Data analysis with Pandas and Spark
3 likes773 views

This document discusses using Jupyter notebooks, Pandas, and Spark for analytics pipelines on both small and large datasets. It summarizes the challenges of working with different data volumes and timeframes. For small mobile transaction data, notebooks with Pandas and R are used, while larger retail data is analyzed with Spark ML and scikit-learn in notebooks running in Docker containers. Future work includes applying Spark to additional domains and building forecasting and streaming capabilities.




























Data analysis with Pandas and Spark
- 1. Analytics pipelines with Jupyter and Spark
- 2. Who we are ● NETOPIA ● mobilPay ● mobilPay Wallet ● web2sms ● btko.in ● kartela.ro ● mobilender.mx
- 3. Challenges
- 4. Three dimensional problem ● Time: Past events or crystall ball? ● Profile: Who is looking at the data? ● Quantity: How much data is there to look at?
- 5. Profile ● Data Scientist ● Data Engineer
- 6. Quantity ● Hundreds of MB to a few GB ● Up to million events/records vs. ● GB to TB to PB ● Hundreds of millions to billions and beyond events/records
- 7. Also ● Computing vs. Storage ● Vertical vs. Horizontal scalability ● Distributed/ML libraries ● Dependency hell
- 8. Time NOW Past Future Analytics Forecasting (a.k.a. Prediction)
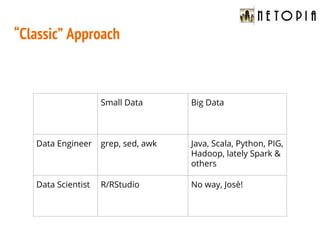
- 9. “Classic” Approach Small Data Big Data Data Engineer grep, sed, awk Java, Scala, Python, PIG, Hadoop, lately Spark & others Data Scientist R/RStudio No way, Josè!
- 10. New Approach Small Data Big Data Data Engineer Notebook Technologies: Jupyter (most used), zeppelin, but also less known ones (Rodeo, Beaker) Data Scientist
- 11. Data analysis with Jupyter, Pandas and Spark
- 12. Outline About the data: ● Set of mobile transactions ● Set (separate) of retail transactions About the tools: Jupyter, Pandas and Spark Our experience Future work
- 13. Mobile transactions Retail data Elements of analysis Transactions Transactions, Products, Stock data We know Transaction value, User identifier, Merchant Transaction value, Sold products, Merchant We don’t know What product was bought Who the user is Size Hundreds of thousands of entries Hundreds of millions of entries Status Building prediction models Gathering data Datasets
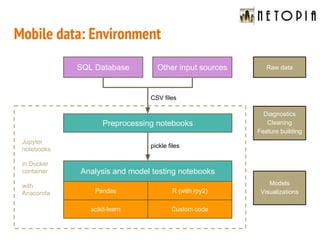
- 15. SQL Database Mobile data: Environment Preprocessing notebooks Analysis and model testing notebooks Pandas R (with rpy2) scikit-learn Custom code CSV files pickle files Other input sources Jupyter notebooks in Docker container with Anaconda Diagnostics Cleaning Feature building Raw data Models Visualizations
- 16. Docker image … with Anaconda ● Anaconda: package manager for data science ● Using docker-compose for setting up container parameters ● Many available images ● Our base image: ○ pyspark from Jupyter Docker Stacks ○ Extended with required libraries ● Libraries are added or updated with docker build: ○ Self-contained ○ Easy versioning
- 17. Jupyter Notebook (1) Web application for creating documents with live code, explanations and visualizations ● Initially, part of IPython ● Narrative with live code ● Protocol for interactive exploration ○ Run blocks of code ○ Embedded JS ● Executable documents ○ Code ○ HTML and Markdown ○ Metadata ● Kernels for multiple languages ○ Python ○ R ○ Scala ○ Bash ● Internal format: JSON
- 18. Jupyter Notebook (2) Web application for creating documents with live code, explanations and visualizations ● Plugins and widgets ● Easy to share (formats: Notebook, PDF, HTML, …) ● Large ecosystem ○ Jupyter Lab / Jupyter Hub ○ GitHub visualizations ○ Blog integration ○ Education: teaching, evaluation ○ Microsoft, Google, Bloomberg, IBM, O'Reilly ○ Executable books ● Versioning is complicated
