





![© NVIDIA Corporation 2008
Kernel = Many Concurrent Threads
One kernel is executed at a time on the device
Many threads execute each kernel
Each thread executes the same code…
… on different data based on its threadID
0 1 2 3 4 5 6 7
…
float x = input[threadID];
float y = func(x);
output[threadID] = y;
…
threadID
CUDA threads might be
Physical threads
As on NVIDIA GPUs
GPU thread creation and
context switching are
essentially free
Or virtual threads
E.g. 1 CPU core might execute
multiple CUDA threads](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-7-320.jpg)
![© NVIDIA Corporation 2008
Hierarchy of Concurrent Threads
Threads are grouped into thread blocks
Kernel = grid of thread blocks
…
float x =
input[threadID];
float y = func(x);
output[threadID] = y;
…
threadID
Thread Block 0
…
…
float x =
input[threadID];
float y = func(x);
output[threadID] = y;
…
Thread Block 1
…
float x =
input[threadID];
float y = func(x);
output[threadID] = y;
…
Thread Block N - 1
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
By definition, threads in the same block may synchronize with
barriers
scratch[threadID] = begin[threadID];
__syncthreads();
int left = scratch[threadID - 1];
Threads
wait at the barrier
until all threads
in the same block
reach the barrier](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-8-320.jpg)











![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host Device](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-20-320.jpg)
![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host
a_h
b_h](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-21-320.jpg)
![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host Device
a_h
b_h
a_d
b_d](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-22-320.jpg)
![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host Device
a_h
b_h
a_d
b_d](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-23-320.jpg)
![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host Device
a_h
b_h
a_d
b_d](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-24-320.jpg)
![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host Device
a_h
b_h
a_d
b_d](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-25-320.jpg)
![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host Device
a_h
b_h
a_d
b_d](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-26-320.jpg)
![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host Device
a_h
b_h
a_d
b_d](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-27-320.jpg)
![int main(void)
{
float *a_h, *b_h; // host data
float *a_d, *b_d; // device data
int N = 14, nBytes, i ;
nBytes = N*sizeof(float);
a_h = (float *)malloc(nBytes);
b_h = (float *)malloc(nBytes);
cudaMalloc((void **) &a_d, nBytes);
cudaMalloc((void **) &b_d, nBytes);
for (i=0, i<N; i++) a_h[i] = 100.f + i;
cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost);
for (i=0; i< N; i++) assert( a_h[i] == b_h[i] );
free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d);
return 0;
}
© NVIDIA Corporation 2009
Data Movement Example
Host Device](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-28-320.jpg)








![© NVIDIA Corporation 2009
Minimal Kernels
__global__ void kernel( int *a )
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
a[idx] = 7;
}
__global__ void kernel( int *a )
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
a[idx] = blockIdx.x;
}
__global__ void kernel( int *a )
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
a[idx] = threadIdx.x;
}
Output: 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7
Output: 0 0 0 0 0 1 1 1 1 1 2 2 2 2 2
Output: 0 1 2 3 4 0 1 2 3 4 0 1 2 3 4](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-38-320.jpg)
![© NVIDIA Corporation 2009
Increment Array Example
CPU program CUDA program
void inc_cpu(int *a, int N)
{
int idx;
for (idx = 0; idx<N; idx++)
a[idx] = a[idx] + 1;
}
void main()
{
…
inc_cpu(a, N);
…
}
__global__ void inc_gpu(int *a_d, int N)
{
int idx = blockIdx.x * blockDim.x
+ threadIdx.x;
if (idx < N)
a_d[idx] = a_d[idx] + 1;
}
void main()
{
…
dim3 dimBlock (blocksize);
dim3 dimGrid(ceil(N/(float)blocksize));
inc_gpu<<<dimGrid, dimBlock>>>(a_d, N);
…
}](https://image.slidesharecdn.com/cudaintroduction-140312043134-phpapp01/85/Cuda-introduction-39-320.jpg)





Cuda introduction
- 1. Cyril Zeller NVIDIA Developer Technology Tutorial CUDA
- 2. © NVIDIA Corporation 2008 Enter the GPU GPU = Graphics Processing Unit Chip in computer video cards, PlayStation 3, Xbox, etc. Two major vendors: NVIDIA and ATI (now AMD)
- 3. © NVIDIA Corporation 2008 Enter the GPU GPUs are massively multithreaded manycore chips NVIDIA Tesla products have up to 128 scalar processors Over 12,000 concurrent threads in flight Over 470 GFLOPS sustained performance Users across science & engineering disciplines are achieving 100x or better speedups on GPUs CS researchers can use GPUs as a research platform for manycore computing: arch, PL, numeric, …
- 4. © NVIDIA Corporation 2008 Enter CUDA CUDA is a scalable parallel programming model and a software environment for parallel computing Minimal extensions to familiar C/C++ environment Heterogeneous serial-parallel programming model NVIDIA’s TESLA GPU architecture accelerates CUDA Expose the computational horsepower of NVIDIA GPUs Enable general-purpose GPU computing CUDA also maps well to multicore CPUs!
