Data ops: Machine Learning in production
10 likes•1,914 views

The document discusses the challenges and solutions for deploying machine learning in production, focusing on the architecture, data quality, and monitoring aspects. It highlights the importance of a unified framework for data processing and experimentation to ensure reliability and efficiency in model deployment. Key takeaways include the need for schema-first design, automated data profiling, and predictive retraining to minimize errors and enhance machine learning operations.














![Model server = Model Artifact + ...
matching_model v2
[
....
]
Build Docker and deploy to the cloud.
Now what?
It is still an anonymous black box.](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-15-320.jpg)
![Model server = Model Artifact +
Metadata + Runtime + Deps
/predict
input:
string text;
bytes image;
output:
string summary;
JVM DL4j
GPU
matching_model v2
[
....
]
gRPC HTTP server](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-16-320.jpg)
![Model server = Model Artifact +
Metadata + Runtime + Deps + Sidecar
/predict
input:
string text;
bytes image;
output:
string summary;
JVM DL4j
GPU
matching_model v2
[
....
]
gRPC HTTP server
routing, shadowing
pipelining
tracing
metrics
autoscaling
A/B, canary
sidecar
serving
requests](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-17-320.jpg)
















![Step 1: Schema first design
● Data defines the contracts and API between components
● Avro/Protobuf for all data records
● Confluent Schema Registry to manage Avro schemas
● Not only for Kafka. Must be used for all the data
pipelines (batch, Spark, etc)
{"namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "number", "type": ["int", "null"]},
{"name": "color", "type": ["string", "null"]}
]
}](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-35-320.jpg)

![Step 2: Extend schema
● Avro/Protobuf can catch data format bugs
● How about data profile? Min, max, mean, etc?
● Describe a data profile, statistical properties and
validation rules in extended schema!
{"name": "User",
"fields": [
{"name": "name", "type": "string", "min_length": 2, "max_length": 128},
{"name": "age", "type": ["int", "null"], "range": "[10, 100]"},
{"name": "sex", "type": ["string", "null"], " enum": "[male, female, ...]"},
{"name": "wage", "type": ["int", "null"], "validator": "DSL here..."}
]
}](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-37-320.jpg)



![Model server = Metadata + Model Artifact +
Runtime + Deps + Sidecar + Training Metadata
/predict
input:
output:
JVM DL4j
GPU
matching_model v2
[
....
]
gRPC HTTP server
sidecar
serving
requests
training data stats:
- min
- max
- clusters
- autoencoder
compare with prod
data in runtime](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-41-320.jpg)









