






































![44
SYNTAX for Window Functions
over_clause:
{OVER (window_spec) | OVER window_name}
window_spec:
[window_name] [partition_clause] [order_clause]
[frame_clause]
partition_clause:
PARTITION BY expr [, expr] ...
order_clause:
ORDER BY expr [ASC|DESC] [, expr [ASC|DESC]]
...](https://image.slidesharecdn.com/datalovemysqlwindowfunctions-210416154939/85/Data-Love-Conference-Window-Functions-for-Database-Analytics-44-320.jpg)








Data Love Conference - Window Functions for Database Analytics
- 1. Window Functions for Database Analytics Dave Stokes MySQL Community Manager MySQL Community Team
- 2. Dave Stokes MySQL Community Team Oracle Corporation @Stoker https://elephantdolphin.blogspot.com/ [email protected] Slides are available at Slideshare.net/davestokes 2 Copyright © 2020, Oracle and/or its affiliates | Confidential: Internal/Restricted/Highly Restricted
- 3. 3 This is a subject that can take a great deal of time to master Using MySQL 8.0 for demos ● Will work with other similar databases Analytics and statistics are also complex ● Many good books, videos, and courses ● Learn to double check assumptions! You ● Take small steps ● Progress takes practice ● Years of potential learning! This is an introduction
- 4. 4 Analytics Analytics is the systematic computational analysis of data or statistics. It is used for the discovery, interpretation, and communication of meaningful patterns in data. It also entails applying data patterns towards effective decision making. It can be valuable in areas rich with recorded information; analytics relies on the simultaneous application of statistics, computer programming and operations research to quantify performance. -- https://en.wikipedia.org/wiki/Analytics
- 5. Aggregate Functions - what we used before Window Functions and still use AVG() Return the average value of the argument MAX() Return the maximum value MIN() Return the minimum value STD() Return the population standard deviation STDDEV() Return the population standard deviation STDDEV_POP() Return the population standard deviation STDDEV_SAMP() Return the sample standard deviation SUM() Return the sum VAR_POP() Return the population standard variance VAR_SAMP() Return the sample variance VARIANCE() Return the population standard variance 5 Aggregate functions operate on sets of values. They are often used with a GROUP BY clause to group values into subsets. Returns a single value for multiple rows
- 6. Window Functions CUME_DIST() Cumulative distribution value DENSE_RANK() Rank of current row within its partition, without gaps FIRST_VALUE() Value of argument from first row of window frame LAG() Value of argument from row lagging current row within partition LAST_VALUE() Value of argument from last row of window frame LEAD() Value of argument from row leading current row within partition NTH_VALUE() Value of argument from N-th row of window frame NTILE() Bucket number of current row within its partition. PERCENT_RANK() Percentage rank value RANK() Rank of current row within its partition, with gaps ROW_NUMBER() Number of current row within its partition 6 Uses values from one or multiple rows to return a value for each row
- 7. create table w1 ( a serial, b int unsigned, c int unsigned, d int unsigned); insert into w1(b,c,d) values (10,100,1000), (20,200,2000), (30,300,3000); Sample data without window function 7 select * from w1; +---+----+-----+------+ | a | b | c | d | +---+----+-----+------+ | 1 | 10 | 100 | 1000 | | 2 | 20 | 200 | 2000 | | 3 | 30 | 300 | 3000 | +---+----+-----+------+