- 5. © NVIDIA Corporation 2008 CUDA Programming Model
- 6. © NVIDIA Corporation 2008 Parallel Kernel KernelA (args); Parallel Kernel KernelB (args); Serial Code . . . . . . Serial Code Device Device Host Host Heterogeneous Programming CUDA = serial program with parallel kernels, all in C Serial C code executes in a host thread (i.e. CPU thread) Parallel kernel C code executes in many device threads across multiple processing elements (i.e. GPU threads)
- 7. © NVIDIA Corporation 2008 Kernel = Many Concurrent Threads One kernel is executed at a time on the device Many threads execute each kernel Each thread executes the same code… … on different data based on its threadID 0 1 2 3 4 5 6 7 … float x = input[threadID]; float y = func(x); output[threadID] = y; … threadID CUDA threads might be Physical threads As on NVIDIA GPUs GPU thread creation and context switching are essentially free Or virtual threads E.g. 1 CPU core might execute multiple CUDA threads
- 8. © NVIDIA Corporation 2008 Hierarchy of Concurrent Threads Threads are grouped into thread blocks Kernel = grid of thread blocks … float x = input[threadID]; float y = func(x); output[threadID] = y; … threadID Thread Block 0 … … float x = input[threadID]; float y = func(x); output[threadID] = y; … Thread Block 1 … float x = input[threadID]; float y = func(x); output[threadID] = y; … Thread Block N - 1 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 By definition, threads in the same block may synchronize with barriers scratch[threadID] = begin[threadID]; __syncthreads(); int left = scratch[threadID - 1]; Threads wait at the barrier until all threads in the same block reach the barrier
- 9. © NVIDIA Corporation 2008 Transparent Scalability Thread blocks cannot synchronize So they can run in any order, concurrently or sequentially This independence gives scalability: A kernel scales across any number of parallel cores 2-Core Device Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 Kernel grid Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 4-Core Device Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 Implicit barrier between dependent kernels vec_minus<<<nblocks, blksize>>>(a, b, c); vec_dot<<<nblocks, blksize>>>(c, c);
- 10. © NVIDIA Corporation 2008 Heterogeneous Memory Model Device 0 memory Device 1 memory Host memory cudaMemcpy()
- 11. Per-thread Per-block Per-device © NVIDIA Corporation 2009 Kernel Memory Access Thread Registers Local Memory Shared Memory Block ...Kernel 0 ...Kernel 1 Global Memory Time On-chip Off-chip, uncached • On-chip, small • Fast • Off-chip, large • Uncached • Persistent across kernel launches • Kernel I/O
- 12. Multiprocessor © NVIDIA Corporation 2009 Physical Memory Layout “Local” memory resides in device DRAM Use registers and shared memory to minimize local memory use Host can read and write global memory but not shared memory Host CPU ChipsetDRAM Device DRAM Local Memory Global Memory GPU Multiprocessor Multiprocessor Registers Shared Memory
- 13. © NVIDIA Corporation 2009 10-Series Architecture 240 thread processors execute kernel threads 30 multiprocessors, each contains 8 thread processors One double-precision unit Shared memory enables thread cooperation Thread Processors Multiprocessor Shared Memory Double
- 14. © NVIDIA Corporation 2009 Execution Model Software Hardware Threads are executed by thread processors Thread Thread Processor Thread Block Multiprocessor Thread blocks are executed on multiprocessors Thread blocks do not migrate Several concurrent thread blocks can reside on one multiprocessor - limited by multiprocessor resources (shared memory and register file) ... Grid Device A kernel is launched as a grid of thread blocks Only one kernel can execute on a device at one time
- 15. CUDA Programming Basics Part I - Software Stack and Memory Management
- 16. © NVIDIA Corporation 2009 Compiler Any source file containing language extensions, like “<<< >>>”, must be compiled with nvcc nvcc is a compiler driver Invokes all the necessary tools and compilers like cudacc, g++, cl, ... nvcc can output either: C code (CPU code) That must then be compiled with the rest of the application using another tool PTX or object code directly An executable requires linking to: Runtime library (cudart) Core library (cuda)
