Data Agility—A Journey to Advanced Analytics and Machine Learning at Scale
5 likes804 views

Hari Subramanian presented on Uber's journey to enable data agility and advanced analytics at scale. He discussed Uber's large and growing data platform that processes millions of daily trips and terabytes of data. He then described Uber's Data Science Workbench, which aims to democratize data science by providing self-service access to infrastructure, tools, and data to support various users from data scientists to business analysts. Finally, he presented a case study on COTA, a deep learning model for customer support ticketing that was developed and deployed using Uber's data platform and workflow.











































Data Agility—A Journey to Advanced Analytics and Machine Learning at Scale
- 1. Data Agility - A Journey to Advanced Analytics and Machine Learning at Scale Spark Summit, April 2019 Hari Subramanian, Engineering Manager
- 2. About me Engineering Manager (also Engineer, Product Manager, Entrepreneur) Previously: Amazon Web Services, VMware, Startups Until Recently: Led Big Data Analytics & Data Science Workbench at Uber Currently: Customer Obsession Engineering at Uber
- 3. 00 The Uber Scale 01 Uber’s Data Platform 02 Data Science Workbench 03 DS & ML - Uber Toolset 04 Customer Obsession - a case study 05 Lessons learned 06 Wrap-up Agenda
- 4. NYC Uber’s mission is to ignite opportunity by setting the world in motion. Impacts Millions of Riders Global footprint Livelihood for Millions of drivers
- 5. Data informs every decision in the company
- 6. Daily Uber trips powered by ML Millions Messages processed by Kafka 2T Queries across Hive, Vertica and Presto 1M Data ingested into HDFS 150TB How Big is our Big Data?
- 7. Overview of Uber’s Data Platform DATA SOURCES RAW DATA MODELED TABLES MINING BUSINESS INSIGHTS CONSUMING BUSINESS INSIGHTS EXPERIMENTATION DATA SCIENCE MACHINE LEARNING CUSTOM DATA SETS Dashboarding Alerting Monitoring Data Exploration Query Engines Knowledge Bases ETL Frameworks Data Integrity Storage Infrastructure
- 8. What is DSW?
- 9. Rapid growth growing pains Accessing data & services was complicated Getting started was hard Collaboration was difficult
- 10. Many stakeholders, many needs Cost and compliance requirements Varied users Different infrastructure needs Single window access
- 11. Democratize data science by enabling access to reliable infrastructure and advanced tooling in a community-driven learning environment Data Science Workbench
- 12. Fully hosted 1-click Jupyter Notebook & RStudio IDEGetting Started Data Access Shared Standards Collaboration Scalability Available Features All internal data sources / Multi-DC / Secure / Log/Audit capabilities Pre-baked Environments Sharing options on notebooks; 1-click Shiny dashboard publication Various session sizes, types (CPU, GPU)/access to compute engines Documentation Support Our world today
- 13. Key features ● Data exploration ● Data preparation ● Ad-hoc analyses ● Model exploration Interactive workspaces ● Visualizing rich insights derived from complex analytics ● Displaying business metrics Advanced dashboards ● Automating complex processes ● Small model training ● Scheduling data pulls Business process automations
- 15. What problem does DSW solve?