- 8. select a,b,c,d, sum(a+b) as 'a&b' from w1; +---+----+-----+------+-----+ | a | b | c | d | a&b | +---+----+-----+------+-----+ | 1 | 10 | 100 | 1000 | 66 | +---+----+-----+------+-----+ Try to add rows a & b → opps! 8 a&b = 1 + 2 + 3 + 10 + 20 + 30 (the sum of the a and b columns) probably thought a&b = 11! Not clear of original intention
- 9. select a,b,c,d, sum(a+b) as 'a&b' from w1 group by a; +---+----+-----+------+-----+ | a | b | c | d | a&b | +---+----+-----+------+-----+ | 1 | 10 | 100 | 1000 | 11 | | 2 | 20 | 200 | 2000 | 22 | | 3 | 30 | 300 | 3000 | 33 | +---+----+-----+------+-----+ GROUP BY -- work by row 9
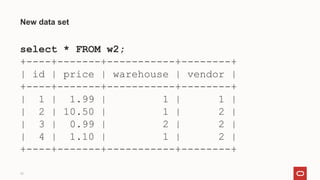
- 10. select * FROM w2; +----+-------+-----------+--------+ | id | price | warehouse | vendor | +----+-------+-----------+--------+ | 1 | 1.99 | 1 | 1 | | 2 | 10.50 | 1 | 2 | | 3 | 0.99 | 2 | 2 | | 4 | 1.10 | 1 | 2 | +----+-------+-----------+--------+ New data set 10
- 11. SELECT warehouse, SUM(price) from w2 group by warehouse with rollup; +-----------+------------+ | warehouse | SUM(price) | +-----------+------------+ | 1 | 13.59 | | 2 | 0.99 | | NULL | 14.58 | +-----------+------------+ WITH ROLLUP 11 We can group like items together and even ‘roll up’ values for totals. The NULL under the warehouse column is the ROLLUP or total of the sum(price) -- And not easily understood
- 12. select vendor, sum(price) from w2 group by vendor with rollup; +--------+------------+ | vendor | sum(price) | +--------+------------+ | 1 | 1.99 | | 2 | 12.59 | | NULL | 14.58 | +--------+------------+ USING different columns 12 NULL = ‘we do not have a value but do not want to use zero as the value is not zero and that may confuse come folks’ NULL is still confusing to many
- 13. 13 Windowing Functions are difficult – you need to practice with them to build understanding and competence. Do not panic if you struggle at first – they are a learned skilled.
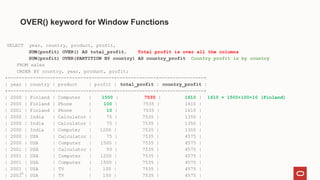
- 14. SELECT year, country, product, profit, SUM(profit) OVER() AS total_profit, Total profit is over all the columns SUM(profit) OVER(PARTITION BY country) AS country_profit Country profit is by country FROM sales ORDER BY country, year, product, profit; +------+---------+------------+--------+--------------+----------------+ | year | country | product | profit | total_profit | country_profit | +------+---------+------------+--------+--------------+----------------+ | 2000 | Finland | Computer | 1500 | 7535 | 1610 | 1610 = 1500+100+10 (Finland) | 2000 | Finland | Phone | 100 | 7535 | 1610 | | 2001 | Finland | Phone | 10 | 7535 | 1610 | | 2000 | India | Calculator | 75 | 7535 | 1350 | | 2000 | India | Calculator | 75 | 7535 | 1350 | | 2000 | India | Computer | 1200 | 7535 | 1350 | | 2000 | USA | Calculator | 75 | 7535 | 4575 | | 2000 | USA | Computer | 1500 | 7535 | 4575 | | 2001 | USA | Calculator | 50 | 7535 | 4575 | | 2001 | USA | Computer | 1200 | 7535 | 4575 | | 2001 | USA | Computer | 1500 | 7535 | 4575 | | 2001 | USA | TV | 100 | 7535 | 4575 | | 2001 | USA | TV | 150 | 7535 | 4575 | OVER() keyword for Window Functions 14
- 15. 15 Some explenations SELECT year, country, product, profit, SUM(profit) OVER() AS total_profit, SUM(profit) OVER(PARTITION BY country) AS country_profit FROM sales ORDER BY country, year, product, profit; The first OVER() clause is empty which treats the entire set of rows as a partition (global). The second OVER() clause partitions rows by country, producing a sum per partition (per country). The function produces this sum for each partition row (country). You are defining partitions for your data!!!
