Data Pipeline with Kafka
6 likes1,407 views

The document discusses the implementation of a data pipeline using Apache Kafka, highlighting components like big data integration, monitoring, and configuration details. It provides practical installation instructions, including Vagrant and Brew commands for setting up Kafka and Zookeeper. Additionally, the document features performance metrics from Kafka usage at LinkedIn and includes references for further exploration of Kafka-related resources.































Data Pipeline with Kafka
- 1. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Data Pipeline with Kafka Peerapat Asoktummarungsri AGODA
- 2. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Senior Software Engineer Agoda.com Contributor Thai Java User Group (THJUG.com) Contributor Agile66
- 3. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. AGENDA Big Data & Data Pipeline Kafka Introduction Quick Start Monitoring Data Pipeline for Search API Hadoop integration with Camus
- 4. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Hadoop + HDFS Information Big Data MapReduce
- 5. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Pipeline hadoopWebsite log
- 6. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. hadoopWebsite Mobile Growth log
- 7. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. hadoopWebsite Mobile realtime monitoring Complex log message
- 8. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. New New hadoopWebsite Mobile realtime monitoring Data Warehouse API Features becomes the problem NEW
- 9. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. hadoop Website Mobile realtime monitoring API Data Pipeline Produce Consume Data Pipeline Warehouse
- 10. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. compare Topic Queue Consumer Consumer Consumer Consumer Consumer Consumer 1 2 3 1 1 1
- 11. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. General Topic Implement Topic Consumer 1 Consumer 2 Consumer 3 2 2 This consumer will lose a message.
- 12. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Distributed by Design Fast Scalable - It can be elastically and transparently expanded without downtime. Durable - Messages are persisted on disk and replicated within the cluster to prevent data loss.
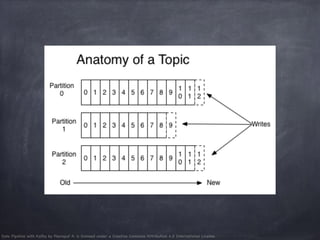
- 13. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Topic Consumer 1 Consumer 2 Consumer 3 msg gid = Group ID msg msg 1 2 3 4 7 6 5 gid = hadoop
- 14. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Topic hadoop gid = hadoop realtime monitoring data warehouse msg gid = Group ID msg msg 12 gid = rtmon gid = warehouse 3 123 123
- 15. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Topic hadoop gid = hadoop realtime monitoring data warehouse msg gid = Group ID msg 9 gid = rtmon gid = warehouse 9 9 New Consumer 1 2 3 gid = newconsumer
- 16. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License.
- 17. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Vagrant Install Vagrant Install Virtual Box Clone https://github.com/stealthly/scala-kafka vagrant up
- 18. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. BREW brew update brew install zookeeper kafka -y
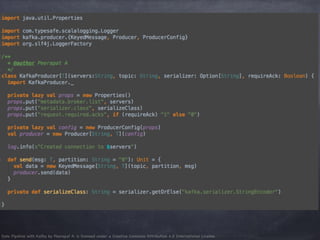
- 19. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Some Kafka Config # The id of the broker. This must be set to a unique integer for each broker. broker.id=0 # The port the socket server listens on port=9092 # Zookeeper connection string (see zookeeper docs for details). zookeeper.connect=localhost:2181 # Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=6000 # The minimum age of a log file to be eligible for deletion log.retention.hours=168
- 20. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Kafka @ Linkedin (2013) 10 billion message writes per day 55 billion messages delivered to real-time consumers 367 topics that cover both user activity topics and operational data the largest of which adds an average of 92GB per day of batch-compressed messages Messages are kept for 7 days, and these average at about 9.5 TB of compressed messages across all topics.
- 21. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. KafkaOffsetMonitor java -cp KafkaOffsetMonitor-assembly-0.2.1.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --zk localhost --port 8080 --refresh 10.seconds --retain 2.days Download KafkaOffsetMonitor from Github https://github.com/quantifind/KafkaOffsetMonitor 1 Jar file, KafkaOffsetMonitor-assembly-0.2.1.jar
- 22. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License.
- 23. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License.
- 24. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License.
- 25. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License.
- 26. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License.
- 27. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License.
- 28. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. CHANGE Produce Change Price & Inventory Consumer Cassandra Search API Calculate Price HTTP KafkaAPI Hotel Manager Hotels
- 29. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. CHANGE KafkaAPI Hotel Manager Hotels B Consumer A Consumer Price & Inventory Consumer
- 30. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Camus
- 31. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. http://www.slideshare.net/nuboat https://github.com/nuboat/akkakafkaexam Slide available here Sourcecode available here
- 32. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. REFERENCES http://www.slideshare.net/charmalloc/ developingwithapachekafka-29910685 http://www.infoq.com/articles/apache-kafka http://kafka.apache.org/ https://github.com/stealthly/scala-kafka https://github.com/quantifind/KafkaOffsetMonitor
- 33. Data Pipeline with Kafka by Peerapat A. is licensed under a Creative Commons Attribution 4.0 International License. Q & A