CUDA-Aware MPI
1 like552 views

Документ описывает интеграцию MPI (Message Passing Interface) с CUDA для оптимизации параллельных вычислений на кластерах. Он объясняет архитектуру и функции MPI, а также различные схемы передачи данных между узлами, включая преимущества использования CUDA-aware MPI. Приведены примеры программ и предпочтительные методы передачи данных для повышения эффективности работы с большими массивами данных на GPU.





























CUDA-Aware MPI
- 2. ▸ Разделы: ▸ Обзор MPI ▸ Связка MPI & CUDA ▸ Пример программы 2
- 4. ЧТО ТАКОЕ MPI? ▸Интерфейс передачи сообщений ▸Протокол на уровне софта ▸Кросспалтформенность ▸Принцип компьютерных вычислений SIMD 4
- 5. MPI VS CUDA ▸Принцип работы узлов ▸Структура памяти 5
- 7. ▸MPI_Init: инициализирует окружение MPI ▸MPI_Comm_size: возвращает число узлов ▸MPI_Comm_rank: возвращает номер текущего узла ▸MPI_Send: отправляет сообщение ▸MPI_Recv: получает сообщение ▸MPI_Finalize: очистка памяти СТАНДАРТНЫЕ ФУНКЦИИ 7
- 8. 8 ПРИМЕР ПРОГРАММЫ ▸ 1 ▸ 2 ▸ 3 ▸ 4 ▸ 5 ▸ 6 ▸ 7 ▸ 8 ▸ 9 ▸ 10 ▸ 11 ▸ 12 ▸ 13 ▸ 14 ▸ 15 ▸ 16 ▸ 17 ▸ 18 ▸ 19 ▸ 20 ▸ 21 ▸ 22
- 9. КОМПИЛЯЦИЯ И ЗАПУСК ▸Компиляция ▸Запуск четырех узлов с параметрами <args> 9
- 10. ВЗАИМОДЕЙСТВИЕ MPI & CUDA ▸Две возможные схемы взаимодействия MPI & CUDA: 10 ▸Использовать ядра мультипроцессоров в GPU в качестве узлов MPI ▸Узлами являются только CPU или процессы, которые работают с GPU
- 11. РАССМОТРИМ КЛАСТЕР ▸3 узла ▸Каждый узел имеет CPU и GPU 11
- 12. СПОСОБЫ ПЕРЕДАЧИ ДАННЫХ ▸1) Device1 -> Host1 -> Host2 -> Device2 (MPI+CUDA) ▸2) Device1-> Device2 (CUDA-Aware MPI) 12
- 13. ▸Единое пространство виртуальных адресов, начиная с CUDA 4.0 на устройствах с Compute Capability 2.0 КАК ЭТОГО ДОБИТЬСЯ? 13
- 14. CUDA-AWARE MPI VS MPI+CUDA 14 ▸Упрощение исходного кода ▸Оптимизация передачи данных внутри сети
- 15. ПРИНЦИП ПЕРЕДАЧИ ДАННЫХ HOST -> DEVICE ▸Pageable memory ▸Pinned memory ▸Device memory 15
- 16. ВВЕДЕМ ОБОЗНАЧЕНИЯ ▸ Память на GPU ▸ Страничная память ▸ Физическая память ▸ Физическая память ▸ DMA transfer over the PCI ▸ Обычное копирование ▸ RDMA network transfer 16
- 17. ПРИНЦИП ПЕРЕДАЧИ ДАННЫХ МЕЖДУ УЗЛАМИ (СХЕМА) 17 ▸ Организация передачи сообщений в сети
- 18. ПРИНЦИП ПЕРЕДАЧИ ДАННЫХ МЕЖДУ УЗЛАМИ (ВЕКТОРИЗАЦИЯ) 18 ▸Лишнее копирование в страничную память на хосте
- 19. ▸Реализация CUDA-Aware MPI исключает лишнее копирование 19ПРИНЦИП ПЕРЕДАЧИ ДАННЫХ МЕЖДУ УЗЛАМИ (CUDA-AWARE MPI)
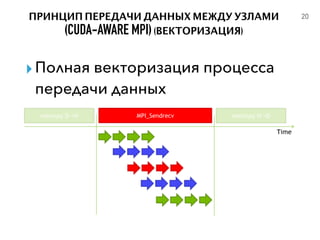
- 20. 20 ▸Полная векторизация процесса передачи данных ПРИНЦИП ПЕРЕДАЧИ ДАННЫХ МЕЖДУ УЗЛАМИ (CUDA-AWARE MPI)(ВЕКТОРИЗАЦИЯ)
- 21. GPUDIRECT SHARED ACCESS 21 ▸Исключение всех копирований на хосте
- 22. GPUDIRECT P2P & RDMA 22
- 23. 23 ▸Самый быстрый способ передачи данных ▸Zero-copy — CPU не участвует в передаче данных GPUDIRECT P2P & RDMA
- 24. СРАВНЕНИЕ РАБОТЫ ПРИ РАЗНЫХ СХЕМАХ ПЕРЕДАЧИ ДАННЫХ 24 ▸Вывод: лучше использовать CUDA- Aware MPI, нежели просто MPI+CUDA
- 25. ПРИМЕР ▸Дан массив данных из N элементов ▸Необходимо посчитать аппроксимацию производной M-го порядка в каждой точке ▸Массив очень большой, в одну GPU не влезает 25
- 26. АРХИТЕКТУРА ПРОГРАММЫ ▸Разбиваем массив на несколько участков (сколько у нас есть GPU) ▸Вычисляем на GPU свой участок ▸Передаем нужные данные между GPU с помощью CUDA-Aware MPI
- 27. ДИАГРАММА 27
- 28. 28 MAIN
- 29. DATA_SERVER 29