Data Quality With or Without Apache Spark and Its Ecosystem
0 likes1,392 views

The document discusses the importance of data quality and various methodologies for ensuring it, particularly in relation to Apache Spark and its ecosystem. It highlights the need for data profiling, ETL quality checks, and various tools like Deequ and Great Expectations for managing data integrity. The text emphasizes that effective data management requires sophistication within organizations and may necessitate continued internal development of expertise.










![Deequ code
generation
from pydeequ.suggestions import *
suggestionResult = (
ConstraintSuggestionRunner(spark)
.onData(spark.table('demo'))
.addConstraintRule(DEFAULT())
.run())
print('from pydeequ.checks import *')
print('check = (Check(spark, CheckLevel.Warning, "Generated check")')
for suggestion in suggestionResult['constraint_suggestions']:
if 'Fractional' in suggestion['suggesting_rule']:
continue
print(f' {suggestion["code_for_constraint"]}')
print(')')
from pydeequ.checks import *
check = (Check(spark, CheckLevel.Warning,
"Generated check")
.isComplete("b")
.isNonNegative("b")
.isComplete("a")
.isNonNegative("a")
.isUnique("a")
.hasCompleteness("c", lambda x: x >= 0.32,
"It should be above 0.32!"))](https://image.slidesharecdn.com/237sergesmertin-210609002240/85/Data-Quality-With-or-Without-Apache-Spark-and-Its-Ecosystem-12-320.jpg)










Data Quality With or Without Apache Spark and Its Ecosystem
- 1. Data Quality with or without Apache Spark and its ecosystem Serge Smertin Sr. Resident Solutions Architect at Databricks
- 2. ▪ Intro ▪ Dimensions ▪ Frameworks ▪ TLDR ▪ Outro
- 3. About me ▪ Worked in all stages of data lifecycle for the past 14 years ▪ Built data science platforms from scratch ▪ Tracked cyber criminals through massively scaled data forensics ▪ Built anti-PII analysis measures for payments industry ▪ Bringing Databricks strategic customers to next level as full-time job now
- 4. Colleen Graham “Performance Management Driving BI Spending”, InformationWeek, February 14, 2006 https://www.informationweek.com/performance-management-driving-bi-spending/d/d-id/10405 52 Data quality requires certain level of sophistication within a company to even understand that it’s a problem.
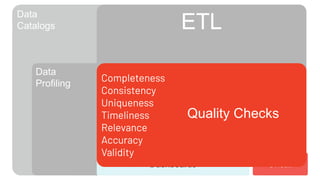
- 5. Data Catalogs Data Profiling ETL Quality Checks Metrics repository Alerting Noise filtering Dashboards Oncall
- 6. Data Catalogs Data Profiling ETL Metrics repository Alerting Noise filtering Dashboards Oncall Completeness Consistency Uniqueness Timeliness Relevance Accuracy Validity Quality Checks
- 7. Record level Database level - Stream-friendly - Quarantine invalid data - Debug and re-process - Make sure to (re-)watch “Make reliable ETL easy on Delta Lake” talk - Batch-friendly - See health of the entire pipeline - Detect processing anomalies - Reconciliation testing - Mutual information analysis - This talk
- 8. Data owners and Subject Matter Experts define ideal shape of the data May not fully cover all aspects, when number of datasets is bigger that SME team Often is the only way for larger orgs, where expertise still has to be developed internally May lead to incomplete data coverage and missed signals about problems in data pipelines Exploration Expertise Semi-supervised code generation based on data profiling results May overfit alerting with rules that are too strict by default, resulting in more noise than signal Automation
- 9. Few solutions exist in the open-source community either in the form of libraries or complete stand-alone platforms, which can be used to assure a certain data quality, especially when continuous imports happen.
- 10. “1” if check(s) succeeded for a given row. Result is averaged. Streaming friendly. Success Keys Check compares incoming batch with existing dataset - e.g. unique keys Domain Keys Materialised synthetic aggregations - e.g. is this batch |2σ| records different than previous? Dataset Metrics Repeat computation in a separate, simplified pipeline and validate results - e.g. double-entry bookkeeping Reconciliation Tests
- 11. If you “build your own everything” - consider embedding Deequ.It has has constraint suggestion among advanced enterprise features like data profiling and anomaly detection out of the box, though documentation is not that extensive. And you may want to fork it internally.
- 12. Deequ code generation from pydeequ.suggestions import * suggestionResult = ( ConstraintSuggestionRunner(spark) .onData(spark.table('demo')) .addConstraintRule(DEFAULT()) .run()) print('from pydeequ.checks import *') print('check = (Check(spark, CheckLevel.Warning, "Generated check")') for suggestion in suggestionResult['constraint_suggestions']: if 'Fractional' in suggestion['suggesting_rule']: continue print(f' {suggestion["code_for_constraint"]}') print(')') from pydeequ.checks import * check = (Check(spark, CheckLevel.Warning, "Generated check") .isComplete("b") .isNonNegative("b") .isComplete("a") .isNonNegative("a") .isUnique("a") .hasCompleteness("c", lambda x: x >= 0.32, "It should be above 0.32!"))
- 13. Great Expectations is less enterprise'y data validation platform written in Python, that focuses on supporting Apache Spark among other data sources, like Postgres, Pandas, BigQuery, and so on.
- 14. Pandas Profiling ▪ Exploratory Data Analysis simplified by generating HTML report ▪ Native bi-directional integration with Great Expectations ▪ great_expectations profile DATASOURCE ▪ (pandas_profiling .ProfileReport(pandas_df) .to_expectation_suite()) https://pandas-profiling.github.io/pandas-profiling/
- 15. Apache Griffin may be the most enterprise-oriented solution with user interface available, given the fact it being Apache top-level project and backed up by eBay since 2016, but it is not as easily embeddable into existing applications, because it requires standalone deployment along with JSON DSL definitions for rules.
- 17. Completeness SELECT AVG(IF(c IS NOT NULL, 1, 0)) AS isComplete FROM demo Deequ PySpark Great Expectations SQL
- 18. Uniqueness SELECT (COUNT(DISTINCT c) / COUNT(1)) AS isUnique FROM demo Deequ Great Expectations PySpark SQL
- 19. Validity SELECT AVG(IF(a < b, 1, 0)) AS isValid FROM demo Deequ Great Expectations PySpark SQL
- 20. Timeliness SELECT NOW() - MAX(rawEventTime) AS delay FROM processed_events raw events processed events
- 21. Honorable Mentions • https://github.com/FRosner/drunken-data-quality • https://github.com/databrickslabs/dataframe-rules-engine Make sure to (re-)watch “Make reliable ETL easy on Delta Lake” talk
- 22. Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.