Data ops: Machine Learning in production
- 1. DataOps: Machine Learning in Production Stepan Pushkarev CTO of Hydrosphere.io
- 2. Mission: Accelerate Machine Learning to Production Opensource Products: - Mist: Serverless proxy for Spark - ML Lambda: ML Function as a Service - Sonar: Data and ML Monitoring Business Model: Subscription services and hands-on consulting About
- 3. How long is the journey?
- 4. How long is the journey?
- 5. Challenges in Production Solutions Ad-hoc and disjointed application and deployment architecture Training / serving data skew Reference architecture of data pipelines and machine learning pipelines Hand-off between Data Scientist -> ML Eng -> Data Eng -> SA Eng -> QA -> Ops Streamline deployment Data format drifts, new data, wrong features Biased Training set / training issue Model Degradation Schema first design Manual Quality Models Statistical Quality Models Unsupervised / automatic quality models Predictive retraining Continuous labeling and active learning Performance issues Model Optimisations (out of the scope) Vulnerability issues, malicious users, adversarial input Adversarial training (out of the scope today)
- 6. Application Architectures are well studied
- 7. S3/HDFS/DWH ML Architecture: data scientist + S3 = magic? train.py prepare.py clean.py
- 8. Challenges of isolated ML architectures - Focus on training. Serving and re-training is not designed - Isolated from the rest of the applications and the team - Offline. Turning into interactive multi-tenant is a pain - Designed for static “Kaggle” dataset while 90% of the world’s data points have a timestamp (it’s live!) - Batch. Painful to turn into streaming. - For internal use. No SLA to support real production users - Plan to throw one away - PoC mode, not designed for QA
- 9. Reference Architecture that matters
- 10. Streaming ML Architecture that matters Comfort Zone for Data Scientist in the middle of Production
- 11. ML architecture takeaways ● Should be designed in house from the day one - no yet another “Big Data Lake Platforms” for enterprise ● No data silos and forks. Up-to-date valid identical state (data sets) for offline, batch, real-time and interactive use cases ● Unified experimentation, testing and production environments ● Unified data and application architecture. All applications are data driven all data processing stages are built as applications. ● Unified deployment, monitoring and metrics infrastructure
- 12. Challenges in Production Solutions Ad-hoc and disjointed application and infrastructure architecture Training / serving data skew Reference architecture examples Hand-off between Data Scientist -> ML Eng -> Data Eng -> SA Eng -> QA -> Ops Streamline deployment Data format drifts, new data, wrong features Biased Training set / training issue Model Degradation Schema first design Manual Quality Models Statistical Quality Models Unsupervised / automatic quality models Predictive retraining Continuous labeling and active learning Performance issues Model Optimisations (out of the scope) Vulnerability issues, malicious users, adversarial input Adversarial training (out of the scope today)
- 13. ML deployment and serving requirements - Plumbing: Model metadata for REST, gRPC or Streaming API - Unified across ML frameworks - Immutable model versioning - Agnostic to training pipeline and notebook environment - Support for stateful and unsupervised models - Support for prediction, search and recommendation models - Support for model meta-pipelines (e.g. encoder->decoder) - Infrastructure and runtime optimized for Serving - Model optimization for Serving - Support for streaming applications
- 14. Streamline Deployment and integration model.pkl model.zip How to integrate it into AI Application?
- 15. Model server = Model Artifact + ... matching_model v2 [ .... ] Build Docker and deploy to the cloud. Now what? It is still an anonymous black box.
- 16. Model server = Model Artifact + Metadata + Runtime + Deps /predict input: string text; bytes image; output: string summary; JVM DL4j GPU matching_model v2 [ .... ] gRPC HTTP server
- 17. Model server = Model Artifact + Metadata + Runtime + Deps + Sidecar /predict input: string text; bytes image; output: string summary; JVM DL4j GPU matching_model v2 [ .... ] gRPC HTTP server routing, shadowing pipelining tracing metrics autoscaling A/B, canary sidecar serving requests
- 18. ML applications
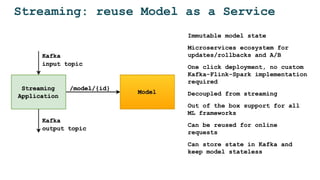
- 19. Streaming: reuse Model as a Service Immutable model state Microservices ecosystem for updates/rollbacks and A/B One click deployment, no custom Kafka-Flink-Spark implementation required Decoupled from streaming Out of the box support for all ML frameworks Can be reused for online requests Can store state in Kafka and keep model stateless
- 20. TF Serving challenges ● Other ML runtimes (DL4J, Scikit, Spark ML). Servables are overkill. ● Need better versioning and immutability (Docker per version) ● Don’t want to deal with state (model loaded, offloaded, etc) ● Want to re-use microservices stack (tracing, logging, metrics) ● Need better scalability
- 21. AWS SageMaker challenges ● Cost. m4.xlarge per model. 100 models = 100 m4.xlarge ● No Model API and metadata. Model is still a black box ● No Versioning AWS SageMaker advantages ● Great docs and quick starts ● Integration with AWS ecosystem ● Python SDK and notebooks integration model.zip
- 22. Model Deployment takeaways ● Eliminates hand-off between Data Scientist -> ML Eng -> Data Eng -> SA Eng -> QA -> Ops ● Sticks components together: Data + Model + Applications + Automation = AI Application ● Enables quick transition from research to production. ML engineers can deploy models many times a day But wait… This is not safe! How to ensure we’ll not break things in prod?
