Data Privacy with Apache Spark: Defensive and Offensive Approaches
2 likes797 views

The document discusses data privacy in the context of Apache Spark, focusing on both defensive and offensive techniques for managing sensitive information. It covers various approaches such as pseudonymization, anonymization, tokenization, and hashing, emphasizing the importance of data compliance with regulations like GDPR and CCPA. Additionally, the document highlights the complexities and challenges associated with implementing effective data privacy measures in machine learning systems.















![Free-form data
❏ Fully depends on your specific
dataset, generic solution is
hardly possible
❏ Use ensemble of different
techniques to remove sensitive
pieces out of free-form text
❏ %pip install names-dataset can
get you 160k+ different names,
that you can use as a filter.
Enhance it with more region and
business-specific data.
secretSalt = dbutils.secrets.get("dais2020-data-privacy-talk", "salt")
def purePythonSaltedObscureHash(x):
import hashlib, base64
sha512 = hashlib.sha512()
sha512.update((secretSalt + x).encode('utf-8'))
first_bytes = bytes.fromhex(sha512.hexdigest()[0:32])
return base64.b64encode(first_bytes).decode('utf-8').replace('=', '')
@pandas_udf('string', PandasUDFType.SCALAR)
def free_form_cleanup(series):
def inner(text):
from pkg_resources import resource_filename
all_names = {'first': set(), 'last': set()}
for t in all_names.keys():
with open(resource_filename('names_dataset', f'{t}_names.all.txt'), 'r') as x:
all_names[t] = set(x.read().strip().split('n'))
new_text = []
for word in text.split(" "):
# Only simplest techniques are shown. Recommended ensemble of:
# 1) Regex rules for IP/Emails/ZIP codes
# 2) Named Entity recognition
# 3) Everything is very specific to data you have
if word.lower() in all_names['first']:
word = purePythonSaltedObscureHash(word)
if word.lower() in all_names['last']:
word = purePythonSaltedObscureHash(word)
new_text.append(word)
return " ".join(new_text)
return series.apply(inner)
(spark.table('free_form')
.select('id', 'subject')
.withColumn('safer_subject', free_form_cleanup(col('subject'))))](https://image.slidesharecdn.com/304sergesmertin-201130191837/85/Data-Privacy-with-Apache-Spark-Defensive-and-Offensive-Approaches-16-320.jpg)





![val normalize = (x: Column) => lower(x)
def fanoutOriginals(columns: Seq[String], df: DataFrame) =
df.withColumn("wrapper", array(
columns.map(c => struct(lit(c) as "k", col(c) as "v")): _*))
.select(explode('wrapper))
.selectExpr("col.*")
.withColumn("v", normalize('v))
.dropDuplicates("k", "v")
def replaceOriginalsWithTokens(columns: Seq[String],
df:DataFrame, tokens: DataFrame) =
columns.foldLeft(df)((df, c) =>
df.withColumn(c, normalize(col(c)))
.withColumnRenamed(c, s"${c}_normalized")
.join(tokens.where('k === c)
.withColumnRenamed("v", s"${c}_normalized")
.withColumnRenamed("token", c),
Seq(s"${c}_normalized"), "left"))
.select(df.columns.map(col(_)): _*)
def tokenizeSnapshot(columns: String*)(df: DataFrame) = {
val newToken = row_number() over Window.orderBy(rand())
val tokens = fanoutOriginals(columns, df)
.withColumn("token", newToken)
replaceOriginalsWithTokens(columns, df, tokens)
}
val generic = spark.table("resellers").transform(
tokenizeSnapshot("email", "name", "joindate", "city", "industry"))
display(generic)
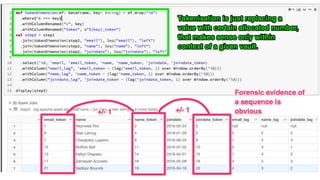
● protects from sequence attacks by
randomizing token allocation within append
microbatch
● good for a quick demonstration of concepts
● doesn't do the most important thing - persist
token <-> value relationships in a vault
● generically applies tokenization to specified
columns](https://image.slidesharecdn.com/304sergesmertin-201130191837/85/Data-Privacy-with-Apache-Spark-Defensive-and-Offensive-Approaches-23-320.jpg)
![import java.lang.Thread
import java.util.ConcurrentModificationException
import org.apache.spark.sql.expressions.Window
def allocateNewTokens(columns: Seq[String],
