Downloaded 24 times






























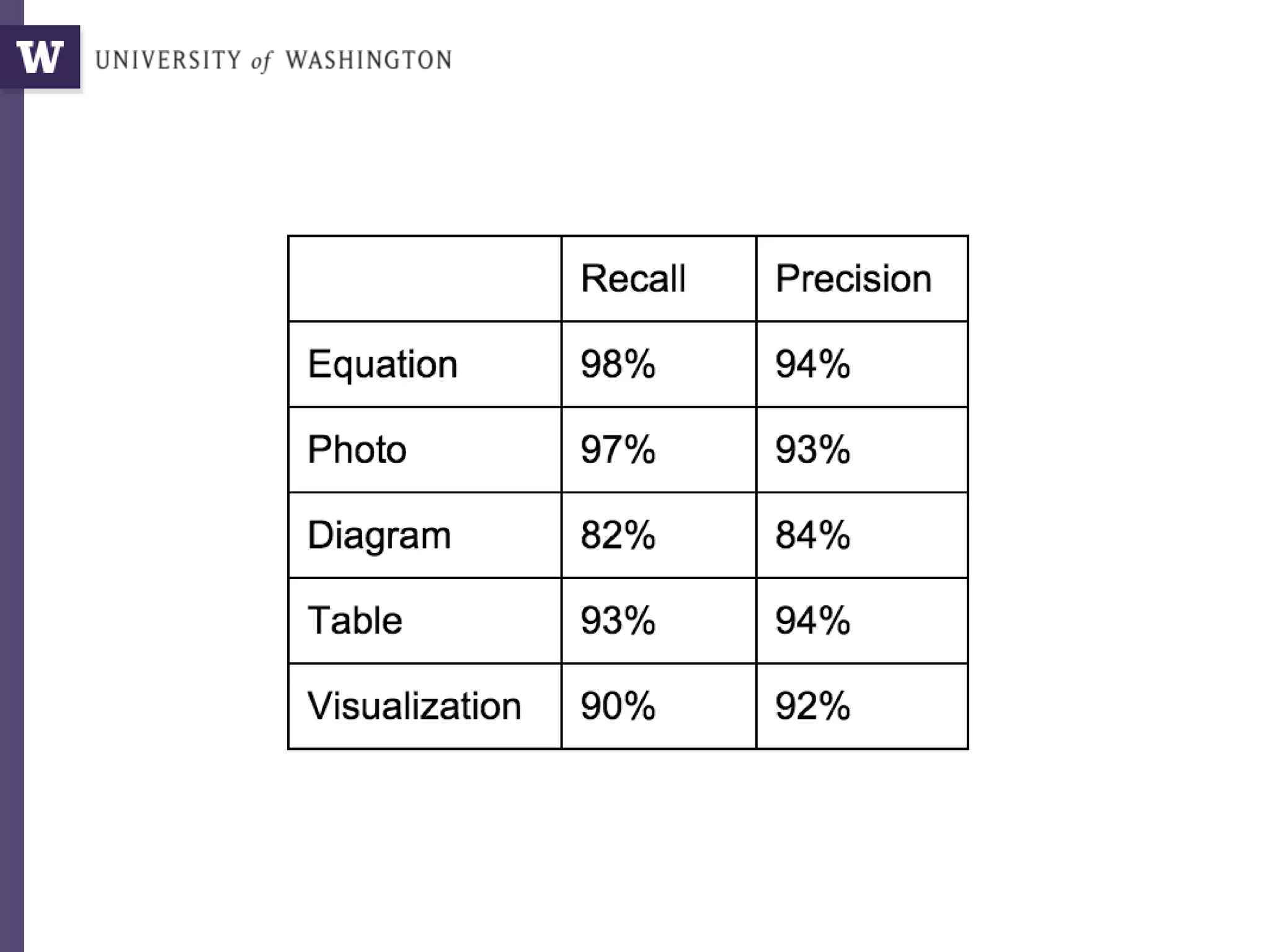






































The document discusses various aspects of data science, particularly focusing on human-data interaction, data curation, and the complexity of modern data ecosystems. It highlights the challenges faced by researchers in handling large amounts of data, emphasizing how data processing and curation can become bottlenecks in scientific workflows. Several projects, including SQLShare, Myria, and Viziometrics, are mentioned as efforts to optimize data usage and improve access to scientific information.























































