- 16. 16 RANK versus DENSE Rank SELECT x, row_number() over (order by x) AS 'Row Nbr', rank() over (order by x) AS 'Rank', DENSE_RANK() over (order by x) as 'Dense Rank' from w4; +---+---------+------+------------+ | x | Row Nbr | Rank | Dense Rank | +---+---------+------+------------+ | 0 | 1 | 1 | 1 | | 0 | 2 | 1 | 1 | | 2 | 3 | 3 | 2 | | 3 | 4 | 4 | 3 | | 3 | 5 | 4 | 3 | | 4 | 6 | 6 | 4 | +---+---------+------+------------+ +---+ | x | +---+ | 0 | | 0 | | 2 | | 3 | | 3 | | 4 | +---+
- 17. 17 RANK versus DENSE Rank with a named window SELECT x, ROW_NUMBER() over w AS 'Row Nbr', RANK() over w AS 'Rank', DENSE_RANK() over w as 'Dense Rank' from w4 WINDOW w as (order by x); +---+---------+------+------------+ | x | Row Nbr | Rank | Dense Rank | +---+---------+------+------------+ | 0 | 1 | 1 | 1 | | 0 | 2 | 1 | 1 | | 2 | 3 | 3 | 2 | | 3 | 4 | 4 | 3 | | 3 | 5 | 4 | 3 | | 4 | 6 | 6 | 4 | +---+---------+------+------------+ +---+ | x | +---+ | 0 | | 0 | | 2 | | 3 | | 3 | | 4 | +---+
- 18. 18 You can add modifiers to window definitions SELECT DISTINCT year, country, FIRST_VALUE(year) OVER (w ORDER BY year ASC) AS first, FIRST_VALUE(year) OVER (w ORDER BY year DESC) AS last FROM sales WINDOW w AS (PARTITION BY country);
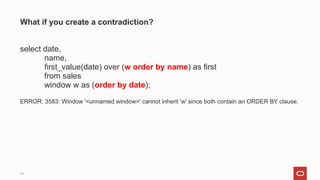
- 19. 19 What if you create a contradiction? select date, name, first_value(date) over (w order by name) as first from sales window w as (order by date); ERROR: 3583: Window '<unnamed window>' cannot inherit 'w' since both contain an ORDER BY clause.
- 20. 20 Another data set create table x (x serial); insert into x (x) values (null),(null),(null),(null),(null),(null),(null),(null),(null),(null); select x from x; +----+ | x | +----+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | | 8 | | 9 | | 10 | +----+
- 21. 21 OVER() = ALL ROWS select x, count(x) OVER(), sum(x) OVER() from x; +----+-----------------+---------------+ | x | count(x) OVER() | sum(x) OVER() | +----+-----------------+---------------+ | 1 | 10 | 55 | | 2 | 10 | 55 | | 3 | 10 | 55 | | 4 | 10 | 55 | | 5 | 10 | 55 | | 6 | 10 | 55 | | 7 | 10 | 55 | | 8 | 10 | 55 | | 9 | 10 | 55 | | 10 | 10 | 55 | +----+-----------------+---------------+ is the ‘55’ valuable information?
- 22. 22 Another example select x, sum(x) over w as 'sum' from x window w as (order by x); +----+-----+ | x | sum | +----+-----+ | 1 | 1 | 1 | 2 | 3 | 1 + 2 | 3 | 6 | 1 + 2 + 3 | 4 | 10 | 1 + 2 + 3 + 4 | 5 | 15 | 1 + 2 + 3 + 4 + 5 | 6 | 21 | ... | 7 | 28 | | 8 | 36 | | 9 | 45 | | 10 | 55 | +----+-----+
- 23. 23 UNBOUNDED PRECEDING is the DEFAULT select x, sum(x) over w as 'sum' from x window w as (ROWS UNBOUNDED PRECEDING); +----+-----+ | x | sum | +----+-----+ | 1 | 1 | | 2 | 3 | | 3 | 6 | | 4 | 10 | | 5 | 15 | | 6 | 21 | | 7 | 28 | | 8 | 36 | | 9 | 45 | | 10 | 55 | +----+-----+
- 24. 24 ROWS select x, sum(x) over w as 'sum' from x window w as (ROWS BETWEEN 1 PRECEDING AND CURRENT ROW); +----+-----+ | x | sum | +----+-----+ | 1 | 1 | 1 | 2 | 3 | 1 + 2 | 3 | 5 | 2 + 3 | 4 | 7 | 3 + 4 | 5 | 9 | 5 + 4 | 6 | 11 | | 7 | 13 | | 8 | 15 | | 9 | 17 | | 10 | 19 | +----+-----+
