, running the mongod process, will have a unique hostname with an identifier. Each will be also attached to a SSD volume based on Persistent storage on the node where the POD is running. The headless Service then, defined on the default port for MongoDB, means that we will be able to access each node as mongo-0.mongo on the port 27017. Our application then can connect with these details.
- #21: StatefulSets are a great addition to Kubernetes, as it provides better options for distributed applications like MongoDB. Easier to manage each MongoDB pod Configure and scale based on predictable hostnames Persistent volumes bound to each pod, regardless of the node where they run Increased availability and Scale reads of your application with multiple secondaries
- #22: Now that we learned what StatefulSets are and how they can benefit MongoDB running on Kubernetes, we can see how we can implement them. With StatefulSet and Kubernetes, we can use Kubernetes features like init containers or jobs to configure the MongoDB replica set. In this case, I wrote a simple shell script executed by a Kubernetes job that will monitor the replica set members, configure each of them as primary and secondaries, and eventually also add new members as replica sets if a new container is detected using the hostname convention.
- #23: When deploying MongoDB in production, we want to deploy always a replica set, ideally Primary and 2 or more secondaries. When using containers, it is important to realise that running MongoDB on 3 or more containers for a replica set is not enough. We also need to ensure that each member of the replica set / each container, is located in a different node than the rest of members for the same replica set. How can we do this with Kubernetes?
- #24: For a Production deployment of Kubernetes, we need to build a Kubernetes cluster with 3 or more nodes. They will work as a single unit and automate the distribution and scheduling of applications thanks to the Master node and its integrated scheduler. The two main resources for a Kubernetes cluster: Master => Responsible to schedule the applications into each node, to maintain the state as well as to scale or perform rolling updates in a given deployment Worker nodes => They each have the Kubelet (agent using the API to talk to the API Server) and then Docker or rkt as the container runtime engine responsible of running the containers.
- #25: A critical element for every Orchestration tool like Swarm or Kubernetes, is the ability and flexibility to schedule containers to the available worker nodes. This work is done by the Scheduler process running on the master, which is responsible for tracking all resources and pods. For example, when we run a pod in Kubernetes, the Scheduler on the master will check which nodes are eligible to meet: Any resource requirements from the pod Any constraints defined in the pod definition (like labels for the environment type) Affinity or anti-affinity requested by the pod, both inter-node and inter-pod
- #26: Once we know we have to distribute each replica set member / each container across different nodes, we need to think at ways of doing this in an automated way. We have different options to do this, but the most relevant are: nodeSelector: filter eligible nodes based on labels (like replica set or type of environment) Node labels: Hostname, instance type or OS (for example, avoid a specific hostname or OS) Affinity: Soft or hard constraints on nodes and pods running on nodes. (for example, if a given pod is running on a given node, don’t pick that node) This last concept of affinity or anti-affinity is actually really useful and can help us whith our purpose: we can define a hard affinity constraint so that the Scheduler wont schedule a pod for rs1 on a node where there is already a pod for rs1 running. https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
- #27: Based on this logic, we can see how it is fairly easy to define this type of pod affinity constraint just based on key-value expressions. In this example, we have a cluster created on Google Cloud, where each node is located in a different zone within europe-west. With this approach, we can deploy each container for rs1 (mongo-0, mongo-1 and mongo-2) onto each of these nodes. We can see with get pod –o wide the actual node where the pods are running and how we achieved our goal of having each pod in a different node. This also means that, when using such a hard affinity constraint, If let’s say node1 becomes unavailable, it won’t be possible to schedule a pod for rs1 on the 2 remaining nodes. TRADEOFF scheduler } Warning FailedScheduling No nodes are available that match all of the following predicates:: NoVolumeZoneConflict (2).
- #28: A key element to be aware of is the resources used by each container. By default there will be no resource request or limit set. But it is a good practice in particular with databases as MongoDB to define the expected boundaries for the resource utilization, as this will help to prevent performance issues due to resource contention (multiple containers on same node) In Kubernetes, we can define request (how much the container would like to get) and limits (how much the container can get). An important point here is that the WiredTiger cache size in MongoDB is based on the total memory on the system, not on the container. It is critical then to set the cache size manually to 50% of the memory limit we define. The Kubernetes scheduler compare the resource requests to the capacity in the available nodes, and will select the target node also based on this capacity. Important to understand application behaviour when reaching for example the memory limit, as this can trigger unexpected behaviours or even the pod to be terminated.
- #29: Availability of our micro-service application is important so we can see the benefits from MongoDB and Kubernetes: The use of replica set will guarantee the high availability by having: - replicated copy of our data, - automatic failover - further scalability of read operations by scaling the number of secondary nodes. In addition to this, Kubernetes StatefulSets provide us with increased availability as: Containers killed/delete are restarted on the same node In case of a node becoming unavailable, containers will be re-scheduled to different available nodes Persistent volumes are bound to the container, so even when a node becomes unavailable, the container rescheduled on a different node will be able to use its previously used persistent volume.
- #30: At this point, we have a fully configured replica set running on a Kubernetes StatefulSet. With this, we can then connect our micro-service application by providing the connecting string of the replica set, with all nodes involved. There is a great talk from last year MongoDB World from my colleague Jesse: MongoDB World 2016: Smart Strategies for Resilient Applications In summary, the cases we need to handle are: HA Failover (change of primary) A pod gets killed A Pod is rescheduled to a different node Scalability Scale the reads with multiple secondaries
- #31: MongoDB World 2016: Smart Strategies for Resilient Applications
- #33: In summary, we have seen the various building blocks of Kubernetes, and how we can implement a MongoDB replica set using StatefulSets in Kubernetes. While this might seem complex, we can see how we handled Scheduling, affinity, resource requests and limits thanks to cgroups, how statefulset provide us with Unique network identifiers and persistent state for our MongoDB replica set, and how we can handle isolation and high availability by using labels and affiniity rules. Possible improvements can include: Liveness probes: tests to detect if the service from a container is alive Disruption Budget: What is the minimal configuration in terms of pods and nodes that our application or service can afford In Summary, we can see how the use of containers and Kubernetes is not only getting our application to run on containers, but once we are there, there are multiple features that we can use to improve the availability and resiliency of our applications, which at the end of the day can help our lives as engineers but also the business of our companies.