- 17. © NVIDIA Corporation 2009 Compiling NVCC CPU/GPU Source PTX to Target Compiler G80 … GPU Target code PTX Code Virtual Physical CPU Source
- 18. © NVIDIA Corporation 2009 GPU Memory Allocation / Release Host (CPU) manages device (GPU) memory cudaMalloc(void **pointer, size_t nbytes) cudaMemset(void *pointer, int value, size_t count) cudaFree(void *pointer) int n = 1024; int nbytes = 1024*sizeof(int); int *a_d = 0; cudaMalloc( (void**)&a_d, nbytes ); cudaMemset( a_d, 0, nbytes); cudaFree(a_d);
- 19. © NVIDIA Corporation 2009 Data Copies cudaMemcpy(void *dst, void *src, size_t nbytes, enum cudaMemcpyKind direction); direction specifies locations (host or device) of src and dst Blocks CPU thread: returns after the copy is complete Doesn’t start copying until previous CUDA calls complete enum cudaMemcpyKind cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
- 20. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host Device
- 21. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host a_h b_h
- 22. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host Device a_h b_h a_d b_d
- 23. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host Device a_h b_h a_d b_d
- 24. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host Device a_h b_h a_d b_d
- 25. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host Device a_h b_h a_d b_d
- 26. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host Device a_h b_h a_d b_d
- 27. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host Device a_h b_h a_d b_d
- 28. int main(void) { float *a_h, *b_h; // host data float *a_d, *b_d; // device data int N = 14, nBytes, i ; nBytes = N*sizeof(float); a_h = (float *)malloc(nBytes); b_h = (float *)malloc(nBytes); cudaMalloc((void **) &a_d, nBytes); cudaMalloc((void **) &b_d, nBytes); for (i=0, i<N; i++) a_h[i] = 100.f + i; cudaMemcpy(a_d, a_h, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(b_d, a_d, nBytes, cudaMemcpyDeviceToDevice); cudaMemcpy(b_h, b_d, nBytes, cudaMemcpyDeviceToHost); for (i=0; i< N; i++) assert( a_h[i] == b_h[i] ); free(a_h); free(b_h); cudaFree(a_d); cudaFree(b_d); return 0; } © NVIDIA Corporation 2009 Data Movement Example Host Device
- 29. CUDA Programming Basics Part II - Kernels
- 30. © NVIDIA Corporation 2009 Thread Hierarchy Threads launched for a parallel section are partitioned into thread blocks Grid = all blocks for a given launch Thread block is a group of threads that can: Synchronize their execution Communicate via shared memory
- 31. © NVIDIA Corporation 2009 Executing Code on the GPU Kernels are C functions with some restrictions Cannot access host memory Must have void return type No variable number of arguments (“varargs”) Not recursive No static variables Function arguments automatically copied from host to device
- 32. © NVIDIA Corporation 2009 Function Qualifiers Kernels designated by function qualifier: __global__ Function called from host and executed on device Must return void Other CUDA function qualifiers __device__ Function called from device and run on device Cannot be called from host code __host__ Function called from host and executed on host (default) __host__ and __device__ qualifiers can be combined to generate both CPU and GPU code
- 33. © NVIDIA Corporation 2009 Launching Kernels Modified C function call syntax: kernel<<<dim3 dG, dim3 dB>>>(…) Execution Configuration (“<<< >>>”) dG - dimension and size of grid in blocks Two-dimensional: x and y Blocks launched in the grid: dG.x*dG.y dB - dimension and size of blocks in threads: Three-dimensional: x, y, and z Threads per block: dB.x*dB.y*dB.z Unspecified dim3 fields initialize to 1
- 34. © NVIDIA Corporation 2008 28 More on Thread and Block IDs Threads and blocks have IDs So each thread can decide what data to work on Block ID: 1D or 2D Thread ID: 1D, 2D, or 3D Simplifies memory addressing when processing multidimensional data Image processing Solving PDEs on volumes Host Kernel 1 Kernel 2 Device Grid 1 Block (0, 0) Block (1, 0) Block (2, 0) Block (0, 1) Block (1, 1) Block (2, 1) Grid 2 Block (1, 1) Thread (0, 1) Thread (1, 1) Thread (2, 1) Thread (3, 1) Thread (4, 1) Thread (0, 2) Thread (1, 2) Thread (2, 2) Thread (3, 2) Thread (4, 2) Thread (0, 0) Thread (1, 0) Thread (2, 0) Thread (3, 0) Thread (4, 0)