- 23. Challenges in Production Solutions Ad-hoc and disjointed application and infrastructure architecture Training / serving data skew Reference architecture examples Hand-off between Data Scientist -> ML Eng -> Data Eng -> SA Eng -> QA -> Ops Streamline deployment Data format drifts, new data, wrong features Biased Training set / training issue Model Degradation Concept drift Schema first design Manual Quality Models Statistical Quality Models Unsupervised / automatic quality models Predictive retraining Continuous labeling and active learning Performance issues Model Optimisations (out of the scope) Vulnerability issues, malicious users, adversarial input Adversarial training (out of the scope today)
- 24. Cost of AI/ML Error ● Fun © http://blog.ycombinator.com/how-adversarial-attacks-work/
- 25. ● Fun ● Not fun Cost of AI Error
- 26. ● Fun ● Not fun ● Not fun at all... Cost of AI/ML Error
- 27. ● Fun ● Not fun ● Not fun at all… ● People life Cost of AI Error
- 28. ● Fun ● Not fun ● Not fun at all… ● People life ● Money Cost of AI/ML Error
- 29. ● Fun ● Not fun ● Not fun at all… ● People life ● Money ● Business Cost of ML Error
- 30. Where may AI fail in prod? Everywhere!
- 31. Where may AI fail in prod? ● Bad training data ● Bad serving data ● Training/serving data skew ● Misconfiguration ● Deployment issue ● Retraining issue ● Performance Everywhere!
- 32. Data exploration in production Research: Data Scientist makes assumptions based on results of data exploration
- 33. Data exploration in production Research: Data Scientist explores datasets and makes assumptions/hypothesis Production: The model works if and only if the format and statistical properties of prod data are the same as in research Push to Prod
- 34. Data exploration in production Research: Data Scientist makes assumptions based on results of data exploration Production: The model works if and only if format and statistical properties of prod data are the same as in research Push to Prod Continuous data exploration and validation?
- 35. Step 1: Schema first design ● Data defines the contracts and API between components ● Avro/Protobuf for all data records ● Confluent Schema Registry to manage Avro schemas ● Not only for Kafka. Must be used for all the data pipelines (batch, Spark, etc) {"namespace": "example.avro", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "number", "type": ["int", "null"]}, {"name": "color", "type": ["string", "null"]} ] }
- 37. Step 2: Extend schema ● Avro/Protobuf can catch data format bugs ● How about data profile? Min, max, mean, etc? ● Describe a data profile, statistical properties and validation rules in extended schema! {"name": "User", "fields": [ {"name": "name", "type": "string", "min_length": 2, "max_length": 128}, {"name": "age", "type": ["int", "null"], "range": "[10, 100]"}, {"name": "sex", "type": ["string", "null"], " enum": "[male, female, ...]"}, {"name": "wage", "type": ["int", "null"], "validator": "DSL here..."} ] }
- 38. Extended schema generate to Data Quality metrics Metrics types: ● Profiling ● Timeliness ● Completeness
- 39. Step 3: Generate Extended Schema ● Manually specified schema provides data quality model and improves data pipeline reliability but hard to maintain ● We can automatically profile data shapes and generate statistical properties to be used in extended schema
- 40. Step 4: Clustering and Anomaly detection ● How to deal with multidimensional datasets and complicated seasonality ● Rule based programs -> statistical models -> machine learning models Algorithms to consider: ● Deep Autoencoders ● Density based clustering algorithms with Elbow method ● Clustering algorithms with Silhouette method
- 41. Model server = Metadata + Model Artifact + Runtime + Deps + Sidecar + Training Metadata /predict input: output: JVM DL4j GPU matching_model v2 [ .... ] gRPC HTTP server sidecar serving requests training data stats: - min - max - clusters - autoencoder compare with prod data in runtime
- 42. Model Monitoring ● Feedback loop for ML Engineer ● Eliminates hand-off with Ops ● Safe experiment on shadowed traffic ● Shifts experimentation to prod environment ● Fills the gap between research and prod ● Correlation with business metrics
- 43. Research: Quality monitoring of NLU system Figure from: Bapna, Ankur, et al. "Towards zero-shot frame semantic parsing for domain scaling." arXiv preprint arXiv:1707.02363 (2017).
- 44. Research: Quality monitoring of NLU system Source image: Kurata, Gakuto, et al. "Leveraging sentence-level information with encoder lstm for semantic slot filling." arXiv preprint arXiv:1601.01530 (2016). ● Train and test offline on restaurants domain ● Deploy do prod ● Feed the model with new random Wiki data ● Monitor intermediate input representations (neural network hidden states)
- 45. Research: Quality monitoring of NLU system ● Red and Purple - cluster of “Bad” production data ● Yellow and Blue - dev and test data
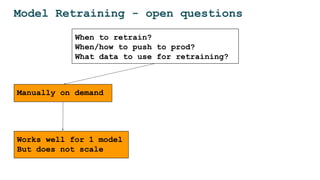
- 46. Model Retraining - open questions When to retrain? When/how to push to prod? What data to use for retraining? Manually on demand Works well for 1 model But does not scale
- 47. Model Retraining - open questions When to retrain? When/how to push to prod? What data to use for retraining? Manually on demand Works well for 1 model But does not scale Automatically by schedule Not safe Can be expensive
- 48. Solution: Predictive Retraining + Safe Deployment ● Retrain when model monitoring alerts ● Warm up new models on shadowed/canary traffic ● Optionally relabel ● Rollback automatically when monitoring alerts ● Build retraining dataset from monitoring stats
- 49. Quality Solutions takeaways ● Makes ML in production safe and predictable ● Allows ML operation to scale in prod to hundreds and thousands models ● Blurs the line between research and production by enabling ML experiments on shadowed or canary traffic ● Data Quality model should be a part of the Protocol ● Very dirty and time consuming job of Data QA can be automated with machine learning
- 50. Webinar takeaway: Production-ready ML apps with the speed of Prototyping
- 51. Thank you - Stepan Pushkarev - @hydrospheredata - https://github.com/Hydrospheredata - https://hydrosphere.io/ - [email protected]