df: DataFrame): DataFrame = {
val vault = df.sparkSession.table("token_vault")
for (i <- 1 to 10) try {
val startingToken = vault.agg(
coalesce(max('token), lit(0))).first()(0)
val newToken = lit(startingToken) + (
row_number() over Window.orderBy(rand()))
fanoutOriginals(columns, df)
.join(vault, Seq("k", "v"), "left")
.where('token.isNull)
.withColumn("token", newToken)
.write.mode("append").format("delta")
.saveAsTable("token_vault")
return vault
} catch { case e: ConcurrentModificationException if i < 10 =>
print("Retrying token allocation")
}
return vault
}
def tokenizeWithVault(columns: String*)(df: DataFrame) =
replaceOriginalsWithTokens(columns, df,
allocateNewTokens(columns, df))
● The busiest place of data ingestion, so
consider running OPTIMIZE token_vault
ZORDER BY (v) to help with writes.
● Randomization is done on microbatch level, so
we get shuffle only for new tokens, keeping
implementation simpler
● token is assigned as long, populated with
row_number() over random window.
monotonically_increasing_id() is not used
because it gives inaccurate results, as it's
computed within Spark partition. UUID is not
used because of consistency-related
performance reasons
Token Vault with
Databricks Delta](https://image.slidesharecdn.com/304sergesmertin-201130191837/85/Data-Privacy-with-Apache-Spark-Defensive-and-Offensive-Approaches-24-320.jpg)
















Data Privacy with Apache Spark: Defensive and Offensive Approaches
- 1. Data Privacy with Apache Spark: Defensive and Offensive Approaches Serge Smertin Resident Solutions Architect Databricks
- 2. About me ▪ Worked in all stages of data lifecycle for the past 13 years ▪ Built data science platforms from scratch ▪ Tracked cyber criminals through massively scaled data forensics ▪ Built anti-PII analysis measures for payments industry ▪ Bringing Databricks strategic customers to next level as full-time job now
- 3. About you ▪ Most likely very hands-on with Apache Spark™ ▪ Background in data engineering, information security and a bit of cloud infrastructure ▪ Want (or asked) to limit the data to maintain privacy and comply with regulations ▪ About to be familiar with GDPR or CCPA ▪ Genuine curiosity how to do that with the least number of different tools
- 4. ML Code Configuration Data Collection Data Verification Feature Extraction Machine Resource Management Analysis Tools Process Management Tools Serving Infrastructure Only a small fraction of real-world ML systems is composed of the ML code, as shown by the small green box in the middle. The required surrounding infrastructure is vast and complex. - “Hidden Technical Debt in Machine Learning Systems,” Google NIPS 2015 Monitoring Data Privacy (this talk) not based on Google paper
- 5. Open-source intelligence (OSINT) ... is a multi-methods methodology for collecting, analyzing and making decisions about data accessible in publicly available sources to be used in an intelligence context. In the intelligence community, the term "open" refers to overt, publicly available sources. https://inteltechniques.com/JE/OSINT_Packet_2019.pdf
- 6. Offensive techniques ▪ Linkage attacks ▪ Sequence attacks ▪ Homogeneity attacks A.k.a. day-to-day data science
- 8. Technique comparison dimensions ▪ Usefulness ▪ how useful data would still be for applied data science? ▪ Difficulty to implement ▪ Effort it might take to implement and support solution in the short and long term? ▪ Schema preservation ▪ Do we need to make special schema considerations? ▪ Format preservation ▪ Would original and anonymized data points look the same to people analysing it? We’ll compare each of mentioned techniques across few common dimensions to help picking up the best for your use-case ▪ Performance impact ▪ How would it affect performance of entire data pipeline? ▪ Will it affect reads or writes? ▪ Is it going to involve shuffle? ▪ Re-identification ▪ What kinds of data forensic attacks could be performed to de-anonymise individuals?