- 25. 25 ROWS select x, sum(x) over w as 'sum' from x window w as (ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING); +----+-----+ | x | sum | +----+-----+ | 1 | 3 | 1 + 2 = 3 | 2 | 6 | 1 + 2 + 3 = 6 | 3 | 9 | 2 + 3 + 4 = 9 | 4 | 12 | 3 + 4 + 5 = 12 | 5 | 15 | | 6 | 18 | | 7 | 21 | | 8 | 24 | | 9 | 27 | | 10 | 19 | +----+-----+
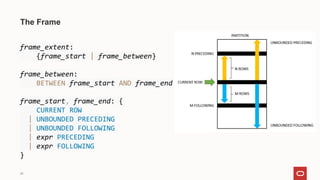
- 26. 26 The Frame frame_extent: {frame_start | frame_between} frame_between: BETWEEN frame_start AND frame_end frame_start, frame_end: { CURRENT ROW | UNBOUNDED PRECEDING | UNBOUNDED FOLLOWING | expr PRECEDING | expr FOLLOWING }
- 27. 27 A new data set select * from employee; +----+-------+------+-----+ | id | name | dept | pay | +----+-------+------+-----+ | 1 | Moe | 1 | 100 | | 2 | Larry | 1 | 100 | | 3 | Curly | 1 | 100 | | 4 | Shemp | 2 | 110 | | 5 | Joe | 2 | 50 | | 6 | Ted | 2 | 88 | +----+-------+------+-----+
- 28. 28 Partitioning by department select name, dept, pay, sum(pay) over w as 'sum' from employee window w as (PARTITION BY dept); +-------+------+-----+-----+ | name | dept | pay | sum | +-------+------+-----+-----+ | Moe | 1 | 100 | 300 | | Larry | 1 | 100 | 300 | | Curly | 1 | 100 | 300 | | Shemp | 2 | 110 | 248 | | Joe | 2 | 50 | 248 | | Ted | 2 | 88 | 248 | +-------+------+-----+-----+
- 29. 29 Order the partition - redefine the partition select dept, pay, sum(pay) over w as 'sum' from employee window w as (PARTITION BY dept order by pay); +------+-----+-----+ | dept | pay | sum | +------+-----+-----+ | 1 | 100 | 300 | | 1 | 100 | 300 | | 1 | 100 | 300 | | 2 | 50 | 50 | <- now sorted within dept | 2 | 88 | 138 | | 2 | 110 | 248 | +------+-----+-----+
- 30. 30 Multiple windows select dept, pay, sum(pay) over w as 'dept sum', sum(pay) over y 'total' from employee window w as (PARTITION BY dept), y as (ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW); +------+-----+----------+-------+ | dept | pay | dept sum | total | +------+-----+----------+-------+ | 1 | 100 | 300 | 100 | | 1 | 100 | 300 | 200 | 100 + 100 | 1 | 100 | 300 | 300 | 100 + 100 + 100 | 2 | 110 | 248 | 410 | 100 + 100 + 100 + 110 | 2 | 50 | 248 | 460 | 100 + 100 + 100 + 110 + 50 | 2 | 88 | 248 | 548 | 100 + 100 + 100 + 100 + 50 + 88 +------+-----+----------+-------+
- 31. 31 RANK() function select name, pay, rank() over (order by id) as 'rank' from employee; +-------+-----+------+ | name | pay | rank | +-------+-----+------+ | Moe | 100 | 1 | | Larry | 100 | 2 | | Curly | 100 | 3 | | Shemp | 110 | 4 | | Joe | 50 | 5 | | Ted | 88 | 6 | +-------+-----+------+ Ranking by ‘id’ may not be valuable information!
- 32. 32 Ranking by pay high to low select name, pay, rank() over (order by pay desc) as 'rank' from employee; +-------+-----+------+ | name | pay | rank | +-------+-----+------+ | Shemp | 110 | 1 | | Moe | 100 | 2 | | Larry | 100 | 2 | | Curly | 100 | 2 | | Ted | 88 | 5 | | Joe | 50 | 6 | +-------+-----+------+
- 33. 33 Percentage Rank select name, pay, percent_rank() over (order by id) as '%rank' from employee; +-------+-----+-------+ | name | pay | %rank | +-------+-----+-------+ | Moe | 100 | 0 | 0% | Larry | 100 | 0.2 | 20% | Curly | 100 | 0.4 | 40% | Shemp | 110 | 0.6 | 60% | Joe | 50 | 0.8 | 80% | Ted | 88 | 1 | 100% +-------+-----+-------+ Warning -- you have to be careful to make sure you are using the proper partition to get meaningful data. The information in this example is really not useful.