- 35. © NVIDIA Corporation 2009 Execution Configuration Examples kernel<<<32,512>>>(...); dim3 grid, block; grid.x = 2; grid.y = 4; block.x = 8; block.y = 16; kernel<<<grid, block>>>(...); dim3 grid(2, 4), block(8,16); kernel<<<grid, block>>>(...); Equivalent assignment using constructor functions
- 36. © NVIDIA Corporation 2009 CUDA Built-in Device Variables All __global__ and __device__ functions have access to these automatically defined variables dim3 gridDim; Dimensions of the grid in blocks (at most 2D) dim3 blockDim; Dimensions of the block in threads dim3 blockIdx; Block index within the grid dim3 threadIdx; Thread index within the block
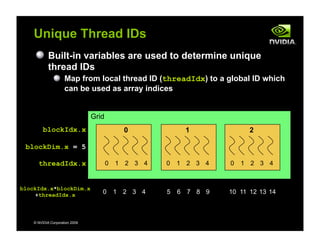
- 37. © NVIDIA Corporation 2009 Built-in variables are used to determine unique thread IDs Map from local thread ID (threadIdx) to a global ID which can be used as array indices Unique Thread IDs 0 0 1 2 3 4 1 0 1 2 3 4 2 0 1 2 3 4 blockIdx.x blockDim.x = 5 threadIdx.x blockIdx.x*blockDim.x +threadIdx.x 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Grid
- 38. © NVIDIA Corporation 2009 Minimal Kernels __global__ void kernel( int *a ) { int idx = blockIdx.x*blockDim.x + threadIdx.x; a[idx] = 7; } __global__ void kernel( int *a ) { int idx = blockIdx.x*blockDim.x + threadIdx.x; a[idx] = blockIdx.x; } __global__ void kernel( int *a ) { int idx = blockIdx.x*blockDim.x + threadIdx.x; a[idx] = threadIdx.x; } Output: 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 Output: 0 0 0 0 0 1 1 1 1 1 2 2 2 2 2 Output: 0 1 2 3 4 0 1 2 3 4 0 1 2 3 4
- 39. © NVIDIA Corporation 2009 Increment Array Example CPU program CUDA program void inc_cpu(int *a, int N) { int idx; for (idx = 0; idx<N; idx++) a[idx] = a[idx] + 1; } void main() { … inc_cpu(a, N); … } __global__ void inc_gpu(int *a_d, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) a_d[idx] = a_d[idx] + 1; } void main() { … dim3 dimBlock (blocksize); dim3 dimGrid(ceil(N/(float)blocksize)); inc_gpu<<<dimGrid, dimBlock>>>(a_d, N); … }
- 40. © NVIDIA Corporation 2009 Host Synchronization All kernel launches are asynchronous control returns to CPU immediately kernel executes after all previous CUDA calls have completed cudaMemcpy() is synchronous control returns to CPU after copy completes copy starts after all previous CUDA calls have completed cudaThreadSynchronize() blocks until all previous CUDA calls complete
- 41. © NVIDIA Corporation 2009 Host Synchronization Example … // copy data from host to device cudaMemcpy(a_d, a_h, numBytes, cudaMemcpyHostToDevice); // execute the kernel inc_gpu<<<ceil(N/(float)blocksize), blocksize>>>(a_d, N); // run independent CPU code run_cpu_stuff(); // copy data from device back to host cudaMemcpy(a_h, a_d, numBytes, cudaMemcpyDeviceToHost); …
- 42. © NVIDIA Corporation 2009 Variable Qualifiers (GPU code) __device__ Stored in global memory (large, high latency, no cache) Allocated with cudaMalloc (__device__ qualifier implied) Accessible by all threads Lifetime: application __shared__ Stored in on-chip shared memory (very low latency) Specified by execution configuration or at compile time Accessible by all threads in the same thread block Lifetime: thread block Unqualified variables: Scalars and built-in vector types are stored in registers Arrays may be in registers or local memory
- 43. © NVIDIA Corporation 2009 GPU Thread Synchronization void __syncthreads(); Synchronizes all threads in a block Generates barrier synchronization instruction No thread can pass this barrier until all threads in the block reach it Used to avoid RAW / WAR / WAW hazards when accessing shared memory Allowed in conditional code only if the conditional is uniform across the entire thread block
- 44. © NVIDIA Corporation 2009 GPU Atomic Integer Operations Requires hardware with compute capability >= 1.1 G80 = Compute capability 1.0 G84/G86/G92 = Compute capability 1.1 GT200 = Compute capability 1.3 Atomic operations on integers in global memory: Associative operations on signed/unsigned ints add, sub, min, max, ... and, or, xor Increment, decrement Exchange, compare and swap Atomic operations on integers in shared memory Requires compute capability >= 1.2