- 9. Pseudonymization Protects datasets on record level for Machine Learning. Switches original data point with pseudonym for later re-identification, inaccessible to unauthorized users. A pseudonym is still considered to be personal data according to the GDPR. Anonymization Protects entire tables, databases or entire data catalogues mostly for Business Intelligence. Personal data is irreversibly altered in such a way that a data subject can no longer be identified directly or indirectly. Usually a combination of more than one technique used in real-world scenarios. kpkrdiTAnqvfxuyE ********************* 1AYrGFCTTRYOwO ********************* 72AjraZ8sU9EsNw *********************
- 10. A.k.a. Machine Learning engineers asking you when that concrete dataset is finally going to be pseudonymized, so that they can .fit_and_predict() their models Pseudonymization
- 11. Encryption ▪ Usefulness: high ▪ Difficulty: medium ▪ Schema: same ▪ Format: different ▪ Performance: more data, slow to encrypt & decrypt ▪ Re-identification: encryption key leak will allow re-identifying When someone thinks that AWS S3 or Azure ADLS encryption is not enough.
- 13. Hashing ▪ Usefulness: high ▪ Difficulty: easy ▪ Schema: same ▪ Format: different ▪ Performance: group by is slower ▪ Re-identification: hashcat, dictionary and/or combinator attacks Just SHA512() the sensitive data
- 14. Making hash cracking a bit more difficult resource "random_password" "salt" { special = true upper = true length = 32 } resource "databricks_secret_scope" "data_privacy" { name = "dais2020-data-privacy-talk" } resource "databricks_secret" "salt" { key = "salt" string_value = random_password.salt.result scope = databricks_secret_scope.data_privacy.name } val secretSalt = dbutils.secrets.get( "dais2020-data-privacy-talk", "salt") def obscureHash(x: Column) = translate( base64( // perform base64 encoding unhex( // instead of standard HEX one substring( // to confuse bad guys sha2(x, 512) // that it is just SHA-512 , 0, 32) // but truncated to first 16 bytes )), "=", "") // and some base64 characters removed def saltedObscureHash(x: Column) = obscureHash( concat(lit(secretSalt), x)) val df = spark.table("resellers") .select('email) .withColumn("hash", obscureHash('email)) .withColumn("salt", lit(secretSalt)) .withColumn("salted_hash", saltedObscureHash('email)) Hashing datasetTerraform configuration
- 15. If you think you can invent new salting technique, probably it’s already cracked by GPU’s with hashcat
- 16. Free-form data ❏ Fully depends on your specific dataset, generic solution is hardly possible ❏ Use ensemble of different techniques to remove sensitive pieces out of free-form text ❏ %pip install names-dataset can get you 160k+ different names, that you can use as a filter. Enhance it with more region and business-specific data. secretSalt = dbutils.secrets.get("dais2020-data-privacy-talk", "salt") def purePythonSaltedObscureHash(x): import hashlib, base64 sha512 = hashlib.sha512() sha512.update((secretSalt + x).encode('utf-8')) first_bytes = bytes.fromhex(sha512.hexdigest()[0:32]) return base64.b64encode(first_bytes).decode('utf-8').replace('=', '') @pandas_udf('string', PandasUDFType.SCALAR) def free_form_cleanup(series): def inner(text): from pkg_resources import resource_filename all_names = {'first': set(), 'last': set()} for t in all_names.keys(): with open(resource_filename('names_dataset', f'{t}_names.all.txt'), 'r') as x: all_names[t] = set(x.read().strip().split('n')) new_text = [] for word in text.split(" "): # Only simplest techniques are shown. Recommended ensemble of: # 1) Regex rules for IP/Emails/ZIP codes # 2) Named Entity recognition # 3) Everything is very specific to data you have if word.lower() in all_names['first']: word = purePythonSaltedObscureHash(word) if word.lower() in all_names['last']: word = purePythonSaltedObscureHash(word) new_text.append(word) return " ".join(new_text) return series.apply(inner) (spark.table('free_form') .select('id', 'subject') .withColumn('safer_subject', free_form_cleanup(col('subject'))))
- 17. Combinator attacks ❏ Adapted from combinator attack in Hashcat manual. ❏ Can be combined with permutations of name N-grams to cover for typos. E.g. Trigrams of “Serge”: ser, erg, rge. ❏ Simple, but still elegant, addition might involve fitting Markov chain to generate random names per region.