- 34. 34 Percentage Rank with order by pay select name, pay, percent_rank() over (order by pay) as '%rank' from employee; +-------+-----+-------+ | name | pay | %rank | +-------+-----+-------+ | Joe | 50 | 0 | | Ted | 88 | 0.2 | | Moe | 100 | 0.4 | | Larry | 100 | 0.4 | | Curly | 100 | 0.4 | | Shemp | 110 | 1 | +-------+-----+-------+
- 35. 35 Low to high select name, pay, percent_rank() over (order by pay) as '%rank', rank() over( order by pay) 'rank (l-h)' from employee; +-------+-----+-------+------------+ | name | pay | %rank | rank (l-h) | +-------+-----+-------+------------+ | Joe | 50 | 0 | 1 | | Ted | 88 | 0.2 | 2 | | Moe | 100 | 0.4 | 3 | | Larry | 100 | 0.4 | 3 | | Curly | 100 | 0.4 | 3 | | Shemp | 110 | 1 | 6 | +-------+-----+-------+------------+
- 36. 36 The various rank functions all in one query! select name, pay, rank() over w as 'rank', dense_rank() over w as 'dense', percent_rank() over w as '%' from employee window w as (order by pay desc); +-------+-----+------+-------+-----+ | name | pay | rank | dense | % | +-------+-----+------+-------+-----+ | Shemp | 110 | 1 | 1 | 0 | | Moe | 100 | 2 | 2 | 0.2 | | Larry | 100 | 2 | 2 | 0.2 | | Curly | 100 | 2 | 2 | 0.2 | | Ted | 88 | 5 | 3 | 0.8 | | Joe | 50 | 6 | 4 | 1 | +-------+-----+------+-------+-----+
- 37. 37 Cumulative Distribution select name, pay, percent_rank() over (order by pay) as '%rank', rank() over( order by pay) 'rank (l-h)', dense_rank() over(order by pay) as 'dense', cume_dist() over (order by pay) as 'cumulative' from employee; +-------+-----+-------+------------+-------+---------------------+ | name | pay | %rank | rank (l-h) | dense | cumulative | +-------+-----+-------+------------+-------+---------------------+ | Joe | 50 | 0 | 1 | 1 | 0.16666666666666666 | | Ted | 88 | 0.2 | 2 | 2 | 0.3333333333333333 | | Moe | 100 | 0.4 | 3 | 3 | 0.8333333333333334 | | Larry | 100 | 0.4 | 3 | 3 | 0.8333333333333334 | | Curly | 100 | 0.4 | 3 | 3 | 0.8333333333333334 | | Shemp | 110 | 1 | 6 | 4 | 1 | +-------+-----+-------+------------+-------+---------------------+
- 38. 38 Calculating percentages SELECT name, pay, ROUND(pay / sum(pay) over() * 100,2) as '%' FROM employee order by pay desc; +-------+-----+-------+ | name | pay | % | +-------+-----+-------+ | Shemp | 110 | 20.07 | | Moe | 100 | 18.25 | | Larry | 100 | 18.25 | | Curly | 100 | 18.25 | | Ted | 88 | 16.06 | | Joe | 50 | 9.12 | +-------+-----+-------+
- 39. 39 Quartiles - actually ntiles SELECT name, pay, ROUND(pay / sum(pay) over() * 100,2) as '%', NTILE(4) over() as 'quartile' FROM employee order by pay asc; +-------+-----+-------+----------+ | name | pay | % | quartile | +-------+-----+-------+----------+ | Joe | 50 | 9.12 | 1 | | Ted | 88 | 16.06 | 1 | | Moe | 100 | 18.25 | 2 | | Larry | 100 | 18.25 | 2 | | Curly | 100 | 18.25 | 3 | | Shemp | 110 | 20.07 | 4 | +-------+-----+-------+----------+ In statistics, a quartile is a type of quantile which divides the number of data points into four parts, or quarters, of more-or-less equal size. The data must be ordered from smallest to largest to compute quartiles -- https://en.wikipedia.org/wiki/Quartile
- 40. 40 Calculate average and difference from average SELECT name, pay, ROUND(AVG(pay) over(),2) as 'avg', ROUND(pay - AVG(pay) over(),2) as 'diff to avg' FROM employee order by pay desc; +-------+-----+-------+-------------+ | name | pay | avg | diff to avg | +-------+-----+-------+-------------+ | Shemp | 110 | 91.33 | 18.67 | | Moe | 100 | 91.33 | 8.67 | | Larry | 100 | 91.33 | 8.67 | | Curly | 100 | 91.33 | 8.67 | | Ted | 88 | 91.33 | -3.33 | | Joe | 50 | 91.33 | -41.33 | +-------+-----+-------+-------------+