- 17. Advanced data science & complex analytics Data Scientists Ops Analysts Contractors
- 18. Business process automation S&P AnalystsOps Managers Contractors
- 19. Exploratory ML, model-training, & production Data Scientists ML Researchers Support NLP model for support tickets Safety Trip classification Uber Eats Restaurant recommendations Risk Driver account check Referral risk scoring Operations Lifetime value (LTV) modelEngineers
- 20. HDFS (Hadoop Data Lake) YARN Mesos Peloton Piper | Metron | WatchTower | Marmaray | Kirby | Databook Security Summary | Query | Dash | Map | Chart Builder Hive as a Service Spark as a Service DSW Query Gateway Services Observability AllActiveandHiveSync EfficiencyandCapacity Presto XP | Mentana Michelangelo Experimentation BI Tools DS Platform ML Platform Data processing Platform Unique fit in a mature Data Platform
- 21. DS & ML - Uber Toolkit Ingestion & Dispersal (Hoover, Marmaray - uses Spark, Hive) Data preparation (Databook, QB/QR - uses Spark, Presto, Hive) Data Analytics (BI tools, DSW - numPy, scikit-learn, pandas) ML and DL (Spark MLLib, xgboost, TF, keras, pytorch, Horovod) Model serving (PyML, Michelangelo, Peloton) Workflows, Exploration (AirFlow/Piper, Data Science Workbench)
- 22. Case study COTA - Customer Obsession Ticketing Assistant A Deep Learning Model developed and deployed using Uber’s Data Platform
- 23. What is the challenge? As Uber grows, so does our volume of support tickets Millions of tickets from riders / drivers / eaters per week Thousands of different types of issues users may encounter This slide was adapted from a talk by Huaixiu Zheng, Uber
- 24. User CSRContact Ticket Response Select Flow Node Write Message Select Contact Type Lookup info & Policies Select Action Write response using a Reply Template Bliss - Uber’s Customer Support Platform This slide was adapted from a talk by Huaixiu Zheng, Uber
- 25. The Problem Resolving a ticket is not easy (or cheap) 1000+ types in a hierarchy depth: 3~6 10+ actions (adjust fare, add appeasement, …) 1000+ reply templates This slide was adapted from a talk by Huaixiu Zheng, Uber
- 26. Portuguese Spanish English ML Layer User Info Trip Info Ticket Text COTA: The Solution A collaborative effort from Uber Risk, CO Eng, and Data Platform teams TYPE REPLY Ticket Metadata COTA v2.1 (wordCNN) ACTION Recommend + Default + Auto-resolution ROUTING Risk Features Fraud DS embedment CO Eng routing engagement
- 27. 2. prototype 3. productionize 1. define 4. measure Launch and Iterate Typical Machine Learning Workflow
- 28. 2. prototype GET DATA DATA PREPARATION TRAIN MODELS EVALUATE MODELS Validation Computational cost Interpretability SQL, Spark Data cleansing and pre-processing, R / Python CPU or GPU Exploration and prototyping 3. productionize 1. define 4. measure
- 29. ● Iterate on model quickly with tweaks to parameters and configuration ● Flexible development - custom code + leverage existing modules for data prep, ETLs, train, predict, and visualize ● Jupyter notebook running on a GPU or CPU session ● Pre-packaged Spark, tensorflow, keras, pandas, numpy, scipy etc. ● Interactive Spark exec through Uber’s Spark as a Service - Drogon ● API integrations to production ML platform - Michelangelo ● API integrations to data workflow management - Piper ● Develop and test locally, deploy in the cluster when ready Vision: Build in DSW, run in prod platforms Easy ML experimentation, quick production
- 31. Architecture This slide was adapted from a talk by Huaixiu Zheng, Uber
- 32. Training: Deep Learning Spark Pipeline Spark + Tensorflow This slide was adapted from a talk by Huaixiu Zheng, Uber
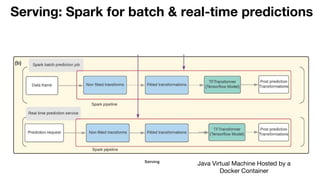
- 33. Serving: Spark for batch & real-time predictions Java Virtual Machine Hosted by a Docker Container
- 34. Model Lifecycle Managed in DSW
- 35. Model Lifecycle This slide was adapted from a talk by Huaixiu Zheng, Uber
- 36. Step 1: Data ETL ● Ingredients ○ Query to do ETL ○ Scheduled notebook as a Piper job to retrain data ETL daily This slide was adapted from a talk by Huaixiu Zheng, Uber
- 37. Step 2: Spark Transformations ● Ingredients ○ Setup spark job in Drogon via Michelangelo ○ Scheduled job to trigger the job at a particular retraining frequency This slide was adapted from a talk by Huaixiu Zheng, Uber
- 38. Step 3: Data Transfer ● Ingredients ○ Upstream dependency on Spark job ○ Scheduled job to trigger data copy to a GPU only cluster using a cross datacenter replication service This slide was adapted from a talk by Huaixiu Zheng, Uber
- 39. Step 4: Deep Learning Training ● Ingredients ○ Upstream dependency on data transfer ○ Prepare a docker image containing the training code ○ A scheduled job to trigger the DL training in a GPU cluster This slide was adapted from a talk by Huaixiu Zheng, Uber
- 40. Step 5: Model Merging ● Ingredients ○ This happens within the DL training job. ○ Right after DL training is done, Spark and DL models are merged and uploaded to a model store. This slide was adapted from a talk by Huaixiu Zheng, Uber
- 41. Step 6: Model Deployment ● Ingredients ○ Upstream dependency on DL training and Model Merging ○ A scheduled job from notebook triggerring Model Deployment This slide was adapted from a talk by Huaixiu Zheng, Uber
- 42. Leverage Monitoring and Ops tools built for production scenarios This slide was adapted from a talk by Huaixiu Zheng, Uber
- 43. Lessons learned Build for the experts, design for the less technical people Create communities with both data scientists and non data scientists Don’t stop at building what’s known, empower people to look for the unknown
- 44. Thank you!