- 18. Credit card numbers ● 2.8 billion credit cards in use worldwide. ● Around 6k Bank Identification Number (BIN) ranges. ● Requires PCI DSS compliant storage infrastructure. ● Rules are very convoluted and sometimes contradictory. ● It’s best to use Tokenization instead of hashing.
- 19. Tokenization ▪ Usefulness: very high ▪ Difficulty: high ▪ Schema: almost ▪ strings become longs, making performance higher ▪ Format: different ▪ Performance: slower to write, faster to read ▪ Re-identification: depends Non-inferrable source-to-destination mapping def replaceTokensFromVault(columns: String*)(df: DataFrame) = { val vault = df.sparkSession.table("token_vault") columns.foldLeft(df)((df, c) => df.withColumnRenamed(c, s"${c}_token") .join(vault.where('k === c) .withColumnRenamed("v", c) .withColumnRenamed("token", s"${c}_token"), Seq(s"${c}_token"), "left")) .select(df.columns.map(col(_)): _*) } import spark._ val campaign = Seq( (399, 103), (327, 290), (353, 217)) .toDF .withColumnRenamed("_1", "email") .withColumnRenamed("_2", "name") .transform(replaceTokensFromVault("email", "name")) display(campaign)
- 23. val normalize = (x: Column) => lower(x) def fanoutOriginals(columns: Seq[String], df: DataFrame) = df.withColumn("wrapper", array( columns.map(c => struct(lit(c) as "k", col(c) as "v")): _*)) .select(explode('wrapper)) .selectExpr("col.*") .withColumn("v", normalize('v)) .dropDuplicates("k", "v") def replaceOriginalsWithTokens(columns: Seq[String], df:DataFrame, tokens: DataFrame) = columns.foldLeft(df)((df, c) => df.withColumn(c, normalize(col(c))) .withColumnRenamed(c, s"${c}_normalized") .join(tokens.where('k === c) .withColumnRenamed("v", s"${c}_normalized") .withColumnRenamed("token", c), Seq(s"${c}_normalized"), "left")) .select(df.columns.map(col(_)): _*) def tokenizeSnapshot(columns: String*)(df: DataFrame) = { val newToken = row_number() over Window.orderBy(rand()) val tokens = fanoutOriginals(columns, df) .withColumn("token", newToken) replaceOriginalsWithTokens(columns, df, tokens) } val generic = spark.table("resellers").transform( tokenizeSnapshot("email", "name", "joindate", "city", "industry")) display(generic) ● protects from sequence attacks by randomizing token allocation within append microbatch ● good for a quick demonstration of concepts ● doesn't do the most important thing - persist token <-> value relationships in a vault ● generically applies tokenization to specified columns
- 24. import java.lang.Thread import java.util.ConcurrentModificationException import org.apache.spark.sql.expressions.Window def allocateNewTokens(columns: Seq[String], df: DataFrame): DataFrame = { val vault = df.sparkSession.table("token_vault") for (i <- 1 to 10) try { val startingToken = vault.agg( coalesce(max('token), lit(0))).first()(0) val newToken = lit(startingToken) + ( row_number() over Window.orderBy(rand())) fanoutOriginals(columns, df) .join(vault, Seq("k", "v"), "left") .where('token.isNull) .withColumn("token", newToken) .write.mode("append").format("delta") .saveAsTable("token_vault") return vault } catch { case e: ConcurrentModificationException if i < 10 => print("Retrying token allocation") } return vault } def tokenizeWithVault(columns: String*)(df: DataFrame) = replaceOriginalsWithTokens(columns, df, allocateNewTokens(columns, df)) ● The busiest place of data ingestion, so consider running OPTIMIZE token_vault ZORDER BY (v) to help with writes. ● Randomization is done on microbatch level, so we get shuffle only for new tokens, keeping implementation simpler ● token is assigned as long, populated with row_number() over random window. monotonically_increasing_id() is not used because it gives inaccurate results, as it's computed within Spark partition. UUID is not used because of consistency-related performance reasons Token Vault with Databricks Delta