- 41. 41 Calculate difference to next employee pay SELECT name, pay, pay - LEAD(pay,1) OVER(order by pay desc) as 'diff next' FROM employee order by pay desc; +-------+-----+-----------+ | name | pay | diff next | +-------+-----+-----------+ | Shemp | 110 | 10 | 110 - 100 | Moe | 100 | 0 | 100 - 100 | Larry | 100 | 0 | 100 - 100 | Curly | 100 | 12 | 100 - 88 | Ted | 88 | 38 | 88 - 50 | Joe | 50 | NULL | +-------+-----+-----------+ LEAD(col,N) gets row N from col
- 42. 42 LAG() select a, LAG(a,1) over w as 'lag(1)', LAG(a,2) over w as 'lag(2)' from w1 window w as (order by a); +---+--------+--------+ | a | lag(1) | lag(2) | +---+--------+--------+ | 1 | NULL | NULL | | 2 | 1 | NULL | | 3 | 2 | 1 | | 4 | 3 | 2 | +---+--------+--------+ LAG as in ‘lag behind’
- 43. 43 LEAD() select a, LEAD(a,1) over w as 'lead(1)', LEAD(a,2) over w as 'lead(2)' from w1 window w as (order by a); +---+---------+---------+ | a | lead(1) | lead(2) | +---+---------+---------+ | 1 | 2 | 3 | | 2 | 3 | 4 | | 3 | 4 | NULL | | 4 | NULL | NULL |
- 44. 44 SYNTAX for Window Functions over_clause: {OVER (window_spec) | OVER window_name} window_spec: [window_name] [partition_clause] [order_clause] [frame_clause] partition_clause: PARTITION BY expr [, expr] ... order_clause: ORDER BY expr [ASC|DESC] [, expr [ASC|DESC]] ...
- 45. 45 And that is the end of this introduction
- 46. ❏ Window Functions, MySQL Manual - https://dev.mysql.com/doc/refman/8.0/en/window-functions.html ❏ ❏ Windows Magic Postgres -- https://momjian.us/main/writings/pgsql/window.pdf ❏ ❏ SQL Window Functions - https://mode.com/sql-tutorial/sql-window-functions/ ❏ ❏ Intro to Window Functions in SQL -- https://towardsdatascience.com/intro-to-window-functions-in-sql-23ecdc7c1ceb 46 Where to learn more
- 47. Copyright © 2020, Oracle and/or its affiliates | Confidential: Internal/Restricted/Highly Restricted 47 Get $300 in credits and try MySQL Database Service free for 30 days. https://www.oracle.com/cloud/free/ Test Drive MySQL Database Service For Free Today
- 48. Follow us on Social Media Copyright © 2020, Oracle and/or its affiliates 48 MySQLCommunity.slack.com
- 49. Startups get cloud credits and a 70% discount for 2 years, global exposure via marketing, events, digital promotion, and media, plus access to mentorship, capital and Oracle’s 430,000+ customers Customers meet vetted startups in transformative spaces that help them stay ahead of their competition Oracle stays at the competitive edge of innovation with solutions that complement its technology stack We have saved around 40% of our costs and are able to reinvest that back into the business. And we are scaling across EMEA, and that’s basically all because of Oracle.” —Asser Smidt CEO and Cofounder, BotSupply Oracle for Startups - enroll at oracle.com/startup A Virtuous Cycle of Innovation, Everybody Wins. Copyright © 2020, Oracle and/or its affiliates | Confidential: Internal/Restricted/Highly Restricted 49
- 50. Then please consider buying my book on the JSON data type, how to use the supporting functions, and it is filled with example code to get you up to speed! Interested in using JSON with MySQL? Copyright © 2020, Oracle and/or its affiliates | Confidential: Internal/Restricted/Highly Restricted 50
- 51. Thank You! [email protected] @Stoker slideshare.net/davestokes 51 Copyright © 2020, Oracle and/or its affiliates Q&A