- 19. Pandas ● DataFrame objects ○ Tabular data structures ○ Each column has one data type ● Based on numpy (fast) ● Processing is (mostly) done in memory ● Data manipulation: ○ Hierarchical indexing ○ Reshaping, pivoting, grouping ○ String operations ○ Time series operations ● Reading / writing from / to many formats (CSV, JSON, HDF5, …) ● Visualization: matplotlib, Seaborn, Bokeh, … Python library for data manipulation and analysis
- 20. rpy2 Interface between Python and R ● Translates DataFrames between Python and R ● Python in Jupyter: use %%R ● Direct access to R objects (rpy2.robjects)
- 21. Jupyter, Pandas and R R with Rpy2 Python HTML and Markdown Notebook
- 22. Mobile data: User retention Active users: ● Classic: 1+ transactions in a given period ● Rolling: 1+ transactions in a given or subsequent period Plots: ● X: period (day, week, month) ● Y (cohort): period or another type of segment ● By transaction criteria (merchant, product, etc.) Results: ● Response to campaigns ● Activity recurrence Cohorts Periods
- 23. Mobile data: Correlations Features: ● How similar are two features? Merchants: ● Which merchants have common users? Products: ● Which products are sold together?
- 24. Mobile data: Clusters ● Group users by behavior ● Identify outliers ● Future: automatic cluster labeling
- 26. Retail data: Our experience First try: Out-of-core processing with HDF5 ● Data does did not fit in memory ● HDF5: format for large data ● Pandas + HDF5, Blaze, Dask, Odo ● Easy to use functions ● Library incompatibilities ● Slow queries, use indexes ● Occasional runtime errors
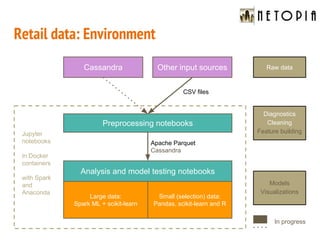
- 27. Cassandra Retail data: Environment Preprocessing notebooks Analysis and model testing notebooks Large data: Spark ML + scikit-learn Small (selection) data: Pandas, scikit-learn and R CSV files Apache Parquet Cassandra Other input sources Jupyter notebooks in Docker containers with Spark and Anaconda Diagnostics Cleaning Feature building Raw data Models Visualizations In progress
- 28. Spark Engine for big data processing ● DataFrames ○ Built on top of RDDs ○ Similar to Pandas and R ○ SQL queries ○ Automatic query optimization through query plan ○ String , date-time and statistics functions ○ Group by, filters ● Jupyter integration: work in progress https://cwiki.apache.org/confluence/display/SPARK/PySpark+Internals
- 29. Spark Machine Learning MLlib and ML ● MLlib ○ Uses RDDs ○ Summaries, correlations, sampling ○ SVMs, logistic regression, decision trees, ensembles and Naive Bayes ○ Clustering ○ Feature transformation ● ML ○ Works with DataFrames ○ Many wrappers for MLlib ○ Pipelines: ■ Transformers, Estimators, Parameters ■ labelCol, featuresCol, predictionCol, ... ○ R formulas (y ~ x1 + x2)
- 30. Retail data: Our experience Current: Spark + Docker ● No issues at current size (several GBs) ● Docker Compose for creating master, workers and Jupyter container (driver) ● ML libraries are easy to work with ● Incomplete Python API for ML (e.g., summaries) ● Documentation needs improvement ● Model diagnostics ○ Some metrics are available ○ Supplement with scikit-learn (example: build ROC curves) ● scikit-learn or R on top of Spark ○ Parallelize parameter search (e.g., grid search) ○ Spark sklearn (github.com/databricks/spark-sklearn): Grid Search
- 31. Future work Mobile wallet transactions: ● Data fits in memory ● Use Spark for distributing workload ERP transactions: ● Some data fits in memory, after processing ● Build a web app for data exploration ● Forecast ○ Sales ○ Inventory requirements ● Try Spark Streaming http://xkcd.com/1425/