- 25. GDPR with Vault GDPR without any vault
- 26. A.k.a. Removing outliers from data Anonymization
- 27. Synthetic data ▪ Usefulness: lower ▪ Difficulty: look at Synthetic Minority Oversampling Technique ▪ Schema: same ▪ Performance: not very usable for streaming. Requires ML fitting ▪ Re-identification: harder on the snapshot, though may drift for appendable data a.k.a. Adding random records, that do not look random
- 29. Column suppression ▪ Accuracy: medium value ▪ Difficulty: easy ▪ Schema: fewer columns ▪ Performance: less data ▪ Re-identification: be aware of outliers Is not always enough for both data scientists and those, who care about protecting the data, because few outliers may lead to identification, when joined with external sources CREATE OR REPLACE VIEW resellers_suppressed AS SELECT -- NOT INCLUDING COLUMNS: id, email, name, -- joindate, commission city, industry, leads_eur_90days, sales_eur_90days FROM resellers
- 30. Row suppression Recommended with either low frequency data Can still be attacked by joining with other datasets available
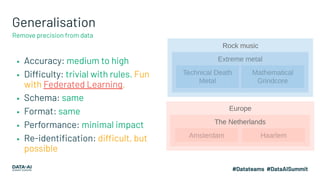
- 31. Generalisation ▪ Accuracy: medium to high ▪ Difficulty: trivial with rules. Fun with Federated Learning. ▪ Schema: same ▪ Format: same ▪ Performance: minimal impact ▪ Re-identification: difficult, but possible Remove precision from data
- 32. Binning APPROX_PERCENTILE is super performant and generic way to add contextual binning to any existing Spark DataFrame
- 33. Truncating: IP addresses ➔ Rounding IP address to /24 CIDR is considered anonymous enough, if other properties of a dataset allow. ➔ IP-geolocation (MaxMind, IP2Location) databases would generally represent it as city or neighbourhood level, where the real IP would represent a street.
- 34. Rounding Example rounding rules: ⟳ All numbers are rounded to the nearest multiple of 15 ⟳ Any number lower than 7.5 is rounded suppressed ⟳ Halves are always rounded upwards (e.g. 2.5 is rounded to 5)
- 35. Column, Row and Table level security on Databricks
- 36. Watermarking ▪ Accuracy: high on snapshot, makes no sense globally ▪ Difficulty: extreme ▪ Schema: almost same ▪ Format: different ▪ Performance: extreme overhead ▪ Re-identification: easy to identify who leaked the data Same as tokenization, but with token vaults on every select. Makes life of external Data Scientist hard. Data Lake Per-snapshot token vault Snapshot Physical Plan Rewrite Leak prevention data Data Theft Monitoring Data Science Live scoring
- 37. A.k.a. make life of the data scientist harder External controls
- 38. Auditing ▪ Difficulty: significant infrastructure investment ▪ Performance: data scientist required to track data scientists ▪ Track filters & usual access patterns track every action of data scientist everywhere
- 39. Remote desktop ▪ Accuracy: bulletproof ▪ Difficulty: make sure that data is accessible only through RDP ▪ Schema: n/a ▪ Performance: data scientists can see all the data they need ▪ Re-identification: depends And prevent copy-paste
- 40. Screenshot prevention ▪ Not COVID-19-friendly ▪ Physical desktop in the office connecting to remote desktop ▪ Motion sensors to detect phones lifting up to take a photo of the screen. It’s actually a real thing. ▪ Or simply prevent data scientists to bring phone, pen & paper to their workstation A.k.a. remote desktop, but even next level
- 41. Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.